- IOT, 클러스터, 파티션은 테이블 랜덤액세스 최소화에 매우 효과적인 구조
- BUT, 운영중인 환경에서 이를 적용하려면 성능검증을 위해 많은 테스트를 진행해야한다. > 시스템 개발 단계에서 물리설계가 중요한 이유
- 운영환경에서 가장 일반적인 튜닝 기법은 인덱스 컬럼 추가
1. 인덱스 탐색
-
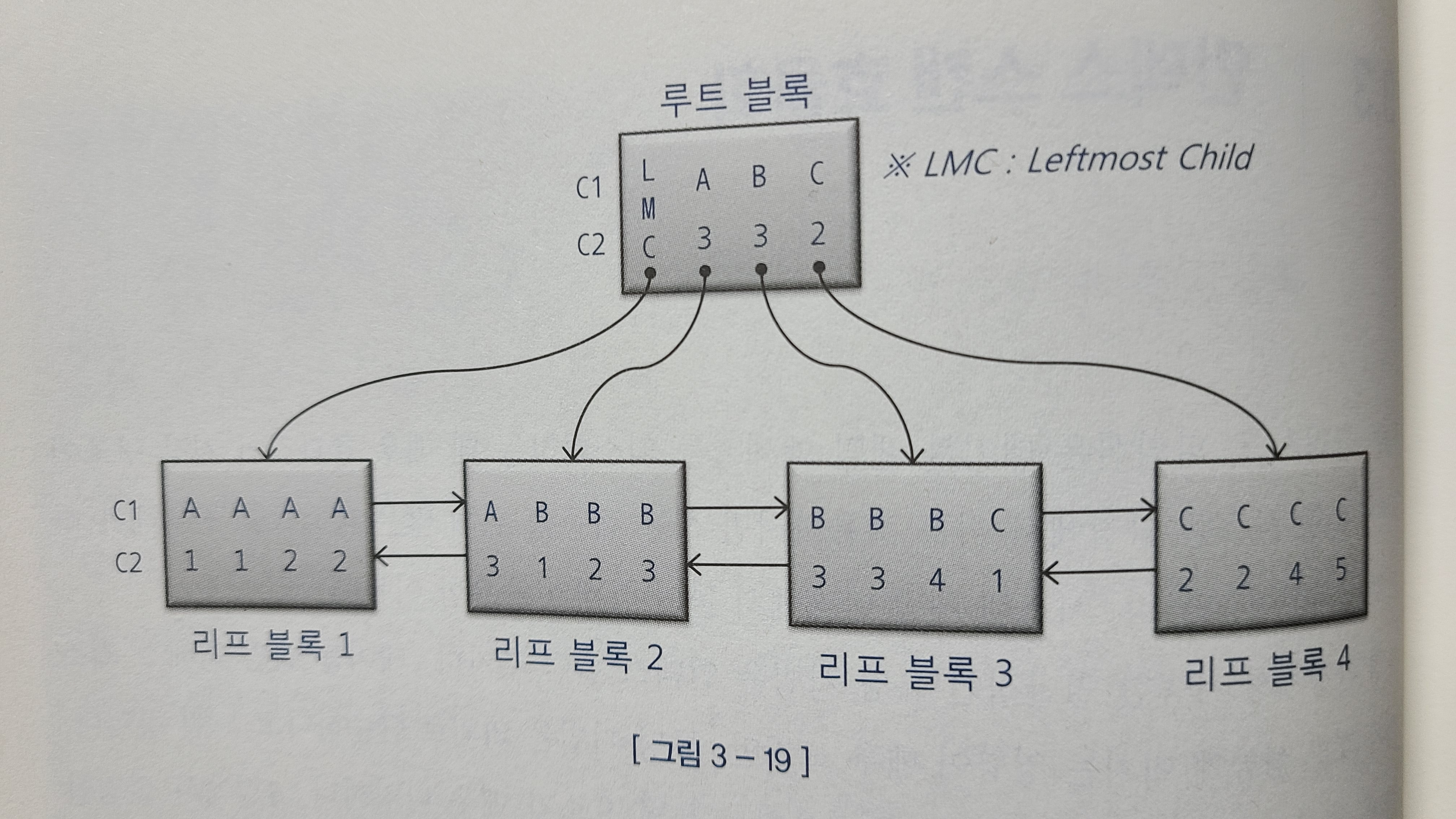
루트블록의 각 레코드는 하위 노드를 가르키는 블록 주소를 갖는다.
