지난 시간엔 ProtoPNet 에 대해 알아보았다. Prototype 는 한 클래스마다 임의의 개수로 존재하는 latent space patch 이고, convolutional layer 을 거쳐서 나온 feature space의 각 pixel과 (prototype 이 1,1 이라고 가정) prototype 사이에 가장 높은 유사도를 그 prototype 의 score 라고 사용하기로 했다. 또한, classification 의 최종 logit은 온전히 prototype score를 사용해서 계산하기로 한 것이 ProtoPNet의 핵심 개념이다.
자. ProtoPNet 을 이해했다면 prototype layer 을 시각화해서
- 어떤 프로토타입과 유사도가 가장 강했는지
- 그 프로토타입은 원 이미지의 어느 부분에 activation 이 되었는지
- 그 프로토타입의 출처는 어딘지
를 알아볼 수 있어야 한다. 저번 포스트에서 간단한 그림을 첨부했는데,
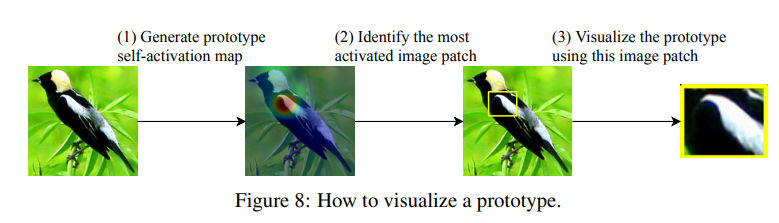
프로토타입은 activation map 을 생성하고, activation 의 95%를 커버하는 직사각형을 그려서 시각화한다고 했었다. 오늘은 이러한 코드가 작성되어있는 local_analysis.py 파일을 분석해보도록 하자.
오늘은 내가 공부하고있는 뇌 종양 데이터 을 예시로 들도록 하겠다. Binary classification (종양 유무) 문제이다.
1. 준비물
- 모델 (ppnet_multi)
- 입력 이미지 (images_test, [1, 1, 288, 288])
- 출력용 이미지 (original_img, [288, 288, 3])
import os
import torch
import skimage.io as sio
load_model_dir = './saved_models/resnet18/005/'
load_model_name = '25_2push0.6515.pth'
test_image_dir = './saved_models/resnet18/005/img/epoch-25'
test_image_name = 'prototype-img-original34.png'
load_model_path = os.path.join(load_model_dir, load_model_name)
ppnet = torch.load(load_model_path)
ppnet = ppnet.cuda()
ppnet_multi = torch.nn.DataParallel(ppnet)
test_image_path = os.path.join(test_image_dir, test_image_name)
images_test = sio.imread(test_image_path, as_gray=True)grayscale 로 불러왔으니 (288, 288) 로 나온다. 모델에 넣으려면 (batch_size, channel, 288, 288) 로 만들어야 하니 센스있게 unsqueeze 두번 때리고 텐서로 만들어주자.
아.. 그리고 이미지에 activation 씌워서 출력해야하니 (288, 288, 3) 모양을 가진 이미지를 준비해 주자. PILLOW나 cv2나 (h, w, c) 형식을 다루기 때문이다..
from einops import repeat
# 딥러닝 연구원이면 이정도는 할 줄 알잖아?
original_img = repeat(img_pil[np.newaxis, :], 'c h w -> h w (tile c)', tile=3)2. Forward model
준비가 되었으면 이미지를 모델에 넣어서 prototype activation 을 구해주자.
logits, min_distances, _ = ppnet_multi(images_test)
conv_output, distances = ppnet.push_forward(images_test)
prototype_activations = ppnet.distance_2_similarity(min_distances)
prototype_activation_patterns = ppnet.distance_2_similarity(distances)- prototype_activations ([1, 40])
왜 40일까? prototype이 40개니까! 이 문제는 binary classification 이라고 했으니까, 각 클래스마다 20개의 프로토타입이 들어있는 셈이다. 이 prototype_activations 에 weights 를 곱해서 최종 classification 을 한다.
- prototype_activations_patterns (1, 40, 9, 9)
하지만 1. 의 정보만으로는 activation 을 시각화할 수 없다. 위는 min_distance 만을 가지고 만들었기 때문에 공간정보가 손실되었기 때문이다. 따라서, 최종 feature map 의 [9, 9] shape 를 유지한 prototype similarity 를 따로 저장해서 후에 upsampling 을 통해 activation 을 시각화한다.
3. Nearest prototypes
두 가지를 시각화해야 한다. 잠깐 이전의 새 사진으로 돌아가보자..

- top-k_activated prototype (사진의 2, 3번째 열)
prototype_activation 에서 가장 높은 유사도를 가진 k개의 프로토타입의 원본 영상과 그 영상의 self activation 을 시각화한다.
