1. NL조인
- NL조인은 두테이블 조인시 드라이빙테이블(OUTER)에서 읽은 결과를 INNER테이블로 건건이 조인을 시도하는 방식. 프로그래밍의 중첩포문형태.
- NL조인은 랜덤엑세스 방식이라 비효율적으로 보이지만 한건씩 처리하기때문에 처리중간에 멈추는경우(대용량 테이블에서 페이징 처리) 에서 만큼은 적절한 인덱스만 있다면 극정인 속도개선여지가있음.
- 최선의 인덱스 구성 : 수행빈도가 높은 SQL위주, 조금의 비효율이라도 개선해야한다면 전용인덱스 고려
- 아래 예문만을 위한 최적의 인덱스는 필터조건인 SALE_YN을 각각 추가하는것이 최적이다.
ITEM > ITEM_TYPE_CD + SALE_YN
UITEM > ITEM_ID + SALE_YN
(SALE_YN으로 걸러지는 데이터가 많을수록 인덱스 효과가 높음) - NL조인의 동작 순서
인덱스는 ITEM > ITEM_TYPE_CD
UITEM > ITEM_ID + UITEM_IDSELECT /*+ ORDERED USE_NL(B) */ --B와 조인할때 NL조인사용
*
FROM ITEM A
, UITEM B
WHERE A.ITEM_ID = B.ITEM_ID --1
AND A.ITEM_TYPE_CD = '100100' --2
AND A.SALE_YN = 'Y' --3
AND B.SALE_YN = 'Y' --4 - 위 쿼리에서 드라이빙 테이블은 A, INNER TABLE은 B 이고, 2>3>1>4순으로 실행됨
- 드라이빙테이블에서 인덱스로 대상 추출 > 2
- 드라이빙테이블에서 SALE_YN조건으로 필터 >3
- 추출된 드라이빙테이블 데이터에서 순차적으로 순환하면서 INNER TABLE 접근 > 1
- INNER TABLE접근 후 SALE_YN조건으로 필터 > 4
2. 소트머지 조인
- 두테이블을 각각 조건에 맞게 먼저 읽은후 두테이블을 조인컬럼기준으로 정렬해놓고 조인을 수행
- 조건에 맞는 두테이블 데이터를 만든후 조인 시도
- 나머지과정은 NL조인과 유사
- 오라클에서는 정렬을 PGA에서 수행, PGA공간은 프로세스에 할당된 독립된 공간으로 버퍼캐시(SGA)를 사용하는 NL조인에 비해 조인을 시도하는 데이터 접근이 더 빠름
- 완전한 중첩for문형태를 띄는 NL조인과비교하여 소트머지는 조금다른 로직을가지고있음.
- 첫번째 시도후 두번재시도는 첫번째시도만큼 조인시도를 하지않는다.
- 각 테이블을 한번씩만 읽어 1차로 데이터를 추출/정렬하여 조인키로 정렬했으므로 조인 횟수를 줄일 수 있는기법.... (조인키가 중복이 생길경우에는 driving Table의 두번째부터는 누락이발생하는것아닌가?)
- 조인으로 인한 랜덤엑세스 부하는 없다고 볼수있음.
