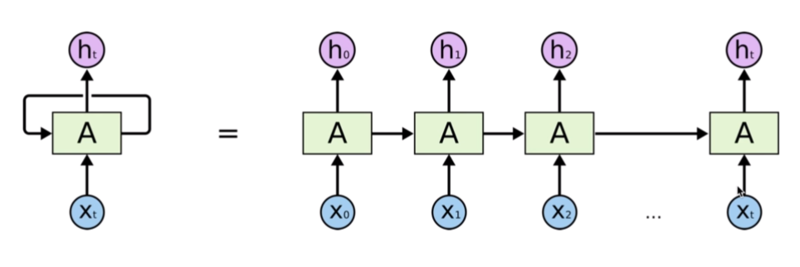
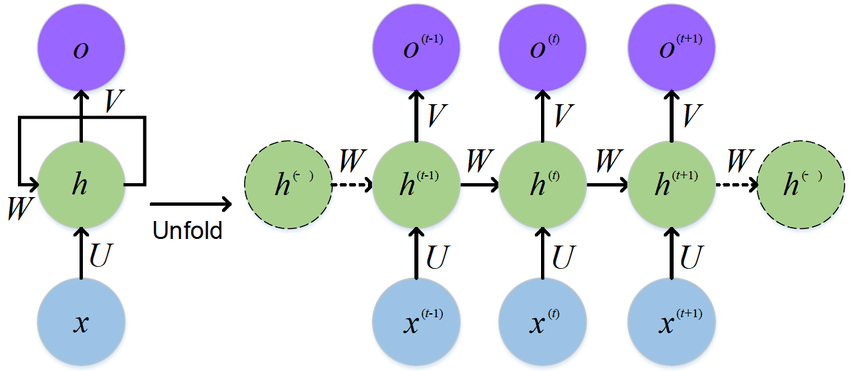
기본적인 형태의 RNN(Vanila RNN)의 문제점은 long term일수록 과거의 정보가 손실이 되기가 쉬워서 단기 기억밖에 못하는 문제점이 있다.
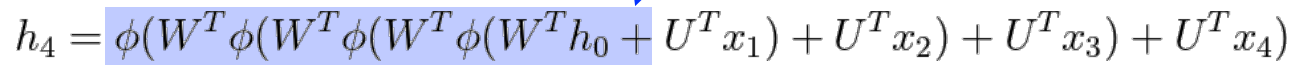
단적으로, 위의 식은 정보 h_4를 얻기 위해, 과거 정보인 h_0에서부터 지속적으로 가중치를 곱해야 한다.
위 식으로 다음의 2가지 문제점들을 알 수 있다.
-
가중치 W와 정보 h_0가 모두 양수일 때, 활성화 함수로 ReLU 함수를 사용하면, h_0를 계속 bypass해서 h_0에 계속 W가 곱해진다. 이렇게 되면 과거 정보인 h_0가 출력에 매우 크게 반영된다. -> exploding gradient 문제 발생
-
만약 가중치 W와 곱한 것이 음수가 나오고, 활성화 함수로 sigmoid 함수를 사용하면, 과거 정보가 계속 소실되면서, 결국 vanishing gradient 문제가 발생한다.