-
가르키는 주소로 찾아간 블록에는 자신의 키값보다 크거나 같은 값을 갖는 레코드가 저장돼 있음을 의미.
-
루트 블록에는 키값을 갖지 않는 특별한 레코드가있다
-
가장 왼쪽에 있는 LMC(Leftmost Child) 레코드다.
-
LMC는 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킨다.
-
LMC가 가르키는 주소로 찾아간 블록에는 '키 값을 가진 첫번째 레코드 보다 작거나 같은 값'을 갖는 레코드가 저장되어있다.
-
수직적 탐색은 스캔 시작점을 찾는 과정
-
조건별 탐색루트 상세설명은 책 175P참조
아래조건들에대해 어떻게 탐색을할지 추측해볼것--조건절1
WHERE C1='B'
--조건절2
WHERE C1='B'
AND C2 = 3
--조건절3
WHERE C1='B'
AND C2 >= 3
--조건절4
WHERE C1='B'
AND C2<=3
--조건절5
WHERE C1='B'
AND C2 BETWEEN 2 AND 3
--조건절6
WHERE C1 BETWEEN 'A' AND 'C'
AND C2 BETWEEN 2 AND 3
2. 인덱스 스캔 효율성
- 인덱스 선행컬럼이 조건절에 없거나 '='조건이 아니면 스캔과정에 비효율 발생
- 한컬럼으로 정렬된 데이터에서도 중간값을 비우고 검색하면 효율차이가 큼
EX) LIKE '성능검%' 과 LIKE '성능_선'의 차이 - 인덱스 선행컬럼이 조건절에 없을때와 있을때의 효율성 차이는크다
EX) 위의예제에서 4글자 1개씩쪼개어 4개컬럼의 복합인덱스로 구성해도 결과는 똑같다, 이유는 선행컬럼이 조건절에없기때문
C1 = '성'
C2 = '능'
C4 = '선'
인덱스 스캔 효율성 측정
- SQL 트레이스를 통해 쉽게 알 수 있다.

- 인덱스 스캔후 얻은 레코드가 10개인데
그과정에서 7463개블록(cr=7463)을 읽었다 - 인덱스 리프 블록에는 테이블 블록보다 훨씬더 많은 레코드가 담긴다.
