완성판 코드
(수정)
코드 추가: 모델 불러오고, mIoU 판단에 쓸 이미지들 파일 경로 불러왔습니다.
오랜만에 글 통계 확인하니까 방문자가 많아서 지난 3월에 완성했던 임의의 모양의 mIoU 구하기 코드를 추가했습니다. - 주석은 거의 없지만, 아래에 코드에 대한 자세한 설명들을 보시면 이해되실 것 같습니다.
'IoU란?' 항목부터는 mIoU 설명과 코드의 기초적인 구현 아이디어를 작성했습니다.
"""
get_miou_with_cv2.py
made by tree.jhk@gmail.com
https://github.com/tree-jhk
https://velog.io/@tree_jhk/%EB%AA%A8%EB%93%A0-%EB%AA%A8%EC%96%91%EC%9D%98-IoU-%EA%B3%84%EC%82%B0%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
"""
import cv2
# import numpy
import os
import torch
global standard_threshold
global flag
flag = True
standard_threshold = 135
model=(torch.load("../CrackForest/weights_79680장_20_32_deep.pt", map_location='cpu'))
flag = torch.cuda.is_available()
if (flag==True):
model=(torch.load("../CrackForest/weights_79680장_20_32_deep.pt"))
model.cuda()
else:
model=(torch.load("../CrackForest/weights_79680장_20_32_deep.pt", map_location='cpu'))
def case_threshold(path,threshold_value):
img=cv2.imread(path)
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
if(threshold_value>standard_threshold):
res,img_gray_thr = cv2.threshold(img_gray,threshold_value,255,cv2.THRESH_BINARY)
else:
res,img_gray_thr = cv2.threshold(img_gray,threshold_value,255,cv2.THRESH_BINARY_INV)
return img_gray_thr
def iou(intersection,union):
if(union!=0):
return intersection/union
else:
return 0
def get_mean_miou(raw_images_path,groundtruth_images_path):
sum_miou=0
raw_images_list=(os.listdir(raw_images_path))
raw_images_list.sort()
raw_images_count=len(raw_images_list)
for image_name in raw_images_list:
if os.path.isfile(raw_images_path+"/"+image_name):
raw_image = cv2.imread(raw_images_path+"/"+image_name, cv2.IMREAD_COLOR)
raw_image = cv2.resize((cv2.imread(raw_images_path+"/"+image_name, cv2.IMREAD_COLOR))
,(224,224)).transpose(2,0,1).reshape(1,3,224,224)
if(torch.cuda.is_available()):
semantic_image = model(torch.from_numpy(raw_image).type(torch.cuda.FloatTensor)/255)
semantic_image = semantic_image['out'].cpu().detach().numpy()
# np.transpose(image,(2,0,1)) for HWC->CHW transformation
transpose_semantic_image = semantic_image[0].transpose(1,2,0)
transpose_semantic_image = cv2.resize(transpose_semantic_image,(224,224))
else:
semantic_image = model(torch.from_numpy(raw_image).type(torch.FloatTensor)/255)
semantic_image = semantic_image['out'].detach().numpy()
transpose_semantic_image = semantic_image[0].transpose(1,2,0)
transpose_semantic_image = cv2.resize(transpose_semantic_image,(224,224))
transpose_semantic_image_name='../CrackForest/save'+'/'+image_name+'.png'
ground_truth_image_name='../CrackForest/save'+'/'+'g_t'+image_name+'.png'
cv2.imwrite(transpose_semantic_image_name,transpose_semantic_image*255)
# transpose_semantic_image
ground_truth_image=cv2.resize(cv2.imread(groundtruth_images_path+'/'+image_name,cv2.IMREAD_COLOR),(224,224))
