1. 테이블 액세스 최소화
- 튜닝은 랜덤I/O와의 전쟁, SQL튜닝에 있어 랜덤 I/O가 그만큼 중요.
- 본장에서는 랜덤액세스 최소화하는 구체적인 방법들을 소개
1.1 테이블 랜덤 액세스
-
아무리 데이터가많아도 인덱스를 사용하면 데이터가 금방 조회됨(소량의 데이터 조회 시)
-
대량의 데이터를 조회할때 인덱스를 사용하면 테이블 전체 스캔할때보다 훨씬 느리다.
-
인덱스 ROWID는 물리적 주소? 논리적 주소?
- 물리적주소 : 데이터파일 번호, 오브젝트번호, 블록번호등의 조합으로 구성
- 논리적 주소 : 테이블 레코드를 찾아가기 위한 논리적 주소정보를 담고있음
- ROWID는 논리적 주소이며, 디스크상의 테이블 레코드를 찾아가기위한 위치정보를 담는다
(프로그래밍의) 포인터가 아니며, 물리적으로 직접 연결된 구조는 더더욱 아니다.
-
메인메모리 DB(MMDB)와 비교
- 데이터를 모두 메모리에 로드해놓고 메모리를 통해서만 I/O를 수행하는 DB
- 잘튜닝된 OLTP성 DBMS는 버퍼캐시 히트율이 99%이상. 그런데도 메인메모리 DB만큼 빠르지않다
- 특히 대량데이터를 인덱스로 액세스할때는 엄청난 차이가 난다.
- MMDB의 인덱스는 디스크상 주소정보가 아닌 메모리상 주소정보(포인터)이기에 액세스 비용이 매우낮다
- 오라클은 테이블 블록이 수시로 버퍼캐시에서 밀려났다가 캐싱되며, 그때마다 다른공간에 캐싱되기때문에 인덱스에서 포인터로 직접연결할 수 없는구조.
- 메모리 주소정보(포인터)가 아닌 디스크 주소정보를 이용해 해시 알고리즘으로 버퍼 블록을 찾아간다.
-
I/O메커니즘 복습
- DBA(데이터파일번호+블록번호)는 디스크상에서 블록을 찾기위한 주소정보.
- 매번 디스크에서 블록을 읽을수 없기에 I/O성능 향상을 위해 버퍼캐시를 활용해야한다.
- 데이터를찾을때는 항상 버퍼캐시부터 찾아본다.
- 해싱알고리즘으로 버퍼 헤더찾고 - 거기서 얻은 포인터로 버퍼블록을 찾아간다.
- FULL SCAN할때는 익스텐트 맵을 통해 읽을 블록들의 DBA정보를 얻는다.
- 인덱스ROWID는 포인터가아니다, 디스크상 테이블레코드 찾기위한 논리적 주소정보.
ROWID가 가리키는 테이블 블록을 버퍼캐시에서 먼저 찾아보고, 못찾을때만 디스크블록에서 읽는다.(버퍼캐시에 적재한 후 읽는다.) - 모든 데이터가 캐싱되있어도 테이블 레코드를 찾기위해 매번 DBA해싱과 래치획득과정을 반복해야한다.
- 동시액세스가 심할때는 캐시버퍼 체인 래치와 버퍼Lock에대한 경합까지발생.
- ROWID를 이용한 테이블 액세스는 생각보다 고비용구조.
-
인덱스 ROWID는 우편주소
- 디스크 DB(오라클등의 일반 DBMS)가 사용하는 ROWID를 우편주소
메인메모리 DB가 사용하는 포인터를 전화번호에 비유할 수 있다. - 전화통신은 물리적으로 연결된 통신망을 이용하므로 전화번호를 누르면 곧바로 통화할 수있다.
우편 통신은 봉투에 적힌대로 우체부 아저씨가 일일이 찾아다니는 구조이므로 전화와비교할수없이 느리다.
- 디스크 DB(오라클등의 일반 DBMS)가 사용하는 ROWID를 우편주소
1.2 인덱스 클러스터링 팩터
- 특정 컬럼(인덱스)를 기준으로 같은 값을 갖는 데이터가 테이블상에 서로 모여있는 정도를 의미
- CF가 좋은 컬럼에 생성한 인덱스는 검색효율이 매우 좋다.
EX) 거주지역 = '제주' 에 해당하는 데이터가 물리적으로 근접해있으면 흩어져있을때보다 서칭속도가 빠르다.
분가한 자녀가 모두 한동네 모여살면 CF가좋기때문에 부모가 자녀들 집을 모두 방문하는데 하루면족하다.
