목표
- kaggle 제공하는 독버섯/식용버섯 분류 데이터를 활용해서 분석을 진행해보자
- Tree 모델 이해해보자
- Tree 모델이 선택한 중요한 특성을 확인해보자
- https://www.kaggle.com/datasets/uciml/mushroom-classification
- 문제데이터: 특성, 피처, feature, 독립변수, 설명변수, x
- 답데이터: 레이블, label, 라벨, 종속변수, 반응변수, y
- 2개의 클래스를 분류하는 것: 이진분류(binary classification)
# 환경셋팅
import pandas as pd
import numpy as np
# 머신러닝 패키지 (sklearn)
from sklearn.neighbors import KNeighborsClassifier # knn 분류
from sklearn.tree import DecisionTreeClassifier # tree 분류
from sklearn.metrics import accuracy_score # 정확도 평가 지표 (metrics 평가지표를 묶어놓은 모음집)1. 데이터 불러오기
pd.options.display.max_columns = 10 # 개수 제한 X
pd.options.display.max_rows = None# 판다스 옵션 찾아서 컬럼의 내용 다 표현하기
data = pd.read_csv('./data/mushroom.csv')
data.head() # 앞에서 부터 5개data.tail() # 맨 마지막 5개# 데이터 정보 확인
# 정보 확인하는 기능(함수) : info()
data.info()2. 전처리(정제)
- 결측지 처리
- 원핫인코딩
data['stalk-root'].value_counts()# stalk -root "?" 값을 가진 행은 몇개일까?
data.loc[data['stalk-root'] == "?", 'stalk-root'] = 'b' # ? 위치에 접근해서 'b'로 치환(대입)
data.loc[data['stalk-root'] == "?"] # ? -> b 롹인할 수 있음
data.tail()# X, y 분리
X = data.iloc[:,1:] # 열이 많아서 (차원이 커서)
y = data.iloc[:,0] # 열이 1 (차원이 작아서)
# 크기확인
print(X.shape)
print(y.shape)(8124, 22)
(8124,)
# 원핫인코딩
# pd 원핫인코딩 기능을 담당하는 함수 이름은? 사용방법은? pd.get_dummies(대상)
# 특성 데이터(문제 데이터), 딥데이터 분리
data.head(2)
X_oh = pd.get_dummies(X)
print(X_oh.shape)
X_oh.head(2)(8124, 116)
#train, test 분리
# data.isnull().sum()3.데이터 탐색(탐색적 데이터 분석)
- 기술통계량(최빈값..)
X.describe()y.value_counts() # 식용 버섯이 조금 더 많은 상황, 엄청나게 편향된 편은아니다. 학습할 때 나름대로 도움이 될 것 같음
# 학습이 잘 될 데이터인가?
# - 좋은 모델 만들기 위한 데이터
# 1. 데이터의 양이 많으면 도움이 됨
# 2. 이상치가 없고(일관된), 다양성이 유지가 된 데이터가 도움이 됨
# 3. 편향되지 않은 데이터poisonous
e 4208
p 3916
Name: count, dtype: int64X_oh4. 모델선택 및 하이퍼 파라미터
# Tree 객체 생성
tree_model = DecisionTreeClassifier()
# max_depth : 모델 최대 깊이
# min_samples_split=2 : 최소 2개 정도 데이터가 있어야 분리 가능
# min_samples_leaf=1, : 리프 노드가 가지고 있는 데이터의 최소 값은 1개는 꼭 있어야함
# max_leaf_nodes=None : 리프 노드의 최대 개수
# 나머지 3개의 키워드는 깊이 내부의 노드 개수를 제한하면서 상세하게 규칙의 개수를 제한하는 것 => 과대적합을 해소하는 방법# 데이터 랜덤 샘플링
from sklearn.model_selection import train_test_split # train, test 분리한다!
