분석함수
- 다양한 분석을 손쉽게 구현할 수 있게해준다
- 보통 OVER절과 함께사용하며 PARTITIONBY ORDER BY 라는 기능을 제공
- GROUP BY와함께쓰는 집계함수와 비슷해보이지만 실제로는 다른 기능
- 집계함수보다 좀더 다양한 분석이 가능
1. OVER절
1.1 OVER절 이해하기
- 분석함수중 집계함수와 명칭이 같은 COUNT, SUM, MIN, MAX
명칭과 기능이 같지만 분석수행대상이 다르다. - 집계함수에는 없는 RANK, LAG, LEAD
- OVER 기본개념
- 분석함수의 분석대상을 정하는 역할
- 대부분의 분석함수는 OVER절과 같이 사용한다
- OVER()와 같이 괄호 안에 아무런 옵션도 주지 않으면 조회된 결과 전체가 분석대상
- 전체주문건수 확인을위한 분석함수
COUNT(*) OVER() AS ALL_CNT
1.2 분석 대상
- 분석대상의 이해를 위해 SELECT SQL이 처리되는 기본개념과정 확인
- FROM절 : 대상테이블 선택
- WHERE절(생략가능) : 1번의 대상 중에 조회할 데이터를 선택(조인도 수행)
- GROUP BY(생략가능 : 2번까지 수행결과 그룹화
- HAVING절(생략가능) : 3번까지 수행결과중 최종 조회데이터 선택
- 분석대상의 개념
- 분석함수는 분석대상에 대해 수행된다.
- 분석 대상이란 분석함수를 제외한 SQL의 결과다
- OVER() 안에 아무런 옵션을 정의하지 않으면 조회된SQL 결과 전체가 분석대상이다
- GROUP BY가 포함된 SQL에서 분석함수 사용할 경우 GROUP BY명시된컬럼 또는 집계함수를 사용한 결과에만 분석함수를 사용할 수있다
> 안그럴경우 에러남
1.3 OVER-PARTITION BY
- PARTITION BY T1.CUS_ID : 해당로우의 CUS_ID값과 같은 값을 가진 로우들을 분석대상으로 한다.
- 여러컬럼을 지정할 수도 있고, 하나의SELECT절에서 분석함수별로 다르게 지정할 수도 있다.
1.4 OVER-ORDER BY
- 조회된결과를 정렬하는 문장.
- 각 로우별로 ORDER BY에 따라 분석대상이 다르게 정해진다. 누적합계등을 구할 때 유용
- 정렬해서 현재까지의 ROW를 대상으로 분석
- 월별 누적주문금액을 구하는 분석함수
SUM(SUM(T1.ORD_AMT)) OVER(ORDER BY TO_CHAR(T1.ORD_DT,'YYYYMM'))

- 고객별 주문금액 합계
SUM(SUM(T1.ORD_AMT)) OVER(PARTITION BY T1.CUS_ID) AS BY_CUS_AMT
- 고객별 월별누계 합계
SUM(SUM(T1.ORD_AMT)) OVER(PARTITION BY T1.CUS_ID
ORDER BY TO_CHAR(T1.ORD_DT,'YYYYMM')) BY_CUS_ORD_YM_SUM - ORDER BY에는 ROWS나 RANGE옵션을 추가로 사용해 분석대상을 세밀하게 지정가능
2. 기타 분석함수
2.1 순위 분석함수
- RANK와 DENSE_RANK분석함수는 순위를 구할때사용
- RANK 중복순위 허용하며, 중복만큼 더해져서 다음순위 나옴 EX)1,2,2,4
- DENSE_RANK 중복순위허용하며, 순차적으로 다음순위 나옴 EX)1,2,2,3
2.2 ROW_NUMBER
- 줄번호를 부여하는 함수, 중복된 순위를 내보내지 않는다.
- PARTITION BY, ORDER BY를 사용해 세밀한 줄 번호를 부여할 수 있다.
- ROW_NUMBER는 ROWNUM을 대체하는 기능은아니다
- 대체로 ROWNUM이 ROW_NUMBER보다 성능면에서 유리
- ROWNUM으로 처리가능하다면 굳이 ROW_NUMBER사용하지 않는것이 좋다.