cv2.imwrite(ground_truth_image_name,ground_truth_image)
# 차선변경영역
# 160 이상인 영역은 흰색 나머지 검정색
class1_semantic=case_threshold(transpose_semantic_image_name,160)
cv2.imshow(image_name,class1_semantic)
cv2.waitKey(0)
cv2.destroyAllWindows()
class1_groundtruth=case_threshold(ground_truth_image_name,160)
cv2.imshow(image_name,class1_groundtruth)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 배경영역
# 10 이하인 영역은 흰색 나머지 검정색
class2_semantic=case_threshold(transpose_semantic_image_name,10)
class2_groundtruth=case_threshold(ground_truth_image_name,10)
# 주행가능영역
# 10 이상 160 이하인 영역은 흰색 나머지 검정색
class3_semantic=cv2.bitwise_not(cv2.bitwise_or(class1_semantic,class2_semantic))
class3_groundtruth=cv2.bitwise_not(cv2.bitwise_or(class1_groundtruth,class2_groundtruth))
# 차선변경영역 iou
class_iou =[]
class1_intersection = cv2.countNonZero(cv2.bitwise_and(class1_semantic, class1_groundtruth))
class1_union=cv2.countNonZero(cv2.bitwise_or(class1_semantic, class1_groundtruth))
class_iou.append(iou(class1_intersection,class1_union))
# 배경영역 iou
class2_intersection = cv2.countNonZero(cv2.bitwise_and(class2_semantic, class2_groundtruth))
class2_union=cv2.countNonZero(cv2.bitwise_or(class2_semantic, class2_groundtruth))
class_iou.append(iou(class2_intersection,class2_union))
# 주행가능영역 iou
class3_intersection = cv2.countNonZero(cv2.bitwise_and(class3_semantic, class3_groundtruth))
class3_union=cv2.countNonZero(cv2.bitwise_or(class3_semantic, class3_groundtruth))
class_iou.append(iou(class3_intersection,class3_union))
ch = 0
sum = 0
for i in range(len(class_iou)):
if(class_iou != 0):
ch+=1
sum+=class_iou[i]
if(ch!=0):
miou = sum/ch
sum_miou+=miou
print(miou,image_name,k)
else:
print("No miou")
else:
print("file does not exists")
return 0
return sum_miou/raw_images_count
raw_images_path = "../CrackForest/changed_Images_320장"
groundtruth_images_path = "../CrackForest/changed_Masks_320장"
if os.path.isdir(raw_images_path):
print(get_mean_miou(raw_images_path,groundtruth_images_path))
else:
print("directory does not exists")IoU란?
IoU(Intersection over Union)는 Detection이나 Semantic Segmentation의 결과를 평가하기 위한 지표 중의 하나입니다.
Detection은 생성된 Bounding Box의 이미지와 Ground Truth 이미지를 활용해서 IoU를 구합니다.
Semantic Segmentation은 마스크 처리된 이미지와 Ground Truth 이미지를 활용해서 IoU를 구합니다.
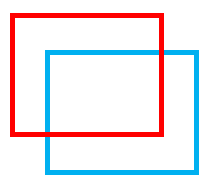
빨간색 박스: Ground Truth
파란색 박스: Bounding Box 결과
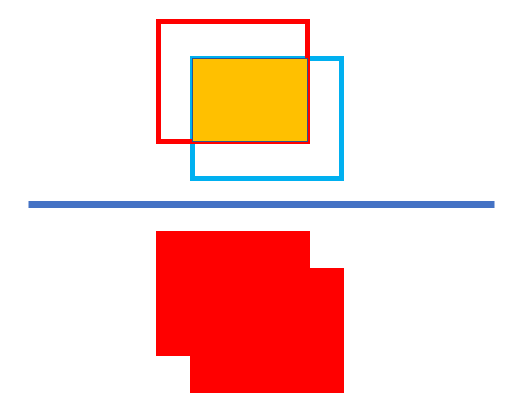
위와 같이, 교집합 면적을 합집합 면적으로 나눈 값을 IoU라고 합니다.
더 자세한 것은 링크 참조: IoU에 대한 자세한 설명 포스트
저는 이번 포스트에서 임의의 모양을 갖는 시멘틱 세그멘테이션한 이미지들의 IoU값을 구해보겠습니다.
IoU 코드 및 활용 방법
이번 포스팅의 실습은 Road Semantic Segmantation한 결과의 IoU값을 계산한 것인데,
클래스 개별적으로 IoU를 하려면, 아래 코드를 활용해서 해당하는 클래스의 RGB값만 1(흰색)로 변환하고 나머지는 모두 0(검정색)으로 처리하면 구해집니다. Instance Segmantation도 마찬가지로 하시면 됩니다.
아래 [구현 아이디어] 파트를 보시면 쉽게 활용 및 응용하실 것 같습니다.
