이미지 블렌딩
# 이미지 2개 선택해서 불러오기
# 2장 이미지 출력하기
img1 = cv2.imread('./data/pets.jpg')
img2 = cv2.imread('./data/mokoko.jpg')
# 색상공간 변환 bgr -> rgb
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 이미지 크기 변경 - 사이즈가 동일해야 블렌딩이 가능
img1 = cv2.resize(img1, dsize=(255,255))
img2 = cv2.resize(img2, dsize=(255,255))
# cv2.addWeighted(이미지1, 가중치, 이미지2, 2가중치, 전체가중치)
result = cv2.addWeighted(img1, 0.5, img2, 0.5, 0)
# 출력해보기
plt.subplot(1,3,1)
plt.imshow(img1)
plt.subplot(1,3,2)
plt.imshow(img2)
plt.subplot(1,3,3)
plt.imshow(result)
# 이미지 크기 학인하기
# 배열.shape > 크기
print('img1:', img1.shape)
print('img2:', img2.shape)
print('result:', result.shape)
#
img1: (255, 255, 3)
img2: (255, 255, 3)
result: (255, 255, 3)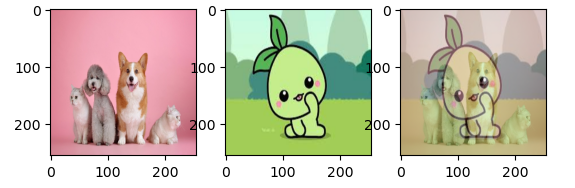
이미지 블렌딩 게임 제작
- 데이터 수집 (20~30장)
- crawlingDB 디렉토리(폴더)에 접근해서 이미지 확인
- 이미지 읽기 출력 + 이미지 처리
- 이미지 이름 영한사전 구축
- 이미지에 맞는 한국어 단어 출력하는 알고리즘 짜기
- image 블렌딩 : addWeighted() 2,3장
- 정답을 입력받아 맞는 체크하는 알고리즘 짜기
# 이미지 출력도구
# 오픈씨브이
# 넘파이
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os # 운영체제 - 파일 관리 시스템
from PIL import ImageDirectory 접근하기
- os 모듈(라이브러리) 이용
# os.listdir(경로): 해당 경로 안에 있는 파일 이름 출력하는 기능
img_fd = os.listdir('./crawlingDB/')
img_fd# 해당 이미지 불러와서 출력해보기
img = cv2.imread(f'./crawlingDB/{img_fd[-1]}')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()정답 데이터 레이블 사전 구축하기
# 리스트 내부 모든 요소의 확장자 제거한 후 리스트 저장하기
# 문자열에서 . 분리하는 기능
# 결과 인덱싱
# 리스트 저장
# img_fd2 = []
# for name in img_fd:
# img_fd2.append(name.split('.')[0])
# img_fd2
img_fd2 = [name.split('.')[0] for name in img_fd ]
img_fd2
len(img_fd2)# 1. 영한 번역기 딥러닝 모델 연결해서 한국어 문자열 생성
# 2. 수기로 일일히 작성하는 방법
# print(img_fd2)
kor_name = kor_name = ['사과','고양이','체리','도라에몽','포도','햄버거','아이스크림','제니','망고', '유재석','메론','모코코', '오렌지','포메라니안','푸들','토끼','장미','라이언','호랑이','토마토','떡볶이','튤립','수박','얼룩말']
# print(kor_name)
# print(len(kor_name))
# dict(kor_name)
# 데이터 두개 연결하기 zip()
name_dict = dict(zip(img_fd2, kor_name))
print(name_dict)# 고양이 출력되게 데이터 접근
name_dict['cat']
name_dict[img_fd2[1]]
# '고양이'이미지에 맞는 한국어 단어 출력하는 알고리즘 짜기
- 인덱스 번호 0 고정
img = cv2.imread(f'./crawlingDB/{img_fd[0]}')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
en_name = img_fd[0].split('.')[0]
ko_name = name_dict[en_name]
print(ko_name)
# 랜덤한 숫자값 생성해서 연결해보기
rd_int = np.random.randint(0, len(img_fd), size=2)
rd_int
#
array([21, 23])len(img_fd)# 이미지 2개 가지고 와서 출력해보기