각각의 데이터 추출 하여 조인
begin_point = 0;
for(i=0;i<I_MAX;i++)
{
for(j=begin_point;j<J_MAX;j++)
{
while(d.dept_no=e.deptno)
{
begin_point = j +1
}
break; //조인서칭후 루프탈출
}
} - 소트머지 조인의 where절 동작 순서
인덱스는 ITEM > ITEM_TYPE_CD
UITEM > 없음 - 동작 순서 : 2 > 3 > 4 >1
A의 데이터 추출(2,3) 및 조인컬럼(ITEM_ID기준) 정렬 > B의데이터 추출(4) 및 조인컬럼(ITEM_ID기준) 정렬 > PGA에 적재된 테이블간 JOIN(1)
-위 예문만을 위한 최적의 인덱스SELECT /*+ ORDERED USE_MERGE(B) */ -- B와조인할때 소트머지사용
*
FROM ITEM A
, UITEM B
WHERE A.ITEM_ID = B.ITEM_ID --1
AND A.ITEM_TYPE_CD = '100100' --2
AND A.SALE_YN = 'Y' --3
AND B.SALE_YN = 'Y' --4
소트머지는 조인키기준정렬이 필요한데 이를대신할 인덱스가있으면 정렬부하를 줄일수있음
ITEM > ITEM_TYPE_CD + SALE_YN + ITEM_ID (조인컬럼 정렬이 필요하므로)
UITEM > SALE_YN + ITEM_ID
(SALE_YN으로 걸러지는 데이터가 많을수록 인덱스 효과가 높음) - 소트머지조인은 해시 조인의 등장으로 자주사용되지않음, 조인을위해 조인과직접적 관련이없는 정렬작업이 있기때문
