SQL BOOSTER
1.GROUP BY와 ROLLUP
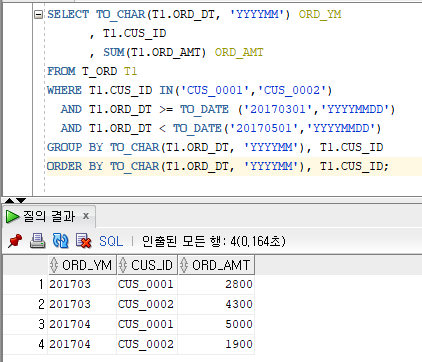
중복제거 (SELECT 의 DISTINCT와 같음)집계기능주요 집계함수 : SUM(합계), COUNT(건수), MIN(최소값), MAX(최대값) 집계함수는 GROUP BY없이 단독사용가능CASE는 GROUP BY절 ORDER BY절에도사용가능하다.CASE
2.JOIN

가장 기본이되는 조인JOIN은 항상 1:1로 이루어진다 > 여러테이블이 있어도 순차적 으로 진행됨접근순서나 처리순서는 조인결과에 영향을 주징낳는다.1:1, 1:M, M:M이 발생할수있으면 M:M은대게 잘못된 설계나 조인이다.기준데이터 집합과 참조데이터 집합 기준데이터
3.유용한 SQL문법

서브쿼리가 무조건 성능이 나쁜것은 아니다, 때에따라 더좋은 성능을 낼때도 있다.SELECT절의 단독 서브쿼리 (스칼라 서브쿼리)메인 SQL의값과 상관없이 불러오는형태똑같은 테이블의 데이터를 여러번 스칼라형태로 구성하는것보다 인랑린뷰로 구성하여 가져오는것이 성능에 유리하
4.성능 개선을 위한 기본 지식

좌변은 절대 가공하지말라, 컬럼을 가공하면 인덱스를 사용못한다는 뜻인데 원리를 파악해야함NL조인에서 크기가 작은 집합이 선행집합이면 일반적으로 효율이 좋지만 페이징SQL에서는 꼭 그렇지 않다페이징 기준이 크기가 큰 테이블쪽에있다면 선행집합으로 큰테이블 선택하는것이 NL
5.INDEX 개요

인덱스의 물리적 구조 이해복잡한 SQL분석만들어진 인덱스가 어떻게 사용될지 예측하는 능력테이블 내 데이터 속성을 파악하는 능력JOIN의 내부적인 처리방법(NL, MERGE, HASH)의 이해테이블내 데이터를 찾을수있게 일부 데이터를 모아서 구성한 데이터 구조인덱스를 이
6.단일인덱스 & 복합인덱스
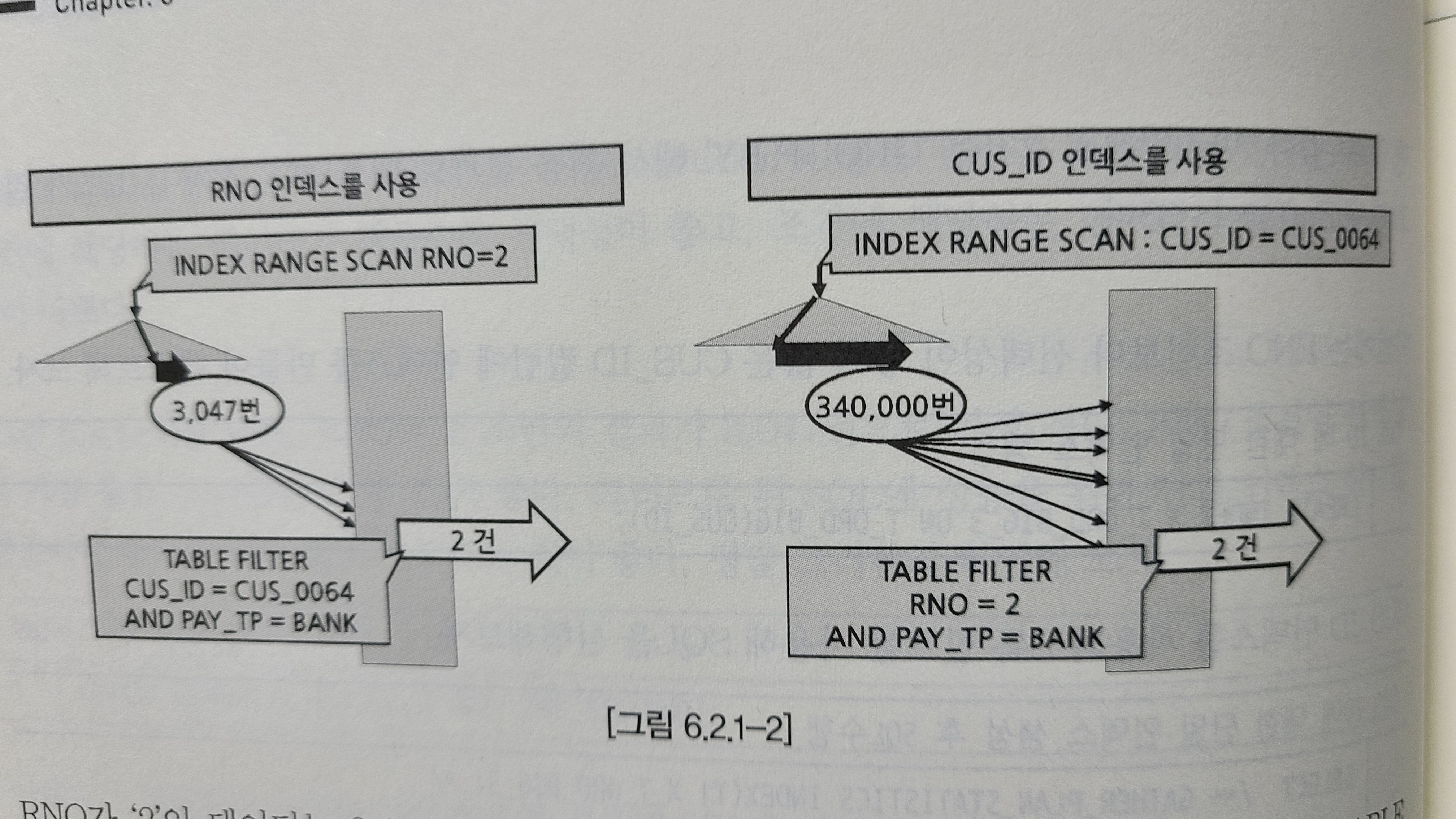
특정테이블에 컬럼별 조건에따른 결과건수CUS_ID : 340,000PAY_TP : 9,150,000RNO : 3,047인덱스 컬럼 선정 규칙중하나는 선택성이 좋은컬럼을 사용하는것. 데이터가적을수록 선택성이 좋음. 데이터가많을수록 선택성이 나쁘다.RNO컬럼을 인덱스로 생
7.JOIN과 성능