활성화 함수들:
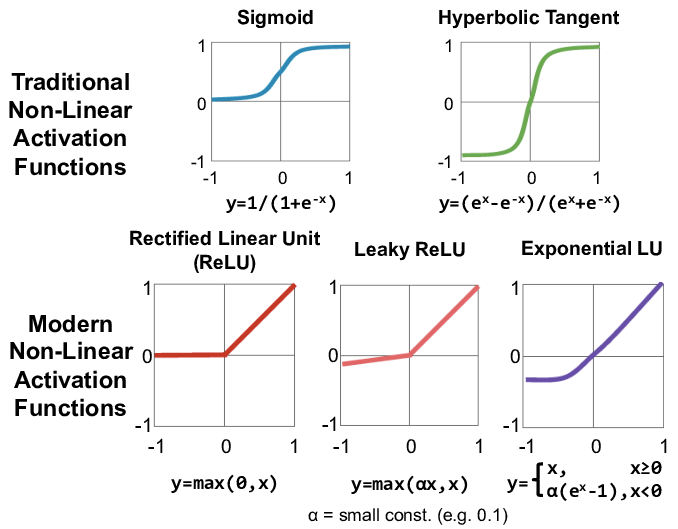
위의 2가지 문제점들로 생긴 궁금증:
- 활성화 함수만 바꾼다고, 1번 문제점인 exploding gradient 문제를 해결할 수 있을까? 그나마 leaky ReLU나 Hyperbloic Tangent를 사용하면 음수값에 대해서 정보를 어느 정도는 다음 시점에 넘겨주기 때문에 학습이 더 잘 될 것 같다.
- 2번 문제인 vanishing gradient 문제도 뭔가 leaky ReLU나 Hyperbloic Tangent를 사용하면 음수값에 대해서 정보를 어느 정도는 다음 시점에 넘겨주기 때문에 학습이 더 잘 될 것 같다.
실험 세팅:
데이터셋: torchtext.legacy.datasets에서 제공하는 IMDB의 영화 리뷰 데이터셋
공통적인 RNNCell_Encoder:
class RNNCell_Encoder(nn.Module):
def __init__(self,input_dim,hidden_size):
super(RNNCell_Encoder,self).__init__()
self.rnn = nn.RNNCell(input_dim,hidden_size)
# RNN의 foward를 초기화
def forward(self,inputs):
bz = inputs.shape[1]
ht = torch.zeros(bz,hidden_size).to(device)
for word in inputs:
ht = self.rnn(word,ht)대조군 ReLU 사용:
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim)
self.rnn = RNNCell_Encoder(embeding_dim,hidden_size)
self.fc1 = nn.Linear(hidden_size,256)
self.fc2 = nn.Linear(256,3)
def forward(self,x):
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = F.sigmoid(self.fc1)
x = F.leaky_relu
x = F.softmax
x = self.fc2(x)
return x실험군1 sigmoid 사용:
class Net_sigmoid(nn.Module):
def __init__(self):
super(Net_sigmoid,self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim)
self.rnn = RNNCell_Encoder(embeding_dim,hidden_size)
self.fc1 = nn.Linear(hidden_size,256)
self.fc2 = nn.Linear(256,3)
def forward(self,x):
x = self.em(x)
x = self.rnn(x)
x = torch.sigmoid(self.fc1(x))
x = self.fc2(x)
return x실험군2 hyperbolic tangent 사용:
class Net_hyperbolic_tangent(nn.Module):
def __init__(self):
super(Net_hyperbolic_tangent,self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim)
self.rnn = RNNCell_Encoder(embeding_dim,hidden_size)
