- Synthesizing Chest X-Ray Pathology for Training Deep Convolutional Neural Networks (IEEE Medical Imaging 2019)
의료영상은 희귀병변의 데이터가 고질적으로 부족한 문제를 가지고 있음. 이 논문은 deep convolutional GAN (DCGAN) 을 사용해서 합성된 chest X-ray 영상을 만들고, 이를 통해 데이터 불균형 문제를 해결하려고 함. Class는 5개이며, 각 클래스별로 DCGAN 을 훈련한게 특징임.
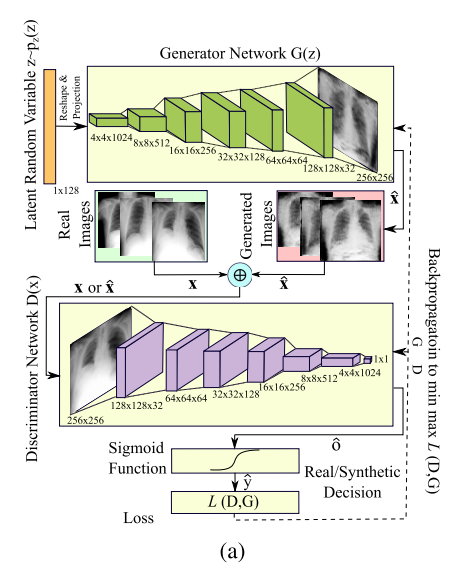
III Proposed Method
A. Synthesizing Chest X-Rays
128 차원의 벡터 Z, 를 4x4x1024 의 공간으로 projection 한 뒤 generator network 를 거쳐서 합성된 X-ray 영상이 출력된다.
합성된 영상들은 실제 영상과 concatenate 되어 discriminator 에 의해 판별된다.
B. Understanding the Latent Feature Space
영상을 합성했으면 그 영상들이 잘 뽑혔는지 검증을 해야한다. 물론 눈으로 보고 괜찮으면 넘어갈 수 있지만, 그 많은 합성영상들을 다 보는 것은 무리거니와 시각적으로 드러나는 것과 컴퓨터가 해석하는 것은 다를 수 있다.
저자들은 256x256 으로 합성된 영상들을 16x16의 latent space 로 축소하는 convolutional autoencoder을 도입하였다. PCA 보다 더 강력한 non-linear dimensionality reduction 을 원했다고 한다.
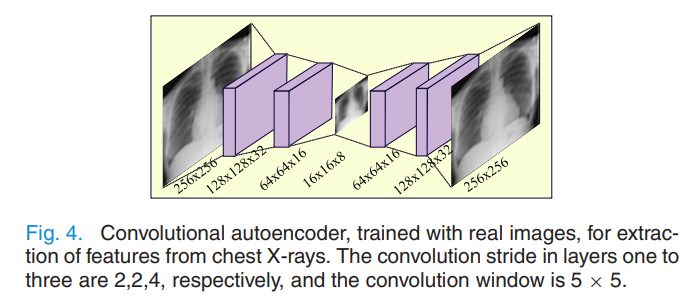
위는 논문에서 차용된 autoencoder 의 구조이다. Encoding block 에 단 3개의 layer만 사용하였고, 최종 latent space embedding의 dimension은 16x16x8 이다.
중요! 저자는 latent space similarity 를 통해 합성된 영상이 실제 영상의 클래스에 속한다는 것을 입증하고자 한다. 따라서, 저자들은 각 클래스의 실제/합성 카테고리마다 feature map 의 centroid 를 구해 (총 8개), centroid 간의 유클리드 거리를 구했다. 만약 synthesized 와 real X-ray 가 class가 같을 때만 distance 가 낮고, 다를 때 distance 가 높다면 저자들의 실험이 성공한 것이다. 자세한 notation 설명은 아래에 있다 (쓰고나니 안봐도 될듯)

최종적으로 원문의 Fig. 10. 이 나온다.