# 이미지1 - 한국어, 이미지2 - 한국어
# 랜덤한 숫자값 생성해서 연결해보기
ext_img = []
ext_name = []
rd_int = np.random.randint(0, len(img_fd), size=3)
for i in rd_int:
img_path = (f'./crawlingDB/{img_fd[i]}')
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# plt.imshow(img)
# plt.show()
en_name = img_fd[i].split('.')[0]
ko_name = name_dict[en_name]
ext_img.append(img_path)
ext_name.append(ko_name)
print(ext_img)
print(ext_name)
이미지 블렌딩 기능 만들기
- 2장 블렌딩 하기
ext_imgimg1 = cv2.imread(ext_img[0])
img2 = cv2.imread(ext_img[1])
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 블렌딩
# 1. 이미지 크기 동일하게 맞춤(128,128) 2. 섞는 기능 (0.6, 0,4, 0)
img1 = cv2.resize(img1, dsize=(128,128))
img2 = cv2.resize(img2, dsize=(128,128))
img_add = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
# 이미지 출력
plt.imshow(img_add)
plt.show()- 3장 블렌딩 만들기
ext_imgimg1 = cv2.imread(ext_img[0])
img2 = cv2.imread(ext_img[1])
img3 = cv2.imread(ext_img[2])
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
img3 = cv2.cvtColor(img3, cv2.COLOR_BGR2RGB)
# 블렌딩
# 1. 이미지 크기 동일하게 맞춤(128,128) 2. 섞는 기능 (0.6, 0,4, 0)
img1 = cv2.resize(img1, dsize=(128,128))
img2 = cv2.resize(img2, dsize=(128,128))
img3 = cv2.resize(img3, dsize=(128,128))
img_add = cv2.addWeighted(img1, 0.6, img2, 0.5, 0)
img_add = cv2.addWeighted(img_add, 0.5, img3, 0.4, 0)
# 이미지 출력
plt.imshow(img_add)
plt.show()- 이미지 블렌딩 함수 정의하기 : 2~3 사이즈 지정에 따라 실행 코드 제약조건 걸어주기
def add_img(ext_img, size):
if size == 2:
img1 = cv2.imread(ext_img[0])
img2 = cv2.imread(ext_img[1])
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 블렌딩
# 1. 이미지 크기 동일하게 맞춤(128,128) 2. 섞는 기능 (0.6, 0,4, 0)
img1 = cv2.resize(img1, dsize=(128,128))
img2 = cv2.resize(img2, dsize=(128,128))
img_add = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
# 이미지 출력
plt.imshow(img_add)
plt.show()
elif size == 3:
img1 = cv2.imread(ext_img[0])
img2 = cv2.imread(ext_img[1])
img3 = cv2.imread(ext_img[2])
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
img3 = cv2.cvtColor(img3, cv2.COLOR_BGR2RGB)
# 블렌딩
# 1. 이미지 크기 동일하게 맞춤(128,128) 2. 섞는 기능 (0.6, 0,4, 0)
img1 = cv2.resize(img1, dsize=(128,128))
img2 = cv2.resize(img2, dsize=(128,128))
img3 = cv2.resize(img3, dsize=(128,128))
img_add = cv2.addWeighted(img1, 0.6, img2, 0.5, 0)
img_add = cv2.addWeighted(img_add, 0.5, img3, 0.4, 0)
# img_add 이미지 출력
plt.imshow(img_add)
plt.show()