전국각지에 흩어져살면 몇일이걸린다. - CF가좋은 컬럼에 생성한 인덱스 검색효율이 좋다는것은 테이블 액세스량에 비해 블록I/O가 적게발생함을 의미
- 버퍼피닝 때문, ROWID로 테이블을 액세스할때 오라클은 래치획득과 해시체인스캔 과정을 거쳐 어렵게 찾아간 테이블 블록에 대한 포인터(메모리 주소값)를 바로 해제하지않고 일단 유지한다 > 버퍼Pinning
- CF가 안좋은 인덱스 사용시 테이블 액세스하는 횟수만큼 블록I/O가 발생
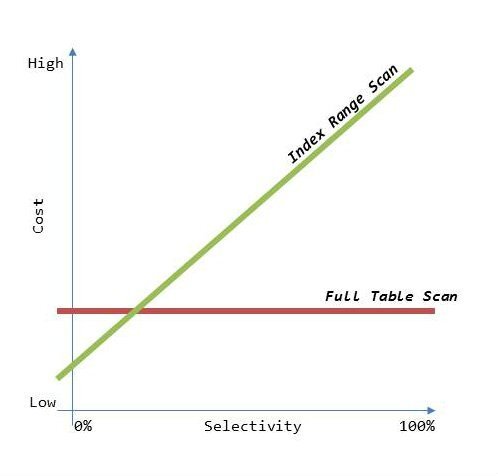
1.3 인덱스 손익분기점
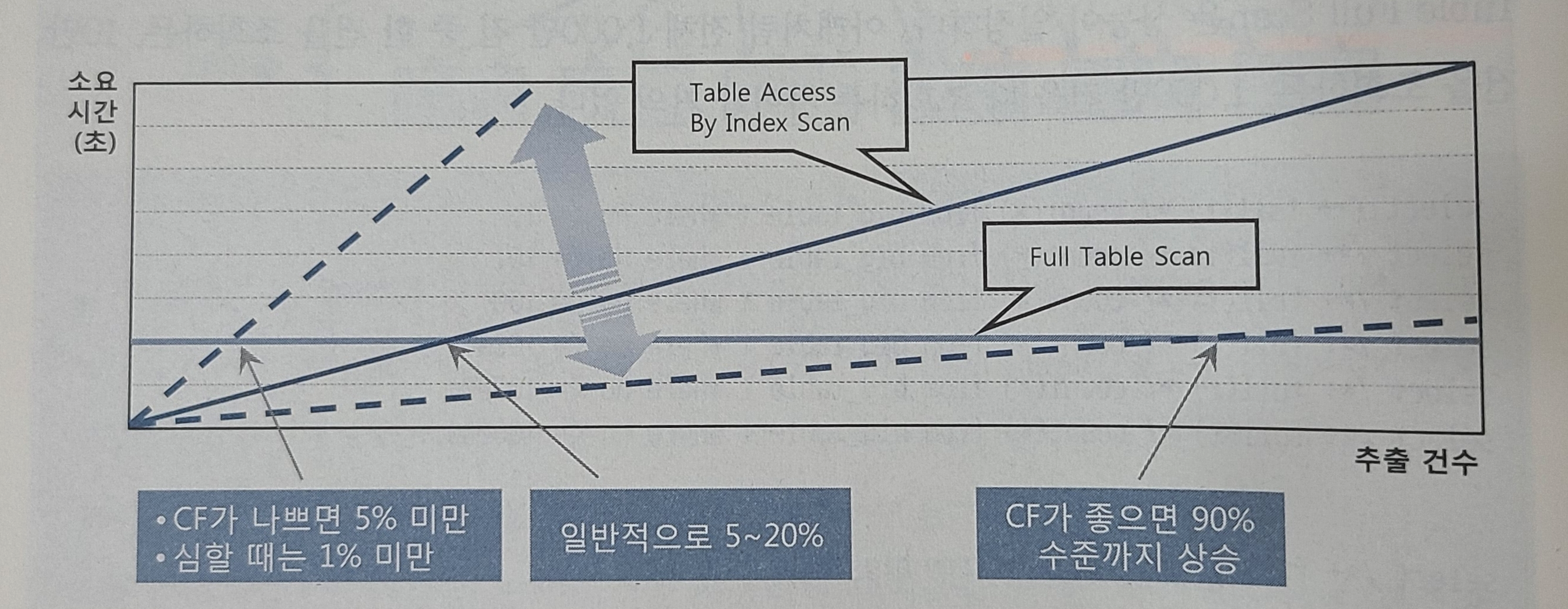
- 인덱스 ROWID를 이용한 테이블 액세스는 생각보다 고비용구조
- 읽어야할 데이터가 일정량을 넘는순간 FULL SCAN 보다 느려진다.
- INDEX RANGE SCAN에 의한 테이블 액세스가 TABLE FULL SCAN보다 느려지는 지점을 인덱스 손익분기점이라고한다.
- TABLE FULL SCAN은 조회건수에 상관없이 성능이 일정.