# 7:3
X_train, X_test, y_train, y_test = train_test_split(X_oh, y, test_size=0.3, random_state=7)
X_train
# 데이터가 랜덤하게 섞이는데, 실행할 때마다 바뀌어서 모델 결과에 대한 이해를 하는데 어렵게 하기 때문에
# 랜덤 값을 고정하고 간다!
# 크기확인
# shape
print('훈련용 문제:', X_train.shape)
print('훈련용 답:', y_train.shape)
print('테스트용 문제:', X_test.shape)
print('테스트용 답:', y_test.shape)
# 사용하는 특성(문제, 독립변수, X)의 개수는 몇개인가? 22개 -> 116개 (원핫인코딩)
# 훈련용 문제 행의 개수가 답 개수랑 같은가?
# 테스트용 문제 행의 개수가 답 개수랑 같은가?훈련용 문제: (5686, 116)
훈련용 답: (5686,)
테스트용 문제: (2438, 116)
테스트용 답: (2438,)
5.모델학습
# 학습하기
# 모델.fit(훈련문제, 훈련답)
tree_model.fit(X_train, y_train)
# 분류 하기 위한 규칙 생성됨
# 어떤 특성이 독/식용 잘 분리할 수 있을까? => 지니불순도 : 어떤 특성이 불순도(불순한 정도)를 낮게 할 지 확인
# 불순도가 가장 낮아지는 특성 1개를 선택해서 root node 에서 질문을 던지고 yes, no 데이터를 분기해나
6. 모델 예측 및 평가
# 모델.predict(테스트문제)
pre = tree_model.predict(X_test)
prearray(['p', 'p', 'e', ..., 'e', 'e', 'e'], dtype=object)# 얼마나 잘 맞춘걸까? (평가, 검증)
# 해당 모델이 얼마나 성능이 나는지 확인하는 것
accuracy_score(y_test, pre) # 100% 맞춘 것
# 새로운 X_test2 가 들어오면 또 잘 맞출까????
# 여러번 X_test 가 들어와도 잘 맞출 수 있을까???
# 임의의 테스트 데이터를 만들어 여러번 검증하는 작업 (교차검증: cross validation)
from sklearn.model_selection import train_test_split, cross_val_score
cross_val_score(tree_model, X_train, y_train, cv=5)
# 5번 검증을 했음에도 거의 100% 성능을 내고 있는 상황
# 어떤 상황에도 일반적으로 좋은 성능을 내는 일반화된 모델!
# 독/식용 버섯 분류를 엄청 잘하고 있는 상황array([1. , 1. , 1. , 0.99912049, 1. ])tree 모델이 선택한 특성 확인하기
- 특성의 중요도 확인하기
y0 p
1 e
2 e
3 p
4 e
..
8119 e
8120 e
8121 e
8122 p
8123 e
Name: poisonous, Length: 8124, dtype: objectX_oh.columnsIndex(['cap-shape_b', 'cap-shape_c', 'cap-shape_f', 'cap-shape_k',
'cap-shape_s', 'cap-shape_x', 'cap-surface_f', 'cap-surface_g',