ext_imginput_size = int(input("이미지 블렌딩 장수 선택(2or3)>>"))
if input_size < 4:
ext_img = []
ext_name = []
rd_int = np.random.randint(0, len(img_fd), size=input_size)
for i in rd_int:
img_path = (f'./crawlingDB/{img_fd[i]}')
en_name = img_fd[i].split('.')[0]
ko_name = name_dict[en_name]
ext_img.append(img_path)
ext_name.append(ko_name)
print(ext_img)
print(ext_name)
add_img(ext_img=ext_img, size=input_size)
print(ext_name)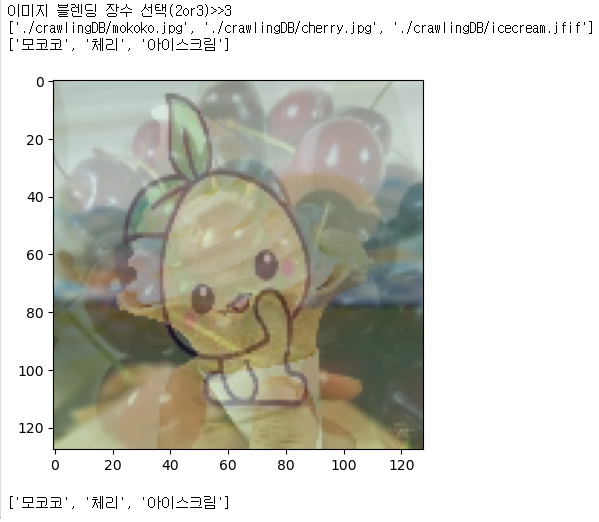
출력된 블렌딩 결과 이미지를 보며 맞추기
- 사용자로부터 단어를 ,로 구분하여 한번에 입력받기
- 입력받은 단어를 , 구분자로 나누어 user_input 리스트에 담기
- user_input길이가 size랑 같을 경우만 아래 내용 진행하기
- 한 단어씩 extract_name 안에 있는 단어인지 확인하면서 맞으면 cnt 1증가
- 블렌딩된 장수 만큼 cnt값이 차면 정답! 아닐 경우는 오답! 출력하는 알고리즘 짜기
# input() 진행시 안내 문구
# 합쳐진 이미지 장수에 맞춰 단어를 ,로 구분 후 입력해주세요!!
# 이미지 2장 - 햄버거, 라이언
def result(input_size):
user_input = input("합쳐진 이미지 장수에 맞춰 단어를 ,로 구분 후 입력해주세요!!>> ").split(',')
user_input
# 문자열 양쪽 공백제거하는 함수: 문자열.strip()
cnt = 0
if len(user_input) == input_size:
for i in user_input:
# 실제 정답 리스트 ext_name
if i.strip() in ext_name:
cnt += 1 # 정답일시 +1
if cnt != input_size:
print("틀렸습니다!")
return 0
else:
print("정답입니다!")
return 1
else:
print("잘못된 입력입니다!")
return 0result(3)합쳐진 이미지 장수에 맞춰 단어를 ,로 구분 후 입력해주세요!!>> 햄버거, 라이언, 도라에몽
틀렸습니다!게임 실행 코드 완성하기
- 게임 실행하면 이미지 블렌딩 게임 시작 문구 출력 ("이미지 블렌딩 게임 START!!!")
- 블렌딩할 이미지 장수(난이도 설정) 입력받기
- 블렌딩 이미지 결과 사용자에게 띄우기
- 정답 맞추기 입력창 띄우기
- 맞추면 "정답을 맞추셨습니다!", 하나라도 틀리면 "틀렸습니다!" 출력 (잘못된 입력일 때는 4번 다시 실행하기)
- 6-1. 5번에서 정답을 맞출경우는 게임 재시작 여부(s)를 입력받기, 재실행일 경우는 1부터 재실행 / 종료(q)
- 6-2. 5번에서 틀릴경우는 재실행(틀리거나 잘못 입력은 횟수는 3번까지 기회가 주어짐)
while True:
print("★★★★★★★★이미지 블렌딩 게임 START!!★★★★★★★★")
input_size = int(input("이미지 블렌딩 장수 선택(2or3)>> "))
if input_size < 4:
ext_img = []
ext_name = []
rd_int = np.random.randint(0, len(img_fd), size=input_size)
for i in rd_int:
img_path = f'./crawlingDB/{img_fd[i]}'
en_name = img_fd[i].split('.')[0]
ko_name = name_dict[en_name]
ext_img.append(img_path)
ext_name.append(ko_name)
add_img(ext_img=ext_img, size=input_size)
# 정답 체크
cnt = result(input_size)
print()
wrong_cnt = 3
while cnt != 1:
# 첫 입력이 틀리면 해당 while 실행
print(f"맞출 수 있는 횟수(남은횟수):{wrong_cnt}")
wrong_cnt -= 1 # wrong_cnt = wrong_cnt - 1
cnt = result(input_size)
if cnt==1 or wrong_cnt <= 0:
break
print()
ch = input("[s]게임 다시 시작 [q]종료 >>").lower()
if ch == 'q':
print("★★★★★★★★이미지 블렌딩 게임 종료!!★★★★★★★★")
print()
break

개발자