- 한블록당 평균 500개 레코드가 담긴다 가정하면, 3,731,500(=7463*500)개 레코드를 읽은셈이다
- 그많은 데이터를 읽고 열 개를 얻었다니 이만저만한 비효율이 아니다.
3. 액세스 조건과 필터 조건
-
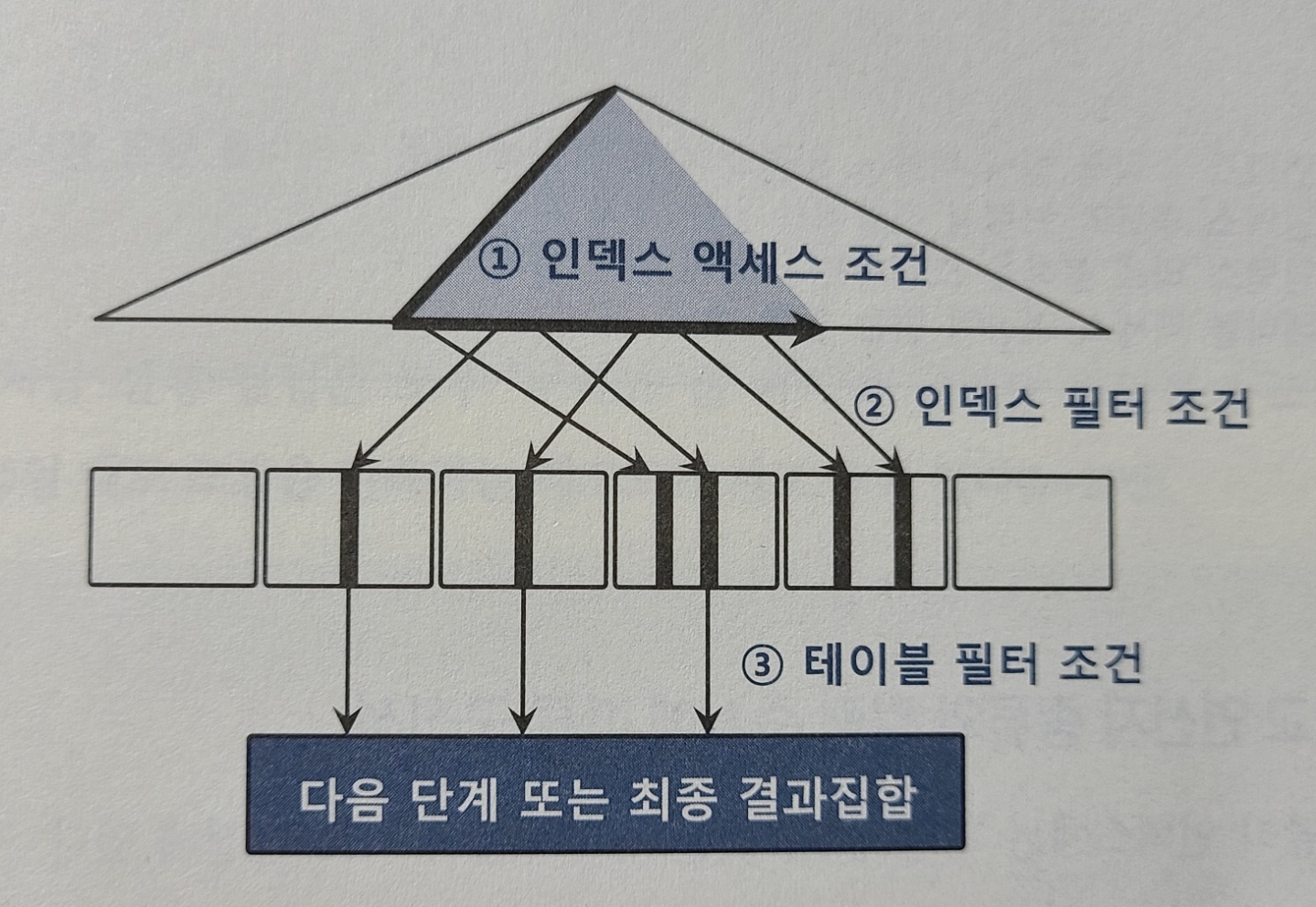
반드시 이해해야할 용어 두가지 '액세스조건' 과 '필터조건'
-
인덱스 액세스 조건 : 인덱스 스캔 범위를 결정하는 조건절, 인덱스 수직적 탐새을 통해 스캔 시작점을 결정하는데 영향, 인덱스 리프블록 스캔하다 어디서 멈출지 결정
-
인덱스 필터 조건 : 테이블로 액세스 할지결정하는 조건절
-
인덱스를 이용하든 테이블 full scan하든 테이블 액세스단계에서 처리되는 조건절은 모두 필터조건
-
테이블 필터조건 : 쿼리 수행 다음 단계로 전달하거나 최종 결과집합에 포함할지 결정
옵티마이저 비용 계산 원리
비용 = 인덱스 수직적 탐색 비용 + 인덱스 수평적 탐색 비용 + 테이블 랜덤 액세스 비용
= 인덱스 루트와 브랜치 레벨에서 읽히는 블록수 + 인덱스 리프블록을 스캔하는 과정에서 읽는 블록 수+ 테이블 액세스 과정에 읽는 블록 수
4. 비교연산자 종류와 컬럼 순서에 따른 군집성
- 테이블과 달리 인덱스에는 '같은 값'을 갖는 레코드들이 서로 군집해있다.
- 같은 값을 찾을때 '='연산자를 사용하므로 인덱스 컬럼을 앞쪽부터 누락없이 '=' 연산자로 조회하면 조건절을 만족하는 레코드는 모두 모여있다.
- 선행컬럼이 모두 '=' 조건인 상태에서 첫번째 나타나는 범위검색 조건까지만 만족하는 인덱스 레코드는 모두 연속해있지만, 그 이하조건까지 만족하는 레코드는 비교연산자 종류에 상관없이 흩어진다.(우연히 모여있을수는 있음) > 약간 skip scan형태가 됨.
5. 인덱스 선행 컬럼이 등치(=) 조건이 아닐때 생기는 비효율
- 인덱스 스캔 효율성은 인덱스 컬럼을 조건절에 모두 등치(=)조건으로 사용할때 가장 좋다.