self.fc1 = nn.Linear(hidden_size,256)
self.fc2 = nn.Linear(256,3)
def forward(self,x):
x = self.em(x)
x = self.rnn(x)
x = torch.tanh(self.fc1(x))
x = self.fc2(x)
return x실험군3 leaky ReLU 사용:
class Net_leaky_relu(nn.Module):
def __init__(self):
super(Net_leaky_relu,self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim)
self.rnn = RNNCell_Encoder(embeding_dim,hidden_size)
self.fc1 = nn.Linear(hidden_size,256)
self.fc2 = nn.Linear(256,3)
def forward(self,x):
x = self.em(x)
x = self.rnn(x)
x = F.leaky_relu(self.fc1(x))
x = self.fc2(x)
return xoptimizer:
loss_fn = nn.CrossEntropyLoss()
model = Net()
model.to(device)
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
model_sigmoid = Net_sigmoid()
model_sigmoid.to(device)
optimizer_sigmoid = torch.optim.Adam(model_sigmoid.parameters(),lr=0.0001)
model_hyperbolic_tangent = Net_hyperbolic_tangent()
model_hyperbolic_tangent.to(device)
optimizer_hyperbolic_tangent = torch.optim.Adam(model_hyperbolic_tangent.parameters(),lr=0.0001)
model_leaky_relu = Net_leaky_relu()
model_leaky_relu.to(device)
optimizer_leaky_relu = torch.optim.Adam(model_leaky_relu.parameters(),lr=0.0001)
model_softmax = Net_softmax()
model_softmax.to(device)
optimizer_softmax = torch.optim.Adam(model_softmax.parameters(),lr=0.0001)실험 결과:
- ReLU 사용:
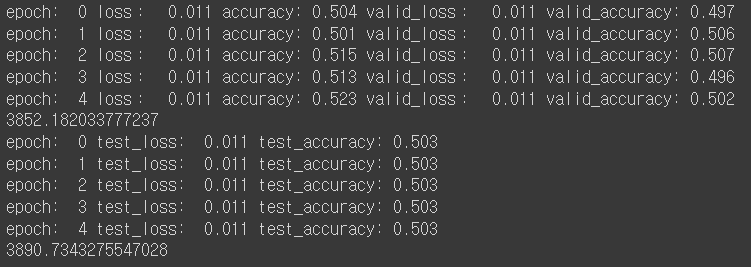
- sigmoid 사용:
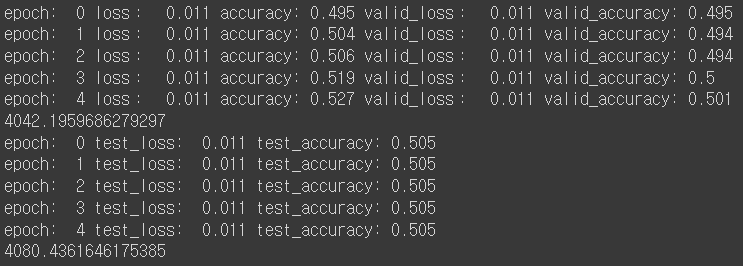
- hyperbolic tangent 사용:
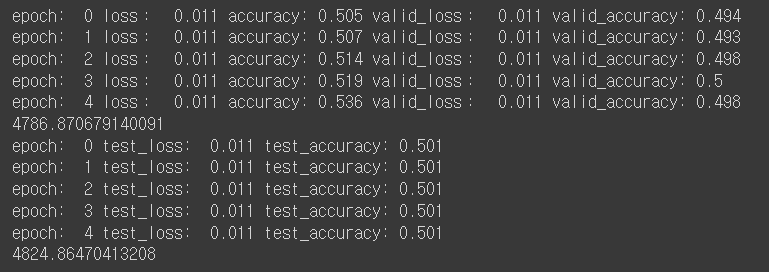
- leaky ReLU 사용:
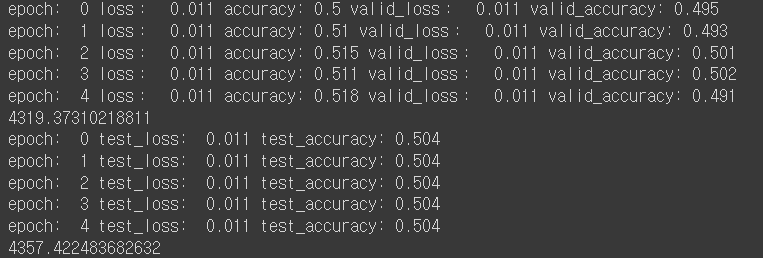
실험 소감
생각했던 것보다, IMDB 데이터셋의 경우, 활성화 함수를 바꾼다고 성능이 크게 바뀌지 않게 됐다.
결국 vanila RNN의 고질적인 문제인 단기 기억을 해결하기 위해 나처럼 많은 시도들을 했었던 것 같다. 결국 한계가 있었기 때문에 LSTM, GRU 같은 모델들을 개발한 것 같다.