- 월별로 주문금액 TOP3고객 구하기
ROW_NUMBER() OVER(PARTITION BY TO_CHAR(T1.ORD_DT, 'YYYYMM') ORDER BY SUM(T1.ORD_AMT) DESC) BY_YM_RANK
- GROUP BY 는 CUS_ID로되어있는상태
2.3 LAG, LEAD
- LAG 는 자신의 이전값, LEAD는 자신의 이후값을 가져오는 분석함수
- 자신보다 몇건 이전이나 이후의 값을 가져올지 결정할 수 있다.
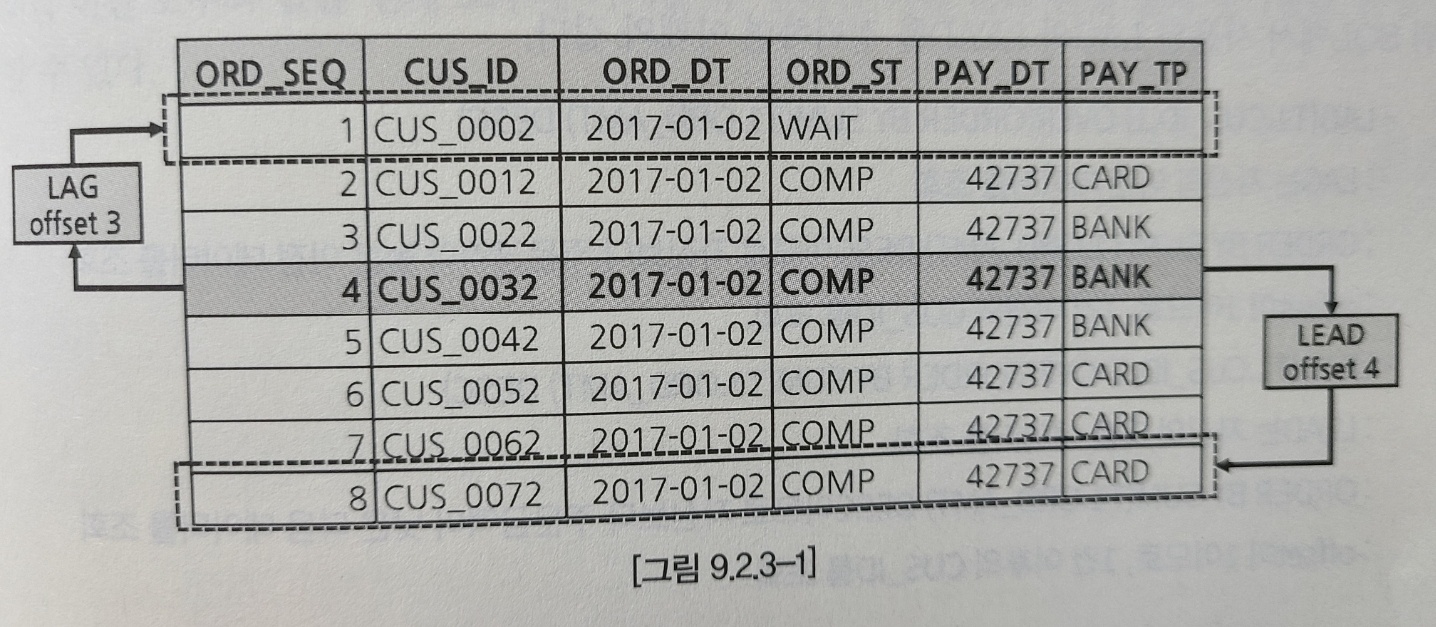
- 사용법
- LAG(컬럼명, offset) OVER([PARTITION BY ~] ORDER BY~)
- LEAD(컬럼명, offset) OVER([PARTITION BY ~] ORDER BY~)
- offset:현재 로우에서 몇 로우 이전또는 몇 로우 이후를 뜻한다.
- 내림차순, 오름차순에따라 가져오는 데이터가 달라지니 주의가 필요
- 사용예제
- 자신보다 주문금액이 높은 이전데이터 조회
LAG(T1.CUS_ID, 1) OVER(ORDER BY SUM(T1.ORD_AMT) DESC) LAG_1 - 자신보다 주문금액이 낮은 다음 데이터를 조회(DESC이기때문)
LEAD(T1.CUS_ID, 1) OVER(ORDER BY SUM(T1.ORD_AMT) DESC) LEAD_1
- 자신보다 주문금액이 높은 이전데이터 조회

늙어가면서 기억을 남기는 개발자