3. 해시 조인
3.1 해시 알고리즘
-
해시맵을 만들때, 해시 버킷을 생성하고 해시함수를 통해 반환된 값으로 해시 버킷을 찾아가 해시 체인을 구성
-
해시버킷 : 해시 배열의 대표값을 포함한 해시 저장소라고생각하면될듯..
-
해시함수가 f(x) = mod(x, 10) 이라고할때, 어떤값(정수)이 입력되든 변환될수 있는 값은 0~9까지 이므로 해시 버킷은 총 10개가 만들어짐.
-
0~99까지 숫자가 입력된다 가정하면 아래와 같은 해시맵을 만듬, 좌측 숫자집합은 위에서 아래로, 좌에서 우순서로 입력된다고 가정
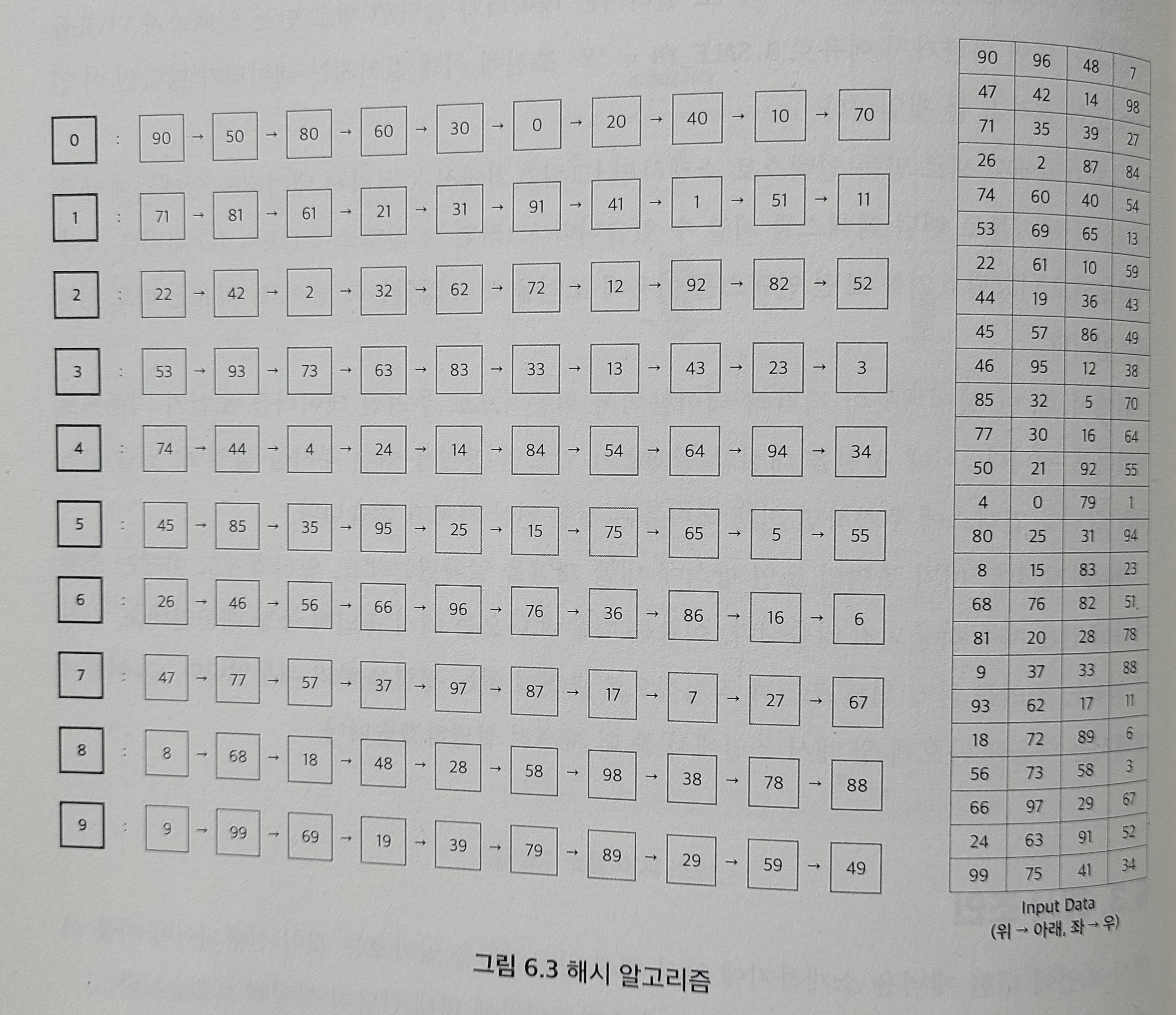
-
그림에서 좌측굵은 0~9숫자는 해시버킷(대표값?) 오른쪽숫자집합이 입력될때, 해시함수의 반환값을 받아 해당되는 해시버킷의 해시체인으로 연결(버킷옆의 화살표로이어진 체인들)
3.2 해시 조인
-
오라클에서 해시 조인을 위해 해시 맵을 만들때 두 테이블중 작은 테이블을 읽어 만듬.
-
큰테이블을 읽어 해시함수를 통해 해시 버킷을 찾아가 실제 데이터를 찾음
-
작은테이블(Build Input), 큰테이블 (Probe Input)
-
해시 맵은 해시 함수를 사용해 해시 함수가 반환하는값으로 해시 버킷을 찾아 해시 체인에 연결하면서 만드. 해시맵에서 찾을때도 마찬가지, 해시함수가 반환하는 값으로 버킷을 찾고, 버킷에 할당된 체인을 검색하면서 해당 데이터를 찾아감.
-
