1. 인덱스로 테이블 액세스 최적화
1-1 인덱스로 테이블 랜덤액세스
- 인덱스는 데이터를 찾기위해 ROWID가짐
- ROWID정보중에는 해당데이터가 어느블록에있는지 블록정보가있음.
- 이 블록이 현재 메모리(DB 버퍼 캐시)에 로드되어있는지 찾아보고 메모리에없으면 디스그에가서 해당블록을 메모리로 적재
- 이과정은 생각보다 큰 비용을 소모
- 메모리에 있으면 바로접근가능 한지 체크, 다른프로세스가 사용중이라면 잠시 대기상태로빠짐
- 대기상태에서 다시사용가능한지 체크하고, 사용가능하다면 트랜잭션에 의해 락이걸려있는지 또체크, 락에 걸려있으면 다시 대기
- 찾는블록이 메모리에 없으면 바로디스크가는게아니라 메모리내 프리버퍼를 찾는다.
- 이때빈공간이없으면 커밋한블록중 디스크에 쓰지못한블록(더티버퍼)을 디스크쓰기명령 내리고
- 빈공간이 나올때까지 기다리게되며 빈공간이 생기면 해당 공간에 디스크에서 찾은 블록을 적재
- 데이터가 저장된 블록을 가져오기위해 오라클은 생각보다 많은 작업을 해야한다.
1-2 인덱스 손익분기점
- 인덱스를 거쳐 테이블로이동할때, 인덱스에 저장된 순서대로 데이터를 찾아감
- 이때 인덱스에 저장된 데이터가 가리키는 블록위치가 연속성을 가지게되면 처음 블록을 방문한후 두번째 데이터부터 위의 복잡한 과정을 생략(버퍼 피닝 효과).
- 어렵게획득한 블록을 바로반환하지않고, 해당블록에 머물러 두번째 데이터를 읽는다.
- 클러스터링 팩터 : 각인덱스별 데이터가 블록내에 모여있는 정도.
통계정보 생성시 클러스터링 팩터를 SQL로 조회가능 - 클러스터링 팩터로 테이블을 평가할순없고, 특정 인덱스 이용시 해당인덱스의 클러스터링 팩터가 좋은지 나쁜지는 말할수 있다.
- 클러스터링팩터가 블록수에 가까우면 좋은것이고, 로우수에 가까우면 나쁜것으로 해석
클러스터링 팩터조회 SQL
SELECT T.TABLE_NAME, I.INDEX_NAME, T.BLOCKS, T.NUM_ROWS, I.CLUSTERING_FACTOR
FROM USER_TABLES T, USER_INDEXES I
WHERE I.TABLE_NAME = T.TABLE_NAME
AND T.TABLE_NAME IN ('ORD_ITEM', 'ORD_ITEM_RANDOM')
2. 인덱스 튜닝 사례
-
Starts : 각오퍼레이션 단계별 실행 횟수
E-Rows : 옵티마이저가 예상한 Rows
A-Rows : 각 오퍼레이션 단계에서 읽거나 갱신한 로우 수
A-times : 각 오퍼레이션 단계별 소요시간
Buffers : 캐시에서 읽은 버퍼 블록 수
Reads : 디스크에서 읽은 블록수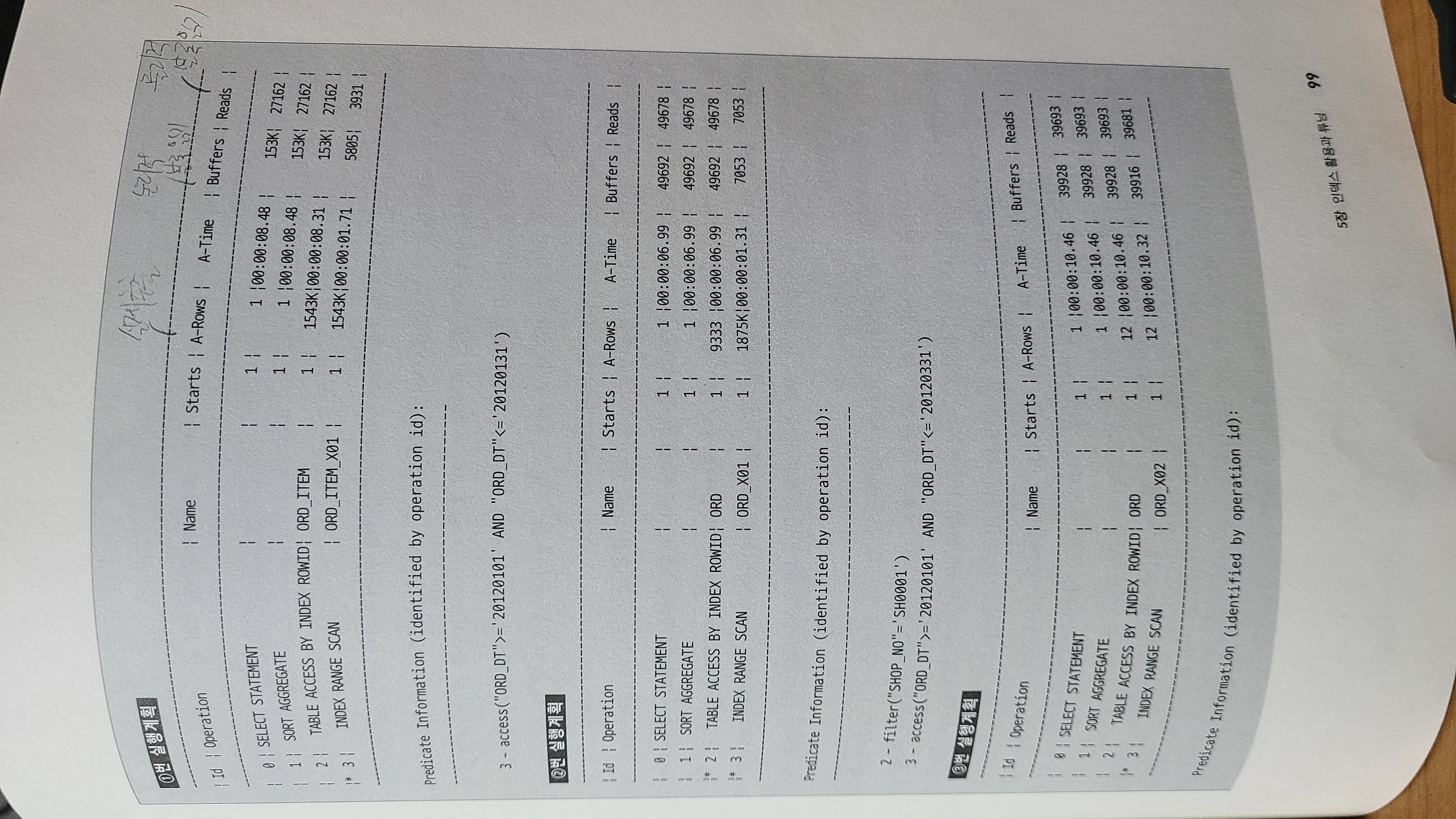
1번 실행계획
-
인덱스블록을 5805블록만큼 접근해 인덱스에서 약 154만 3000건의 데이터를 추출하고
테이블로 약 154만 3000번을 방문 -