- 인덱스 컬럼 중 일부가 조건절에 없거나 등치조건이 아니더라도, 그것이 뒤쪽 컬럼일때는 비효율이 없다.
- 인덱스를 [아파트시세코드+평형+평형타입+인터넷매물] 순으로 구성했을때 조건절이 아래와 같은경우를 말한다.
where 아파트시세코드 = :a
where 아파트시세코드 = :a and 평형 = :b
where 아파트시세코드 = :a and 평형 = :b and 평형타입 = :c
where 아파트시세코드 = :a and 평형 = :b and 평형타입 between :c and :d - 반면 인덱스 선행컬럼이 조건절에 없거나 부등호, BETWEEN, LIKE같은 범위검색 조건이면, 인덱스를 스캔하는 단계에서 비효율이 생긴다.
위와 같은 인덱스구성일때SELECT 해당층, 평단가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
FROM 매물아파트매매
WHERE 아파트시세코드 = 'A01011350900056'
AND 평형 ='59'
AND 평형타입 ='A'
AND 인터넷매물 BETWEEN '1' AND '3'
ORDER BY 입력일 - 선행컬럼(아파트 시세코드, 평형, 평형 타입)이 모두 등치조건이기때문에 전혀 비효율없이 조건을 만족하는 데이터를 찾을수있다.
- 인덱스 구성을 [인터넷매물+아파트시세코드+평형+평형타입]순으로 바꾼 후 같은 SQL을 수행하면
인덱스 스캔 범위가 넓어진다.
6. BETWEEN을 IN-List로 전환
- 범위검색 컬럼이 맨 뒤로 가도록 인덱스를 [아파트시세코드+평형+평형타입+인터넷매물] 순으로 변경하면 좋겠지만 운영 시스템에서 인덱스 구성을 바꾸기는 쉽지않다.
- 이럴때 BETWEEN 조건을 아래와 같이 IN-List로 바꿔주면 큰 효과를 얻는경우가있다.
- BETWEEN을 인터넷매물 IN ('1','2','3')으로 바꾸어 실행계획에서 INLIST ITERATOR 오퍼레이션 작동
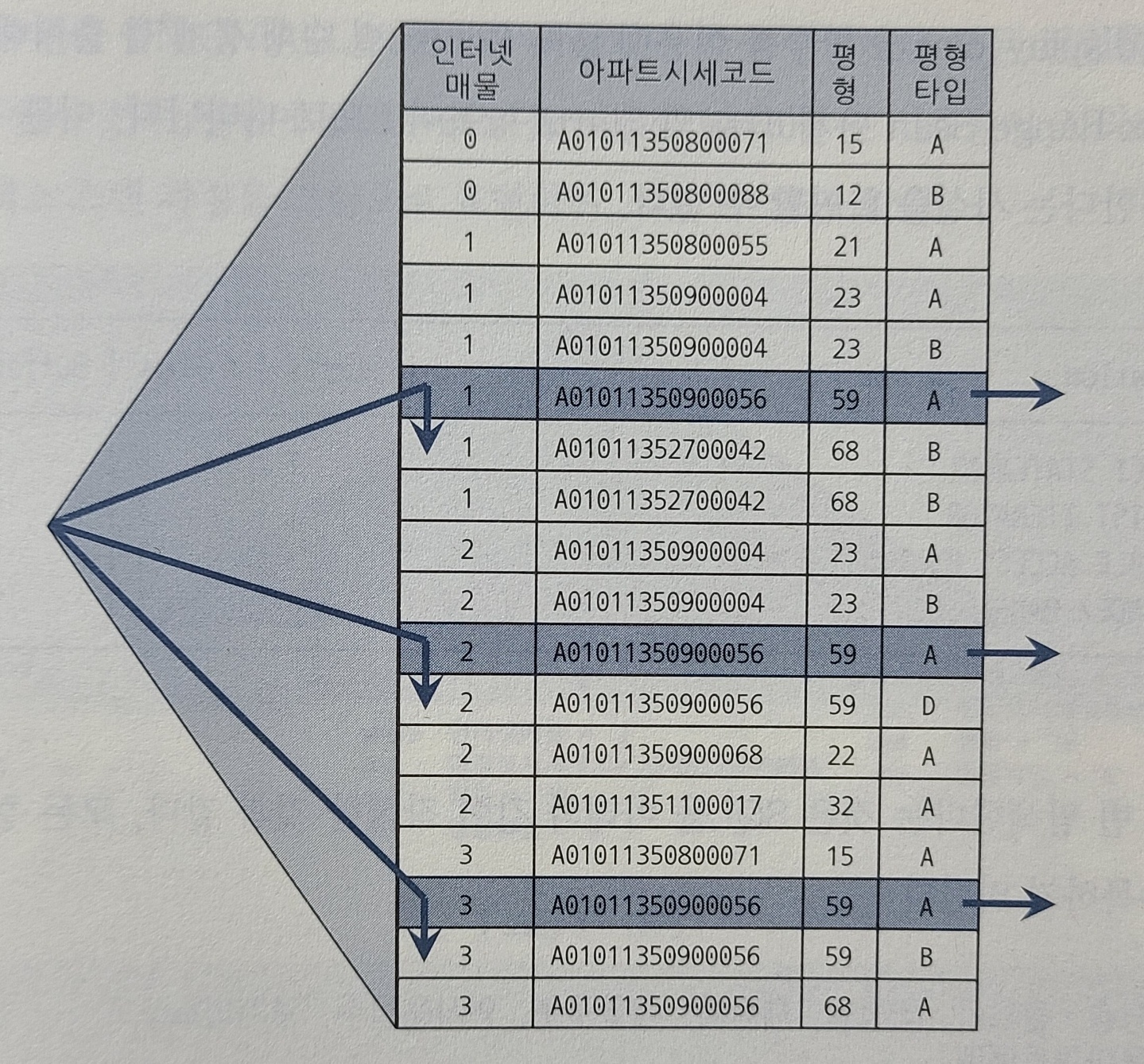
- 이런경우 INDEX RANGE SCAN단계에서 Start항목이 3으로 나타난다. 이를 통해 인덱스를 3번 탐색한다는 사실을 알 수 있다.