아래 그림에서 B테이블(Build Input)을 읽어 해시 함수를 통해 해시 맵을 만들고, A테이블(Probe Input)을 읽어 나가면서 85값을 해시함수에 대입해 찾아가야할 버킷을 확인(버킷 5번), 버킷에 연결된 해시체인을 검색해 얻은 85를 찾아 조인.
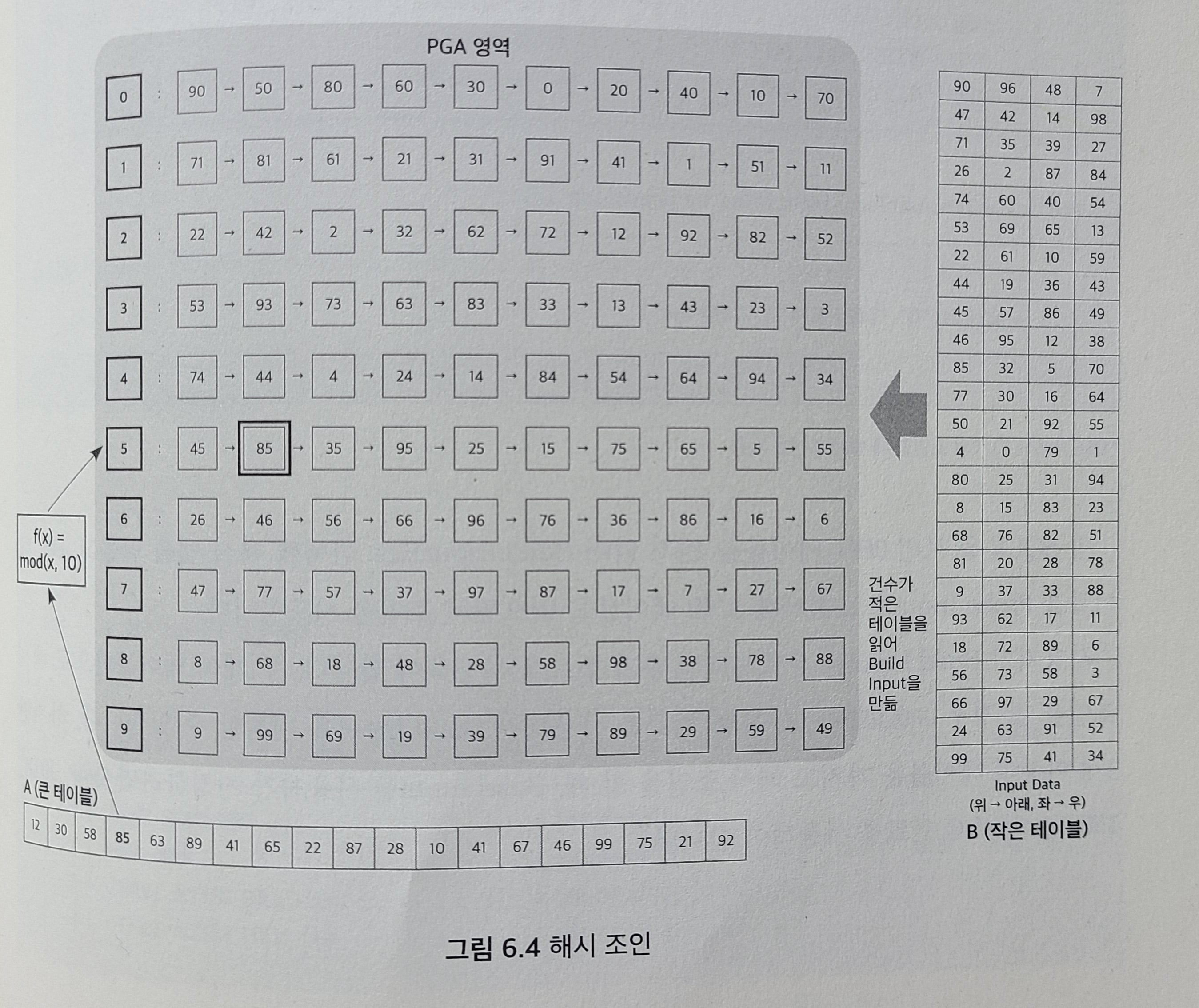
-
해시맵에는 조인컬럼과 select절에 사용한 컬럼까지 포함, SQL작성시 꼭 필요한 컬럼만 기술하는것이 PGA사용량을 줄일 수 있음.
-
해시조인 유도법 : USE_HASH힌트사용.
SELECT /*+ ORDERED USE_HASH(E) */ --E와조인할때 해시조인사용
*
FROM DEPT D
, EMP E
WHERE 1 = 1
AND D.DEPNO = E.DEPTNO -
사용자가 BUILD INPUT을 선택하려면 추가힌트를 사용해야함. 두개테이블만으로 해시 조인할경우 ORDERED(나열순)나 LEADING(지정순) 힌트를 사용해 BUILD INPUT을 지정가능, 3개이상 테이블을 가지고 해시조인을 할때, BUILD INPUT을 사용자가 지정하려면 SWAP_JOIN_INPUTS(테이블명) 힌트를 사용해야함.
-
BUILD INPUT을 옵티마이저에게 선택하도록 맡기려면 USE_HASH만사용한다. 오라클이 통계정보를 확인해 더작은 테이블을 BUILD INPUT으로 선택함
-
BUILD INPUT이 지나치게 큰 테이블로 선택되면 PGA내 해시영역 안에 적재가 힘들어지고 디스크공간을 사용하게됨, 이럴경우 해시조인 성능이 크게 떨어짐. 그래서 BUILD INPUT을 제어하는방법을 꼭 알고있어야함.