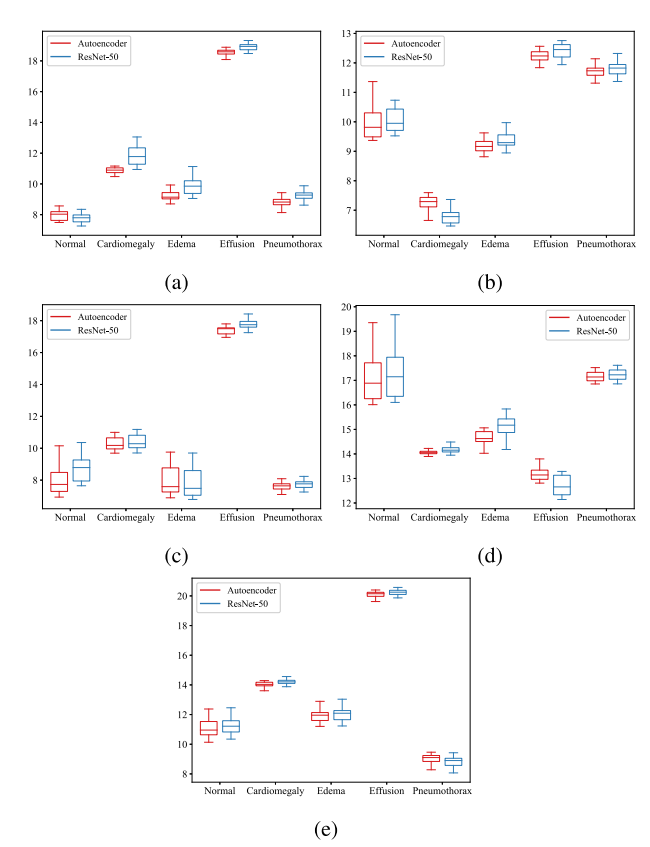
(a) 는 syntehsized normal, (b) 는 synthesized cardiomegal, ... 이렇게 되겠다.
전반적으로 괜찮은 것 같지만, synthesized edema (c) 의 성능이 꽤 불만족스럽다.
IV Experiments
실컷 synthesize 했으니 이 방법론이 효과적이였다는 실험 디자인이 필요하겠지?
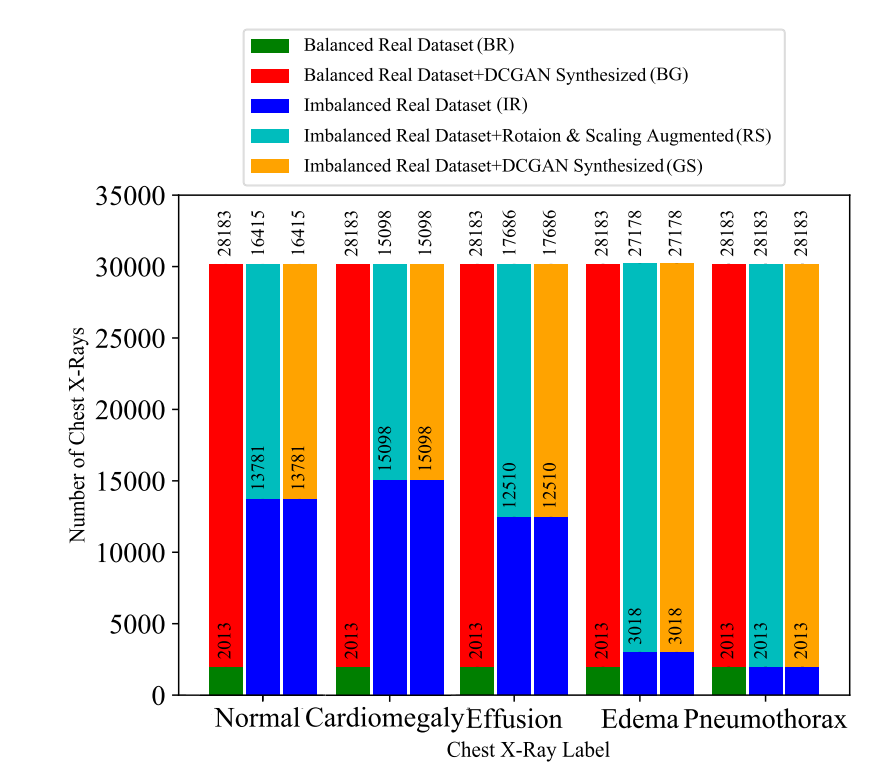
디자인은 이 한장으로 정리된다. 총 5종류의 데이터셋 구성이 있는데,
- Balanced Real Dataset (BR)
모든 데이터를 제일 적은 클래스에 맞춰서 균형을 강제로 맞춤
- Balanced Real Dataset + DCGAN synthesized (BG)
일단 밸런스를 맞춘 다음에, 압도적으로 부족한 데이터를 합성영상으로 채움
- Imbalanced Real Dataset (IR)
균형이 맞춰져있지 않은 원 데이터셋을 그대로 사용
- Imbalanced Real Dataset + Rotation & Scaling Augmentation (RS)
3에 traditional augmentation 을 사용해서 채움
- Imbalanced Real Dataset + DCGAN synthesized (GS)
3에 DCGAN을 사용해 합성한 영상을 추가. 논문에서 제안한 방법임. 제일 많은 클래스도 두배 뻥튀기시켰음.
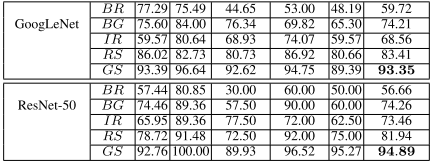
뭐,, 대충 DCGAN 이 제일 좋았다! 긴 한데, 여기서 한가지 더 얻어갈 교훈은 아무리 데이터 불균형이 일어난다 하더라도 원 데이터셋을 최대한 살리자.