- 인덱스 3번 탐색한다는것은 SQL을 UNION ALL로 3번 실행한다는것(인터넷매물도 등치조건으로 바뀜)
- IN-List항목 개수가 늘어날 수 있다면 BETWEEN을 IN-List로 전환하는 방식은 사용하기 곤란
- 그럴경우 아래처럼 NL방식의 조인문이나 서브쿼리로 구현하면된다(IN-List값들을 코드테이블로 관리하고있을때)
SELECT /*+ ordered use_nl(b)*/ b.해당층, b.평단가, b.입력일,
b.해당동, b.매물구분, b.연사용일수, b.중개업소코드
FROM 통합코드 a, 매물아파트매매 b
WHERE a.코드구분 = 'CD064' --인터넷매물구분
AND a.코드 between '1' and '3'
and b.인터넷매물 = a.코드
AND b.아파트시세코드 = 'A01011350900056'
AND b.평형 ='59'
AND b.평형타입 ='A'
AND b.인터넷매물 BETWEEN '1' AND '3'
ORDER BY 입력일
BETWEEN조건을 IN-List로 전환할때주의 사항
- IN-List의 개수가 많지 않아야 한다는것.
- 많은경우 수직적 탐색이 많이 발생한다.
- 이런경우 BETWEEN조건때문에 리프블록을 많이 스캔하는 비효율보다, IN-List개수만큼 브랜치 블록을 반복탐색하는 비효율이 더클 수 있다. 루트에서 브랜치블록까지 Depth가 깊을때 특히그렇다.
- 인덱스 스캔 과정에서 서로 선택되는 레코드들이 서로멀리 떨어져있을때만 유용
- 수직이든, 수평이든 스캔을 적게하는쪽으로 선택!
- 고객등급간에 데이터가 많이떨어져있다면 IN-List 효율이 높을것으로 예상.
많이떨어져있지않다면(중간사이의 건수체크) 비효율where 고객등급 between 'C' AND 'D'
AND 고객번호 = 123
7. Index Skip Scan활용
- 선두컬럼이 BETWEEN조건일때, INDEX SKIP SCAN이 IN-LIST보다 오히려 낫다
- 선두컬럼이 BETWEEN이어서 나머지 검색 조건을 만족하는 데이터들이 멀리 떨어져있을때 효율적이다
8. IN조건은 '='인가
- IN조건은 '='이 아니다.