4. 조인 방식별 특성 비교
4.1 NL조인
- 장점 : 중간에 멈출 수 있다. 테이블스캔하다 원하는조건만족시 스캔중지
- 단점 : 조인시도시 랜덤엑세스 부하가 매우 높다. 드라이빙 테이블에서 만족하는 결과가 많을경우, INNER테이블에 조인컬럼 기준으로 인덱스가 있다고 하더라도 많은 랜덤 액세스는 엄청난 성능 저하를 가져옴. 만약 INNER테이블에 조인컬럼관련 인덱스가 없을경우 드라이빙 테이블 결과 건수만큼 반복해서 읽어야하는 단점.
드라이빙 테이블 건수 1만건이고 INNER테이블 건수1만건이면 총 1억건을 읽는것과같음.
4.2 소트머지조인
- Outer테이블에 정렬을 대신할 인덱스가있다면 정렬시도안함.
이경우 Inner테이블 크기가 작다면 마찬가지로 정렬부담 줄어듬. - Outer테이블에 정렬을 대신할 인덱스는 없지만, 테이블 자체를 조인 시도하는게 아닌 인라인 뷰(from절안에서 사용된 서브쿼리결과가 뷰처럼 사용)로 만들어진 Group by나 Order by등으로 이미 정렬된 상태라면, 이때도 정렬추가시도안함.
- 해시조인은 등치조건(=)만 사용가능한데, NL조건을 사용하기엔 랜덤액세스 부담이크고 등치조건이 아닌경우 소트머지조인을 사용
- 소트머지조인도 첫번째 테이블에 한해 중간에 멈출수 있음. 첫번째 테이블은 정렬을 대신할 인덱스가 있다면 미리 정렬하지않고 해당인덱스를 이용해 실시간으로 스캔해 조인을 시도, 이경우 중간에 멈춤조건이 있을경우 부분범위 처리를 할 수 있음.
- 단점 : 위상황외는 잘사용안함. 정렬에대한부담, 두테이블을 PGA내 소트영역에 위치시켜야하는데 테이블크기가 커서 PGA공간을 넘을 경우 디스크공간을 사용하기 때문. 이때는 정렬+디스크쓰기부하까지 발생하여 성능저하가 심함.
4.3 해시조인
- NL의랜덤엑세스부하없음, 소트머지의 정렬부담없음 BUT 해시맵을 만들어야함.
- 전체데이터 정렬보다는 해시버킷 만들어놓고, 테이블 스캔하면서 해당버킷만 연결하는게 좀더 부하가 낮음. BUT 해시맵도 PGA내 해시영역에 생성되므로 크기가 작을때 더욱 유리
- 해시함수는 같은값이 입력되면 반환값도 같으므로, 조인키 값의 DISTINCT VALUE수와 전체값의 수가 큰차이를 보이면 심각한 성능저하 발생할수 있음. 조인컬럼의 값에 중복이 적거나 WHERE절에 조인컬럼으로 값을 걸러내는 필터조건이 ㅇ벗어야 함.
SELECT ~
FROM ~
WHERE A.KEY = B.KEY
AND B.KEY = '30' - 위쿼리에서 B테이블이 BUILD INPUT이면 하나의 버킷에 해시체인이 연결됨, 만약 B.KEY='30'조건에 만족하는 값이 1만개라면 A테이블에서 1만번씩 체인을 탐색하는 결과를 초래
이런경우 해시조인좋지않음. - 위에서 B.KEY ='30'조건이 없더라도 실제값이 30으로중복되는경우가 많다면 위예제와 동일한 현상발생. 이럴경우 해시조인은 극심한 성능저하
- 소트머지와 해시조인은 정렬과정/해시맵 생성과정에서 많은양의 CPU부하를 가져옴
4.4 최종요약
NL조인
- 온라인 트랜잭션이 많고 부분범위처리(주로 페이징)가 가능할때
- 각 테이블의 데이터는 많지만 추출 대상이 되는데이터 양이 많지 않을때.