(코드는 짧은데 주석이 많아서 길어보입니다 ㅠ)
아래 코드가 코랩으로 실습한 코드라서 cv2.imshow()가 아닌 plt.show()를 사용했습니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
grd_truth = cv2.imread('../Ground_truth 이미지 이름.jpg')
# Ground truth 이미지를 불러옵니다.
grd_truth_gray = cv2.cvtColor(grd_truth, cv2.COLOR_BGR2GRAY)
# 흑백으로 전환합니다. (왜냐면, cv2.threshold()를 사용해야하기 때문입니다. cv2.threshold()를 사용하는 이유는, bit_wise연산을 하려면 0,1로만 이루어진 이미지를 구해야하기 때문입니다.)
res, grd_truth_thr = cv2.threshold(grd_truth_gray, 30, 255, cv2.THRESH_BINARY)
# grd_truth_thr은 0,1로만 이루어진 numpy.ndarray입니다. 0은 해당 픽셀이 검정색 픽셀이라는 뜻이고, 1은 해당 픽셀이 흰색 픽셀이라는 뜻입니다.
masked = cv2.imread('../masked 이미지 이름.jpg')
masked_gray = cv2.cvtColor(masked, cv2.COLOR_BGR2GRAY)
res, masked_thr = cv2.threshold(masked_gray, 30, 255, cv2.THRESH_BINARY)
#마스크 처리된(segment한 이미지)도 마찬가지로 흑백으로 전환시켜줍니다.
intersection = cv2.countNonZero(cv2.bitwise_and(grd_truth_thr, masked_thr))
# and연산을 해서, 교집합(같은 영역을 비교해서 해당 픽셀에서 둘 다 1이면 교집합이기 때문에 1로 연산합니다.)을 구합니다.
# 그리고 countNonZero로 픽셀이 0이 아닌 것만(검정 픽셀) 계산합니다. 그것이 면적입니다.
plt.imshow(cv2.bitwise_and(grd_truth_thr, masked_thr), cmap='gray')
plt.show()
union = cv2.countNonZero(cv2.bitwise_or(grd_truth_thr,masked_thr))
# or연산을 해서, 합집합(같은 영역을 비교해서 해당 픽셀에서 어느 하나라도 1이면 1로 처리해서 합집합을 구현합니다.)을 구합니다.
# 그리고 countNonZero로 픽셀이 0이 아닌 것만(검정 픽셀) 계산합니다. 그것이 면적입니다.
plt.imshow(cv2.bitwise_or(grd_truth_thr, masked_thr), cmap='gray')