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :CUST_NO
AND 상품ID IN ('NH00037', 'NH00041', 'NH00050') - 고객별 가입상품 테이블에서 고객번호의 평균 카디널리티는 3이라고 가정
(고객별 평균 세건의 상품을 가입) - 인덱스를 [상품ID + 고객번호] 순으로 생성하면 같은상품은 고개번호순으로 정렬되고,
고객번호 기준으로는 같은고객번호가 상품ID에따라 뿔뿔이 흩어진상태.
예를들어 고객번호가 1234인 레코드가 상품ID에 따라 연속되지않은 세 개 리프블록에 저장 - 이런경우 상품ID조건절이 IN-List Iterator방식으로 풀리는게 효과적
- 상품id가 인덱스 선두컬럼인 상황에서 IN-List 방식으로 풀지않으면 상품ID는 필터조건이므로 테이블 전체 또는 인덱스 전체를 스캔하면서 필터링해야한다.
- IN조건은 '='이 아니다, '='이 되려면 IN-List Iterator방식으로 풀려야만한다
그렇지않으면, IN조건은 필터조건이다.
NUM_INDEX_KEYS힌트 활용
- 인덱스가 [고객번호 + 상품ID] 순으로 구성된 상황에서 고객번호만 인덱스 액세스 조건으로 사용하려면
아래와같이 힌트를 사용하면된다 - 세번째 인자 '1'은 첫번째 컬럼까지만 액세스조건으로 사용하라는 의미
- 상품 ID까지 인덱스 액세스조건으로 사용하려면 세번째 인자에 2를넣으면된다.
SELECT /*+ num_index_keys(a 고객별가입상품_X1 1) */
*
FROM 고객별가입상품 a
WHERE 고객번호 = :CUST_NO
AND 상품ID IN ('NH00037', 'NH00041', 'NH00050')
9. BETWEEN과 LIKE 스캔범위 비교
-
BETWEEN이 더정확한 표현식인데 LIKE를선호하는이유는 코딩이 편리하기때문
-
둘다 범위검색 조건으로, 범위검색조건 사용시 비효율 원리가 똑같이 적용.
-
데이터 분포와 조건절 값에 따라 인덱스 스캔량이 서로 다를수 있다.
-
결론은 LIKE보다 BETWEEN을 사용하는게 낫다.
-
인덱스 [판매월+판매구분]순으로 구성, 판매구분은 'A'와 'B'두개값이 존재, 90%, 10%의 비중차지
<조건절1>
WHERE 판매월 BETWEEN '201901' AND '201912'
AND 판매구분 ='B'<조건절2>
WHERE 판매월 LIKE '2019%'
AND 판매구분 ='B' -
조건절1은 판매월=201901, 판매구분=B인 첫번째레코드에서 스캔시작
-
조건절2는 판매월이 201901인 첫번째레코드에서 스캔 시작, 혹시라도201900이있을수있기때문에 판매구분 B부터 시작못함.
-
항상 스캔이 어떻게진행될지 머리속에 데이터구조를 그려라. 조회조건별 건수확인도 중요.
10. 범위검색조건을 남용할 때 생기는 비효율
- 인덱스 스캔 비효율이 발생
- 대량테이블의 넓은 범위로 검색할때 그영향이 매우 클 수 있다
11. 다양한 옵션 조건 처리 방식의 장단점 비교
OR 조건 활용
-
인덱스 선두컬럼에 대한 옵션조건에 OR조건을 사용해선 안된다.
-
인덱스 액세스 조건으로 사용불가
-
인덱스 필터 조건으로도 사용불가
-
테이블 필터 조건으로만 사용가능.
-
인덱스 구성 컬럼중 하나이상이 NOT NULL컬럼이면 18C부터 인덱스 필터조건으로 사용가능.
-
OR조건을 이용한 옵션 조건 처리는 가급적 사용하지 않아야 한다.
-
NULL허용컬럼이더라도 결과집합을 보장
LIKE/BETWEEN조건 활용
-
변별력이 좋은 필수 조건이 있는 상황에서 이들패턴사용은 나쁘지 않다.
-
필수조건 컬럼을 인덱스 선두에 두고 액세스 조건으로 사용하면, LIKE/BETWEEN이 인덱스 필터조건이어도 좋은성능을 낼 수 있다.
-
문제는 필수조건의 변별력이 좋지않을때(DISTINCT VALUE가 많을때)는 FULL SCAN이 유리할수있다.