소트머지 조인
-
첫번째 테이블에 조인컬럼 기준으로 인덱스가 있어 정렬부하 발생 안할때
-
Group by 또는 Order by등으로 이미정렬한 서브쿼리와 조인시도시 두번째 테이블의 양이적을때
-
테이블의 양이 매우 커서 NL조인이 힘들고, 조건이 등치조건이 아니어서 해시조인도 힘들때
해시조인
-
대용량 테이블을 조인시도하는데 조인 컬럼에 적당한 인덱스가 없어서 NL조인이 힘들때
-
조인컬럼에 인덱스가 있지만 드라이빙 테이블의 건수가 많아 INNER테이블로 많은 양의 랜덤액세스가 발생할때
-
두 테이블의 양이 많아 소트머지조인 시도시 정렬로 인한 부하가 클때
기본원리를 이해하면서 시스템상황에 맞춰 적절히 사용하는것이 최선
5. 인덱스 생성전략(예제)
SELECT A.*
,B.*
FROM ITEM A
, UITEM B
WHERE A.ITEM_ID = B.ITEM_ID
AND A.ITEM_TYPE_CD = '100100'
AND A.SALE_YN = 'Y'
AND B.SALE_YN = 'Y'
- NL조인 : ITEM(ITEM_TYPE_CD+SALE_YN), UITEM(ITEM_ID+SALE_YN)
- 소트머지조인 : ITEM(ITEM_TYPE_CD+SALE_YN+ITEM_ID), UITEM(SALE_YN+ITEM_ID)
- 해시조인 : ITEM(ITEM_TYPE_CD+SALE_YN), UITEM(SALE_YN)
해시조인에서는 조인컬럼이 인덱스에 포함되지않아도 성능상의 손익은 없음.
6. OUTER JOIN
- NL조인이나 소트머지조인은 (+)이 붙으면 조인순서변경이 안됨. 오라클에서 무시
- OUTE해시조인은 BUILD INPUT을 지정할수있음.
7. 스칼라 서브쿼리
- 입력값에 대해 반환값을 한개만 반환하는 쿼리
- 내부적으로 캐시에 값을 저장해둠. 입력값과 출력값이 같으면 쿼리를 수행하지않는 원리로 캐시저장
- 입력값과 출력값을 저장해 두고 스칼라서브쿼리가 실행될때, 캐시에서 입력값을 찾아보고 만약있으면 미리저장된 출력값을 반환, 없으면 스칼라 서브쿼리를 실행해 결과값을 캐시에 저장
- 캐시도 한정된자원이기에 SQL문의 결과값이 많다면, 스칼라 서브 쿼리의 호출도 많아짐.
이때 스칼라서브쿼리 입력값이 다양해지면 캐시저장해야할 값이 많아지고, 재사용가능성도 낮아짐, 재사용가능성이 낮은상황에서 캐시를 확인하는 불필요한 과정이 발생
이런 상황을 피하려면 자주 반복되고 값의 종류가 다양하지않는테이블(공통코드테이블등) 과 조인이 필요할때 사용하면 효과가 좋음. - 스칼라 서브쿼리는 1개의 결과만 RETURN 이를 보완하는방법으로는
INLINE VIEW에서 가져올컬럼들을 합쳐서 가져온다음 SUBSTR하는방법이있음.
아래 예문에서 DNAME과 LOC를 각각 스칼라서브쿼리호출하지않고 합쳐서가져온다음 분리하는방법-
REGEXP_SUBSTR(SUB, '[^$]+', 1, 1) : DNAME
-
REGEXP_SUBSTR(SUB, '[^$]+', 1, 2) : LOC
(SELECT DNAME || '$' || LOC FROM
) SUB또다른 방법 > 컬럼길이보다 길게 PAD값을주고 가져와서 잘라쓰기
-
TRIM(SUBSTR(SUB,1,20)) :DNAME
-
TRIM(SUBSTR(SUB,21,20)) : LOC
(SELECT LPAD(DNAME, 20 || LPAD(LOC,20) ~~) SUB
-