'cap-surface_s', 'cap-surface_y',
...
'population_s', 'population_v', 'population_y', 'habitat_d',
'habitat_g', 'habitat_l', 'habitat_m', 'habitat_p', 'habitat_u',
'habitat_w'],
dtype='object', length=116)
# improtance
# 인덱스, 컬럼 x => array -> pandas 데이터 구조
fi = tree_model.feature_importances_
fi_s = pd.Series(fi, index = X_oh.columns)
fi_s.sort_values(ascending=False) [:10]
# 0~1 값으로 특성의 중요도를 표현 (지니불순도)
# 1에 가까울수록 중요함 : 독/식용 판단하는데 중요한 기준이 되어짐odor_n 0.608902
stalk-root_b 0.182583
gill-size_b 0.083354
spore-print-color_r 0.036178
odor_l 0.025006
odor_a 0.022942
stalk-color-below-ring_w 0.017417
stalk-surface-below-ring_y 0.013484
ring-number_o 0.005919
cap-surface_g 0.002106
dtype: float64from sklearn.tree import export_graphviz
export_graphviz(tree_model, out_file='tree.dot',
class_names=['독','식용'],
feature_names=X_oh.columns,
impurity=True,
filled=True)import graphviz
with open('tree.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))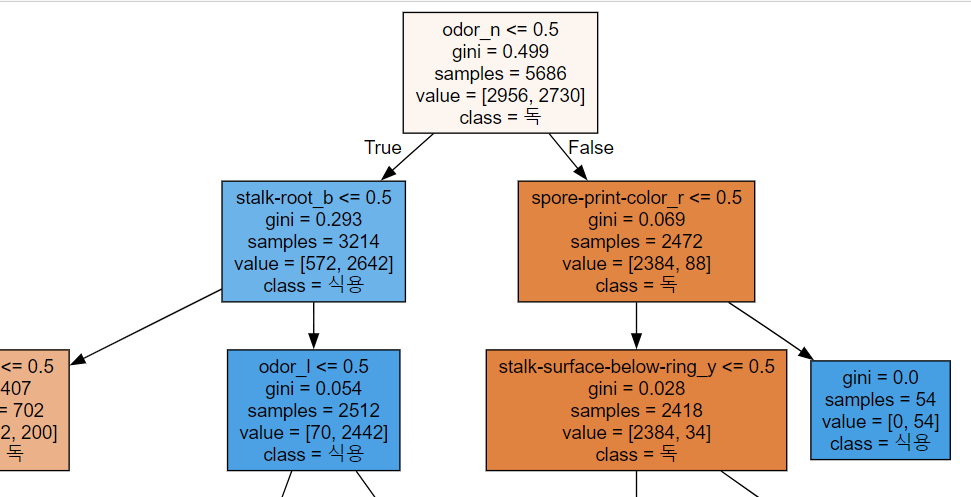
# tree_model2 생성해보기
# max_depth 깊이는 3
tree_model2 = DecisionTreeClassifier(max_depth=3)
# 모델 학습 - 규칙생성 단계
tree_model2.fit(X_train, y_train)
from sklearn.tree import export_graphviz
export_graphviz(tree_model2, out_file='tree.dot',
class_names=['독','식용'],
feature_names=X_oh.columns,
impurity=True,
filled=True)import graphviz
with open('tree.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))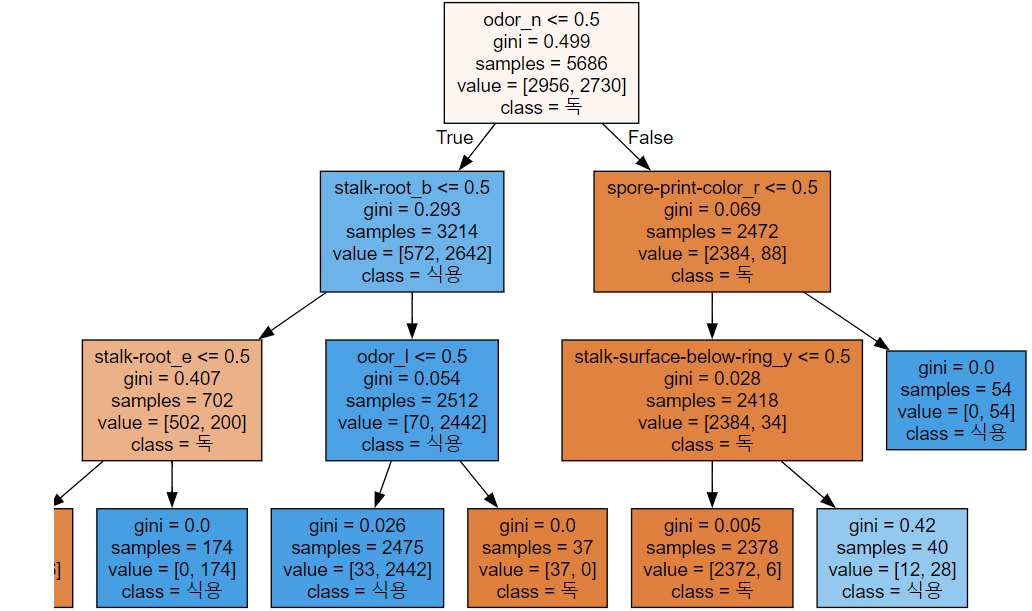
pre2 = tree_model2.predict(X_test)
accuracy_score(y_test, pre2)
# 독/식용 버섯 분류 데이터가 분류를 잘 할 수 있게 셋팅된 데이터
# 좋은 특성을 가진 데이터0.9872846595570139
개발자