- INDEX이용시 전체데이터중 몇건을 추출하느냐에 따라 성능이 크게 달라진다(추출건수가 많을수록 느려짐)
- 손익분기점은 일반적으로 5~20%의 낮은 수준에서 결정, CF에따라 크게 달라짐.
- 테이블 전체 건수에따라 비율이달라짐 EX) 100만건의 10%와 1000만건의 10%는 다름.
- 온라인 프로그램 튜닝 VS 배치 프로그램 튜닝
- OLTP는 보통 소량 데이터를 읽고 갱신하여 인덱스를 효율적으로 사용하는것이 매우 중요
- 조인도 대부분 NL조인 사용(INDEX를 활용한 조인)
- 인덱스를 이용해 소트연상을 생략함으로써 부분처리방식으로 구현하면 아주빠른속도를 구현할수있다.
- 대용량 데이터 배치 프로그램은 항상 전체범위 처리기준으로 튜닝해야 한다.
- 일부를 빠르게 처리하는것이아니라 전체를 빠르게 처리하는것을 목표
- 대량데이터를 빠르게처리하려면 FULL SCAN과 해시조인이 유리
- 대용량에서 인덱스보 FULL SCAN이 효과적이지만 초 대용량테이블을 FULL SCAN시에는 시스템에 주는 부담도 적지않다
- 따라서 배치 프로그램에서는 파티션 활용전략이 매우 중요한 튜닝 요소이고, 병렬처리까지할 수 있으면 금상첨화다.
- 성능측면에서만 보면 테이블을 파티셔닝하는 이유는 결국 FULL SCAN을 빠르게 처리하기 위해서
- 모든 성능문제를 인덱스로 해결하려해선안된다. 인덱스는 다양한 튜닝도구중 하나이며, 큰테이블에서 아주적은 일부데이터를 빨리 찾고자할때 주로 사용
1.4 인덱스 컬럼 추가
-
테이블 액세스 최소화를 위해 가장 일반적으로 사용하는 튜닝기법, 인덱스 컬럼추가
-
무작정 인덱스를 추가할수없기에 기존 INDEX에 적절하게 컬럼을 추가한다면 성능향상을 도모할 수 있다.
-- 블록 I/O 266968건 실제 ROW 1909건, 사용여부 FILTER에서 대부분걸러짐
SELECT *
FROM 로밍렌탈
WHERE 서비스번호 LIKE '010%'
AND 사용여부 ='Y'
-- 사용여부 컬럼을 인덱스에 추가하면 블록I/O가 획기적으로 줄어듬.
1.5 인덱스만 읽고 처리
- 테이블랜덤엑세스가 많아더 필터조건에 의해 버려지는 레코드(ROW)가 없다면 거기에 비효율은 없다.
- 비효율이 없어도 테이블 액세스가 많다면, 사용하는 모든 컬럼을 인덱스에 추가해서 테이블 액세스가 아예 발생하지 않는 방법을 고려해 볼 수 있다.
- 인덱스만 읽어서 처리하는 쿼리를 COVERED 쿼리라고부르며 그 쿼리에 사용한 인덱스를 'Covered 인덱스' 라고 부른다.
- 이렇게 테이블 액세스를 제거하는 순간, 성능은 획기적으로 좋아진다.
- 사용컬럼이 적을때 활용해볼수있는 방법
- Include 인덱스.
- SQL SERVER 2005에 추가된 기능
- 인덱스 키외 미리지정한 컬럼을 리프레벨에 함께저장
- 인덱스 생성시 INCLUDE옵션을 지정하면된다
- 컬럼은 최대 1023개까지 지정
- 단순히 테이블 랜덤액세스를 줄이는 용도
1.6 인덱스 구조 테이블
- 인덱스를 이용한 테이블 액세스가 고비용 구조이니 랜덤엑세스가 아예 발생하지 않도록 테이블을 인덱스구조로 생성하면 어떠한가
- 오라클의 IOT(Index-Organized Table)라고 부른다. MSSQL SERVER'클러스터형 인덱스'
- 테이블을 찾아가기 위하 ROWID를 갖는 일반 인덱스와달리 IOT는 그자리에 테이블 데이터를 갖는다.
- 테이블블록에있어야할 데이터를 인덱스 리프블록에 모두 저장
- IOT에서는 인덱스 리프블록이 곧 데이터 블록
- 인위적으로 클러스터링 팩터를 좋게만드는 방법
1.7 클러스터 테이블 ***
- 인덱스 클러스터 테이블
- 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는구조
- 한블록에 모두 담을수 없을때는 새로운 블록을 할당해 클러스터 체인으로 연결
- 클러스터를 생성해야 인덱스 클러스터 테이블을 구성할 수 있다
- 클러스터인덱스를 스캔하면서 값을 찾을때는 랜덤액세스가 값 하나당 한번씩발생 > 클러스터에 도달해서는 시퀀셜 방식으로 스캔하기때문에 넓은범위를 읽어도 비효율이 없다.
