이번 포스트에서는, 지난 번 포스트에 이어서, 감정 분석을 적용한 데이터셋을 만들겠습니다.
판다스의 dataframe 형식으로 저장도 하고 csv형식으로 최종 저장하겠습니다.
BERT를 사용할 것이고 공개된 pre-trained 모델을 사용합니다.
또한 추후에 비트코인 가격을 추가할 열을 dataframe에 추가하겠습니다.
지난 번 포스트에서 만든 함수를 그대로 사용해서 만듭니다.
지난 번 포스트 링크: [뉴스 제목 감정 분석] 1편 [뉴스 제목 수집하기] 크롤링
자세한 코드 및 자세한 주석은 제 깃허브에 올렸습니다. 링크: 소스코드
1. import
# 감정 분석에 쓸 도구 구성하기 입니다.
import pandas as pd
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
model = AutoModelForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
# 입력: string: 감정 분석하고자 하는 문장
# 출력: 감정 분석 결과 1~5 -> 클수록 긍정적인 문장
def get_sentiment(string:str):
tokens = tokenizer.encode(string,return_tensors='pt')
result = model(tokens)
return (int(torch.argmax(result.logits)) + 1)2. Dataframe 구성하기
news_sentiment_analysis = pd.DataFrame({'Date':[],'News title':[],'Bitcoin price':[],'Sentiment':[]})
3. 완성하기
위의 get_sentiment 함수를 이용해서
데이터프레임을 완성해보겠습니다.
for i,(date,news_titles) in enumerate(news_date_title_dictionary.items()):
for j,n_t in enumerate(news_titles):
sentiment = get_sentiment(n_t)
news_sentiment_analysis.loc[i+j] = [date,n_t,0,sentiment]
display(news_sentiment_analysis)4. 출력 결과
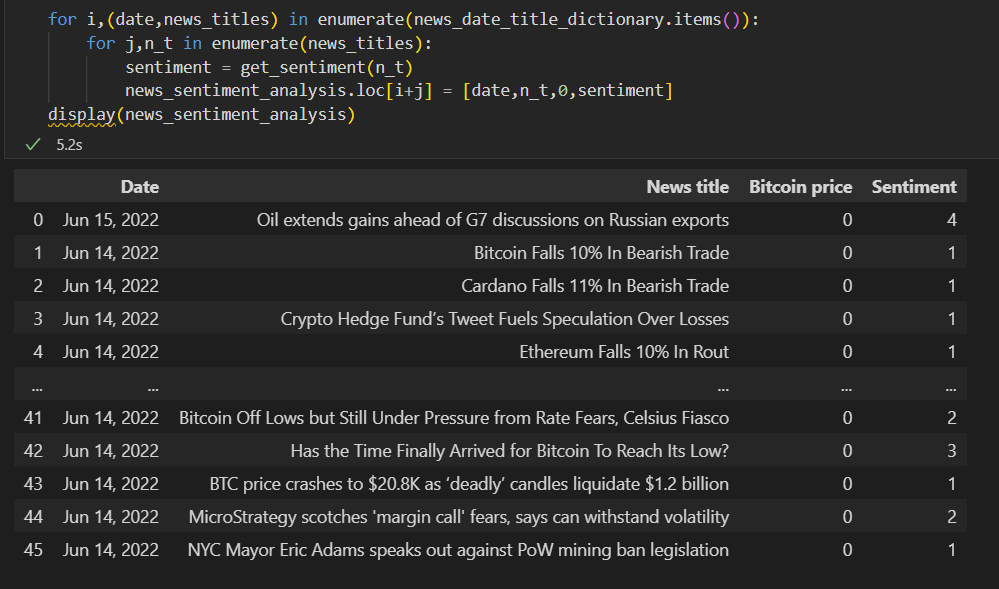
5. 다음 포스트
- 비트코인 가격까지 추가
- 방대한 양의 데이터셋을 구성하기 위해, fastAPI의 비동기식 처리를 이용해서 빠른 데이터 수집을 할 예정

LinkedIn: https://www.linkedin.com/in/junhyuk-kwon-8578b5247/ (1촌 환영해요) (블로그 글은 나중에 시간되면 회고 쓰는걸로....)