plt.show()
IoU = intersection / union
print(intersection, union, IoU)실습 결과
Ground Truth 이미지: 
Masked 이미지: 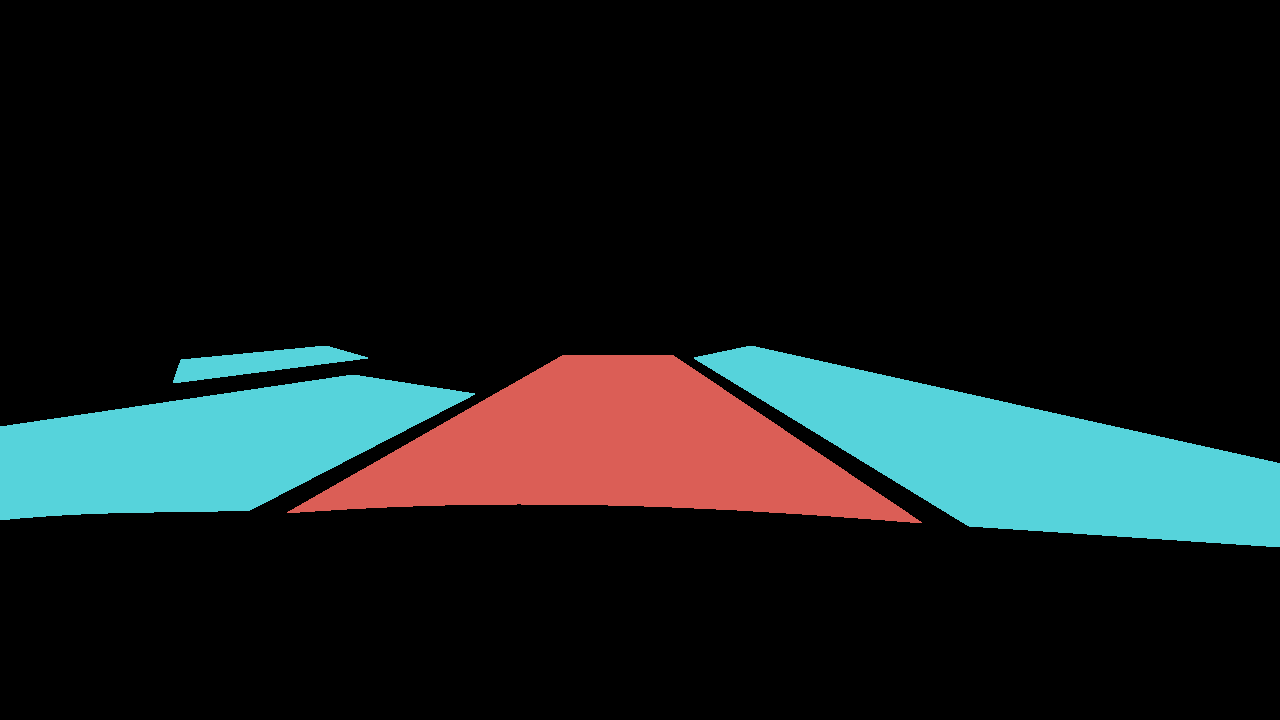
교집합 이미지:
합집합 이미지: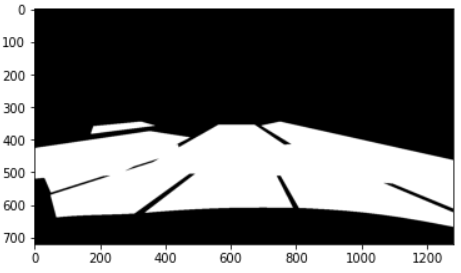
IoU 결과값: 0.26 (교집합 / 합집합)
구현 아이디어
우선, 전체 이미지에서 세그멘테이션된 이미지를 grayscale로 바꿉니다.
grayscale이미지에서 검정색이 아닌 나머지 모든 픽셀은 세그멘테이션이 된 이미지이기 때문에 threshold값을 조절해서 나머지 픽셀들을 1(흰색)으로 변경시킵니다.
그렇게 되면, ndarry가 모두 0 or 1로 구성됐기 때문에 bitwise연산을 이용할 수 있습니다. 자세한 것은 코드에 주석으로 달았습니다.
따라서 합집합 부분은 or연산을 활용했고, 교집합 부분은 and연산을 활용했습니다.
bitwise에 관한 글: bitwise 글
그리고 CountNonZero()함수를 이용해서 전체 ndarry 값 중에서 0이 아닌 값의 개수를 모두 셉니다. 이 개수가 전체 픽셀 중에서 흰색 영역의 픽셀 수입니다.
결과적으로, 흰색 영역의 면적을 구한 것입니다.
최종적으로, IoU는 이러한 방식으로 구현할 수 있었습니다.
포스팅하면서 깨달은 것은, 내가 만든 코드가 아직 각 클래스별로 IoU값을 구하는 것이 아니라 전체를 그냥 계산한 것 같다. 클래스별로 구하는 것에 대한 것은 포스트를 읽는 분께서 조금만 코드를 더 추가하면 가능해보인다.
임의의 모양의 IoU를 계산하려고 한 이유
IoU를 계산하려고 했는데, 관련된 오픈 코드들의 매개변수가 잘 파악이 안되고 적용하는 방법을 명확히 몰라서 적용이 어려워서 직접 구현해봤다.
결과적으로 잘 수행되는 것 같다.
시행착오
사실 원래는 Coutours라는 opencv 개념을 활용해서 세그멘테이션된 면적의 경계를 따고, 그 경계의 면적을 구하려고 했는데, 이렇게 하면 잘 안되기도 하고 계산도 많고 과정도 훨씬 길다.
고민하다가 CountNonZero()를 활용하면 될 것 같았고 결국 문제를 해결할 수 있었다.

image 보면 road가 파란색 road와 빨간색 road가 있는데 각각 구별해서 IoU를 계산한 건 아니고 같은 road object로 생각해서 전체 segmentation에 대한 IoU를 계산한건가요?