Predicate Information에서 access로 표시되었으므로 대략하나의 인덱스 블록에
약 265로우(1,543,000/5805)를 저장했다고 볼 수 있음. -
꽤 많은 수의 데이터를 반환했지만 인덱스 읽는과정에서는 효율적이라 볼수있음
-
인덱스 스캔 후 테이블로 방문하여 최종결과로 집계되는 결과가 약 154만 3000건으로 인덱스를 통한 테이블로의 방문에는 비효율이 없음.
2번 실행계획
-
인덱스블록을 7053블록 접근해 인덱스에서 약 187만 5000건 추출하고 테이블로 187만5000번 방문
-
최종결과 집계건수가 9333건으로 약 186만번 이상의 방문이 불필요 > 비효율
-
Predicate Information에서 2번항목에 SHOP_NO='SH0001'조건을 필터처리
-
테이블엑세스에서 필터의 의미는 테이블에 187만5000번방문하면서 SHOP_NO='SH0001'조건을 확인하였다는 뜻.
-
기존인덱스에 SHOP_NO를 인덱스컬럼으로 추가하면 개선효과
3번 실행계획
-
인덱스 블록 3만9916블록 접근해 인덱스에서 12건데이터 추출 > 비효율
3. 인덱스 스캔 범위 계산
3-1 조건절에 따른 인덱스 스캔 범위 파악
- 인덱스가 A,B,C,D컬럼이고
- WHERE A = :a AND B = :b AND C BETWEEN :c1 AND :c2 AND D = :d
- 위와같을때 A,B,C컬럼은 원하는 구간을 찾아가지만 D는 A,B,C를 만족하는 모든 인덱스를 스캔하고 마지막에 결과 집합에 해당되는지만 체크하는 필터값으로 사용함.
- SELECT *
FROM 상품
WHERE 상품명 = '불고기버거'
AND 상품구분코드 BETWEEN '100100' AND '100101'
- 인덱스1(상품구분코드+상품명), 인덱스2(상품명+상품구분코드)
두개의 인덱스중 1은 상품구분코드범위를 먼저스캔한후 상품명을 필터로사용,
인덱스2는 등치(=) 조건이 있어 삼품명을 인덱스시작지점으로 찾은후 상품구분코드를 찾는다
=> 인덱스 비효율이 없다.
- 아래사진은 설명과 유사한케이스, ORD_X02와 ORD_X03의 실제 조회건수(A-Rows)는 동일하지만, 블록접근횟수(Buffers)는 큰차이가있는것을 볼수있다. 인덱스 스캔범위계산이 중요하다는것을 알 수 있다.
4. 인덱스 설계
- 범위 조건 이후에 등장하는 컬럼은 인덱스 필터로 동작하기때문에 효율이 떨어짐.
- 인덱스는 절대적인답이없다, 시스템 특징에 맞게 전략을 만들어가야한다.
4-1 인덱스 설계 기준 및 전략
- 등치(=)조건으로 사용되고 자주사용되는 컬럼을 앞쪽으로 만든다
- 등치(=)조건으로 사용되고 값의수 (Distinct Value)가 적은컬럼을 앞쪽으로 만든다
- 자주 사용되는 컬럼을 선정한다.
- 테이블 랜덤 엑세스를 줄인다.
- 정렬을 대신한다.