- 해시 클러스터 테이블
- 인덱스를 사용하지않고 해시알고리즘을 사용해 클러스터를 찾아간다.
2. 부분범위 처리 활용
- 랜덤액세스로 인한 인덱스 손익분기점을 극복할 히든카드.
2.1 부분범위처리
- DBMS가 데이터전송할때 일정량씩 나누어 전송
- 전체 결과집합중 아직 전송하지않은 분량이있어도 서버프로세스는 클라이언트가 추가 Fetch Call을 받기전까지 그대로 기다린다.
- OLTP환경에서 1억건짜리 테이블 조회에도 빠르게 조회되는 이유는 DBMS가 일정량(ARRAY SIZE)를 전송하고 멈추기때문.
- 데이터 전송하고나면 서버 프로세스는 CPU를 OS에 반환하고 대기 큐에서 잔다.
다음 Fetch Call을받으면 대기큐에서 나와 그다음 데이터 전송 - 정렬조건이 있을때 부분범위 처리 : 정렬컬럼이 선두인 인덱스가 있으면 효율 좋음
- ARRAY SIZE조정을 통한 FETCH CALL최소화
- 대량데이터를 파일로내려받는다면 어차피 데이터모두전송해야하므로 크게설정.
- 앞쪽일부만 FETCH하다 멈추는 프로그램이라면 ARRAY SIZE를 작게 설정하는것이 유리(불필요하게 많은 데이터를 전송하고 버리는 비효율을 줄일 수 있기 때문)
2.2 부분범위 처리 구현
- 자바의 setFetchSize 옵션을 통해 한번에 가져올 데이터 갯수 설정
2.3 OLTP 환경에서 부분범위 처리에 의한 성능 개선 원리
- OLTP는 일반적으로 소량 데이터를 읽고 갱신
BUT, 항상 소량데이터만 조회하는것은 아니다. - 인덱스와 부분범위 처리를 잘 활용하면 OLTP환경에서 극적인 성능개선 효과를 얻을 수 있다.
- 멈출 수 있어야 의미있는 부분범위 처리
- 문제는 앞쪽일부만 출력하고 멈출수있는가
- 토드, 오렌지등의 쿼리툴은 DB서버 직접접근하는 2-Tier환경이라 부분범위 처리가능
- n-Tier(WAS, AP서버등이 존재하는) 아키텍쳐에서는 클라이언트가 특정 DB커넥션을 독점할 수 없다.
단위작업을 마치면 DB커넥션을 바로 커넥션풀에 반환해야하므로 그전에 SQL조회결과를 클라이언트에 모두 전송하고 커서를 닫아야 한다.
n-Tier환경에서의 부분범위 처리는 5장에서 설명
배치 I/O
- 디스크 랜덤 I/O성능을 높이려고 오라클에서 개선한 기능
- 읽는 블록마다 건건이 I/O CALL을 발생시키는 비효율을 줄이기 위해 고안한 기능
- 인덱스를 통해 테이블 액세스하다가 버퍼캐시에서 블록을 찾지못하면 일반적으로 디스크블록을 바로읽는데,
배치 I/O가 작동하면 디스크 I/O CALL을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리- 리프 블록의ROWID로 버퍼캐시를 조회하고(SINGLE BLOCK I/O) 실패한 ROWID저장
- 실패한ROWID가 일정량 모이면 블록번호로 정렬하여 물리 읽기를 수행 (MULTIBLOCK I/O)
- 11g에서는 NL조인 INNER쪽 테이블 액세스할 때만 작동했지만, 12c부터는 인덱스 ROWID로 테이블을 액세스하는 어떤 부분에서든 이기능이 작동할 수 있다.
- 테이블 정렬이슈
- 배치 I/O기능이 작동하면 인덱스를 이용해 출력하는 데이터 정렬순서가 매번 다를수있다.
- BATCHED가 실행계획에 붙으면 SORT ORDER BY 오퍼레이션도추가된다.
- 소트 생략가능한 인덱스를 사용하더라도 배치 I/O기능이 작동하면 데이터 순서를 보장할 수 없기때문에 정렬연산 발생하도록 옵티마이저가 선택
- no_batch_table_access_by_rowid : 배치 I/O기능을 사용하지않는 힌트
- batch_table_access_by_rowid : 배치 I/O 유도 힌트
- 정렬순서 보장을위해 no_batch~힌트를 써도되지만 ORDER BY를 추가하는것이 바람직하다.
- 정렬을 위해 ORDER BY 키워드 사용은 필수!!!

늙어가면서 기억을 남기는 개발자