다만, ReLU함수의 학습 속도가 제일 빠르다는 것을 확인할 수 있다. (약 1.246배 빨랐다)
vanila RNN 모델에 dropout 적용
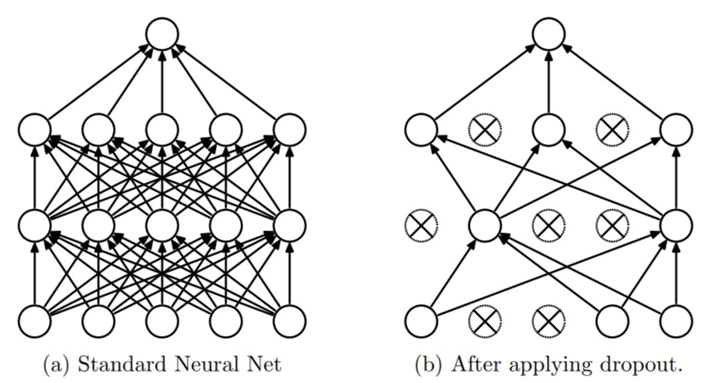
위와 같이 dropout은 신경망이 과적합되는 것을 방지하기 위해, 학습 과정 중 일부 노드(뉴런)을 학습에서 제외시키는 방법이다.
내 예상에는, 애초에 vanila RNN이 학습이 잘 안되기 때문에 dropout의 효과가 좀 무의미할 것 같다.
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim)
self.rnn = RNNCell_Encoder(embeding_dim,hidden_size)
self.fc1 = nn.Linear(hidden_size,256)
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(256,3)
def forward(self,x):
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = self.fc2(x)
return xdropout 적용결과:
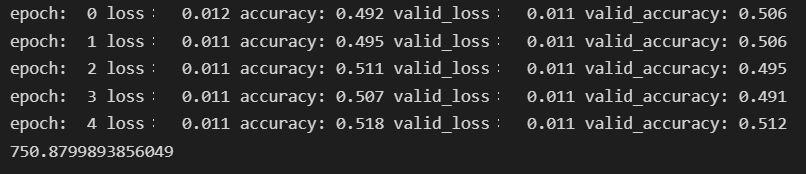
dropout을 적용하지 않을 때보다 확실한 장점이 있었다.
일부 노드들을 학습에서 제외시킴으로서, 학습을 마치는데 소요되는 시간이 매우 줄었다. 3852초->750초 약 5배의 속도 차이가 발생했다.
확실하지는 않지만, 5번째 epoch에서 51.2%로 정확도가 증가한 것처럼 보인다. 물론 test 데이터셋에서는 50.3%로 dropout을 적용하지 않을 때와 큰 차이가 없어보이지만 학습이 제대로 되는 LSTM 모델에서는 dropout이 큰 효과를 발휘할 것 같다.
LSTM 모델에 dropout 적용 전
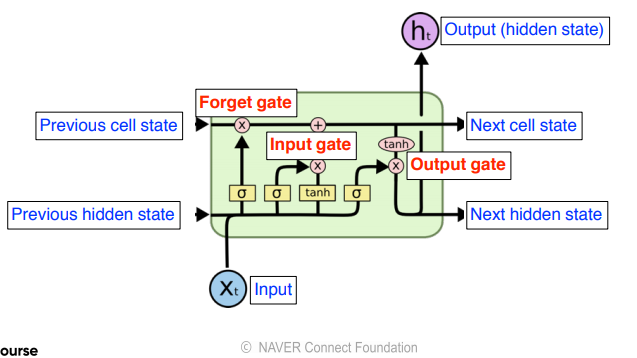
LSTM 모델을 사용하여 위와 같이, 재귀적으로 과거 정보들과 입력값을 함께 사용하여 장기 기억을 할 수 있게 된다.
같은 IMDB 데이터셋에 ReLU를 활성화 함수로 사용해서 성능이 향상되는지 확인해보겠다.
(추가할 예정)
LSTM 모델에 dropout 적용 후