조인방법 : 이너조인, 아우터 조인, 카테시안 조인NESTED LOOPS JOINMERGE JOINHASH JOIN3가지 방식과 조인방법을 혼합하여 사용가능간단하게 NL조인이라 부른다.중첩 반복문형태 (중첩 FOR문)USE_NL힌트사용NL후행테이블의 인덱스는 매우중요,
8.OLTP기술 (트랜잭션,LOCK)
1. 트랜잭션 반드시 한번에 처리되어야 하는 논리적 작업단위 (EX. 은행 계좌 이체 처리등) COMMIT은 트랜잭션중 변경된 데이터를 모두반영하고 종료 ROLLBACK은 트랜잭션중 진행된 작업을 모두 취소하고 종료. SQL문장에서 에러가나도 에러발생한 문장만
9.OLTP기술(문서번호 처리기술, 시퀀스와 ROWNUM)
개발시 자주 만나게 되는것중 하나가 키값 부여, ID나문서 번호를 부여하는것을 채번이라한다PO1001 등과같은 키값은 PO를 잘라내고 1001을 증가하여 채번, 이런 방식을 SELECT~MAX방식이라고한다.SELECT MAX방식은 여러명이 사용할 경우 잠재적 오류와 성
10.분석함수

다양한 분석을 손쉽게 구현할 수 있게해준다보통 OVER절과 함께사용하며 PARTITIONBY ORDER BY 라는 기능을 제공GROUP BY와함께쓰는 집계함수와 비슷해보이지만 실제로는 다른 기능집계함수보다 좀더 다양한 분석이 가능분석함수중 집계함수와 명칭이 같은 COU
11.분석함수 대체, 페이징
서브쿼리, 인라인뷰, 셀프조인을 활용하면 분석함수를 대신할 수 있다.하나의 SQL을 다양한 방법으로 구현해보는것은 기술향상에 큰 도움이 된다.분석함수가 성능면에서는 가장 유리할수 있다.서브쿼리로 대신하기 : 스칼라서브쿼리로 동일테이블 참조하여 합계 구하기인라인뷰로 대신
12.SQL 개발 가이드
WHERE절에서 사용하는 컬럼은 왠만해선 변형하지 않는다. 인덱스를 사용할 수 없기때문이다.EX) SUBSTR(T1.ORD_YMD, 1, 6) = '201703' 보다는(INDEX FAST FULL SCAN) T1.ORD_YMD LIKE '201703%'이 훨씬