-
LIKE/BETWEEN 패턴사용할때 점검해야할 4가지(BETWEEN은 1,2번)
- 인덱스 선두 컬럼
- NULL허용 컬럼 (NULL허용 컬럼이있는경우 결과집합을 보장하지 않는다.)
고객ID LIKE '%' -- 전체가 조회되어야하나 NULL컬럼은 제외된다.
- 숫자형 컬럼 : 자동으로 형변환이 발생하므로 필터조건으로 바뀌게됨.
- 가변길이 컬럼
WHERE 고객명 LIKE :CUST_NM || '%' -- 김훈을넣으면 김훈과 김훈남등이 같이조회된다.
UNION ALL 활용(서로다른 인덱스 사용)
-
:CUST_ID변수에 값을 입력했는지에 따라 위아래 SQL중 하나만 실행되게 하는 방식
-
:CUST_ID변수에 값을 입력하든 안하든 인덱스를 최적으로 사용.(서로다른 인덱스사용)
SELECT FROM 거래
WHERE :CUST_ID IS NULL
AND 거래일자 BETWEEN :DT1 AND :DT2
UNION ALL
SELECT FROM 거래
WHERE :CUST_ID IS NOT NULL
AND 고객ID = :CUST_ID
AND 거래일자 BETWEEN :DT1 AND :DT2NVL/DECODE함수 활용
-
UNION ALL보다 단순하면서 UNION ALL과 같은 성능을 낸다.
-
단점은 LIKE패턴처럼 NULL허용 컬럼에 사용할 수없다. 값이 NULL인 레코드가 결과집합에서 누락
SELECT * FROM DUAL WHERE NULL = NULL; 이 조회결과가없다는뜻-- 고객ID가있고없을때 사용하는 INDEX가 다름
SELECT * FROM 거래
WHERE 고객ID = NVL(:CUST_ID, 고객ID)
AND 거래일자 BETWEEN :DT1 AND :DT2SELECT * FROM 거래
WHERE 고객ID = DECODE(:CUST_ID, NULL, 고객ID, :CUST_ID)
AND 거래일자 BETWEEN :DT1 AND :DT2
12. 함수호출부하 해소를 위한 인덱스 구성
PL/SQL함수의 성능적 특성
- 사용자 정의함수는 개발자들생각보다 매우느리다.
- 한두번호출시에는 성능차이를 잘 느끼지못한다
- PL/SQL 사용자 정의 함수가 느린 3가지 이유
- 가상머신(VM)상에서 실행되는 인터프리터 언어
- 호출시마다 컨텍스트 스위칭 발생
- 내장SQL에 대한 Recursive Call발생
- PL/SQL로 작성한 함수와 프로시저를 컴파일하면 JAVA언어처럼 바이트코드를 생성해 데이터 딕셔너리에 젖아하며, 이를 해석할 수 있는 PL/SQL엔진(가상머신)만 있으면 어디서든 실행할 수 있다.
- PL/SQL도 JAVA처럼 인터프리터 언어이기 때문에 Native코드로 완전 컴파일된 내장(Built-in)함수에 비해 많이 느리다.
- PL/SQL함수는 실행시 매번 SQL실행엔진과 PL/SQL가상머신 사이에 컨텍스트 스위칭이 일어난다.
- 아래쿼리에서 조건만족하는 회원이 100만명이면 GET ADDR도 100만번실행, 함수안에 SQL이 내장되어잇으면 그 SQL도 100만번 실행된다. Recursive Call부하가 가장 큰 성능문제이다
select 회원번호, 회원명, 생년, 생월일, GET_ADDR(우편번호)
FROM 회원
WHERE 생월일 LIKE '01%' - 위 SQL에 PL/SQL함수를 쓰지않고 아래와 같이 조인문으처리하면 성능차이가 매우크다,
SELECT A.회원번호, A.회원명, A.생년, A.생월일
, (SELECT b.시도 || ' ' || b.구군 || ' ' || b.읍면동
from 기본주소 b
where b.우편번호 = a.우편번호
and b.순번 =1) 기본주소
from 회원 a
where a.생월일 like '01%'
효율적 인덱스 구성을 통한 함수호출 최소화
- 조회된 건수만큼 함수나프로시저가 실행되므로 인덱스구성을효율적으로하여 실행회수를 줄인다.