- prototype activation (사진의 1, 4번째 열)
입력된 이미지에서 어느 부분이 prototype 와 연관되어있는지 시각화하는 작업이다.
가보자!
Part A: 프로토타입의 기원
코드에선 프로토타입마다 5개의 파일을 생성한다.
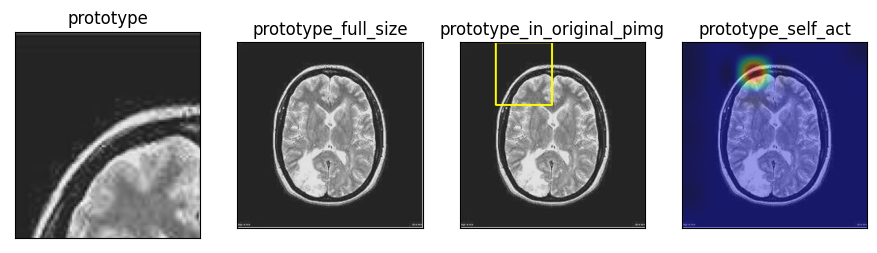
이렇게 프로토타입과 관련된 사진 네장과, top-k_activated_prototype.txt 라는 파일인데, 파일엔
similarity: 0.700
last layer connection with predicted class: 0.958
proto index:0
proto connection to class 0:tensor(0.9584, device='cuda:0', grad_fn=<SelectBackward0>)
proto connection to class 1:tensor(0.0416, device='cuda:0', grad_fn=<SelectBackward0>)
prediction 에 사용된 정보와 몇번째 프로토타입인지가 적혀있다.
만드는 방법은 쉽다. 네트워크 훈련 중 push 단계에서 이미 프로토타입에 대한 정보를 적어놓았기 때문에, 몇번째 프로토타입인지 알아내기만 하면 관련된 정보를 쉽게 찾을 수 있다.
array_act, sorted_indices_act = torch.sort(prototype_activations[idx])prototype_activations 벡터를 오름차순으로 정렬하면, 맨 뒤에서부터 유사도가 가장 높은 프로토타입이 되겠다!
for i in range(1,6):
index = sorted_indices_act[-i]따라서, sorted_indices_act 벡터를 뒤에서부터 접근하면 유사도가 i번째로 높은 프로토타입의 index를 구할 수 있다.
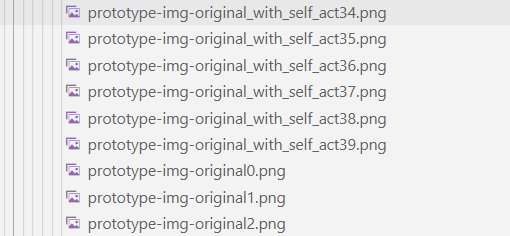
할일은 끝났다. 모델을 훈련할 때 push epoch 마다 프로토타입에 대한 정보를 위의 사진과 같이 폴더에 저장해주었으니, 경로를 따라가서 접근만 해주면 되겠다. Part A 에서 사용하는 정보는 다음과 같다.
- prototype-img<index>.png (push.py 의 proto_img_j)
위의 4장의 이미지중 첫번째 (prototype) 와 동일한 사진
- prototype-img-original<index>.png (push.py 의 original_img_j)
2번째와 동일한 사진
- prototype-img-original_with_self_act<index>.png (push.py 의 overlayed_original_img_j)
4번째와 동일한 사진
- bb<epoch>.npy (push.py 의 proto_bound_boxes)
모든 프로토타입의 bounding box 의 정보가 들어있음.
array([[1997, 0, 98, 55, 143, 0],
[1782, 0, 249, 0, 40, 0],
...
[ 885, 0, 199, 0, 44, 1],
[ 892, 0, 236, 0, 47, 1]])
각 행은 [전체 train set에서 몇번째인지, y1, y2, x1, x2, label] 을 뜻한다.
Part B: 입력 이미지 속의 프로토타입
activation_pattern = prototype_activation_patterns[idx][sorted_indices_act[-i].item()].detach().cpu().numpy()
upsampled_activation_pattern = cv2.resize(activation_pattern, dsize=(img_size, img_size), interpolation=cv2.INTER_CUBIC)Part B 는 activation_pattern 을 upsampled_activation_pattern 로 만든 것을 주로 사용한다.
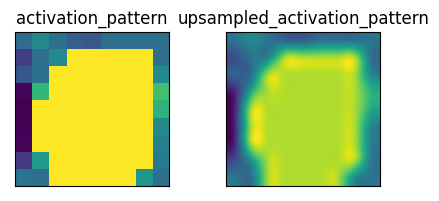
벌써부터 망한거 같은 느낌이 들면.. 맞다. 이 모델은 망한 모델이다. 왜냐고? 위에 이 프로토타입은 영상의 전체가 아닌 일부만을 activation 했기 때문이다.

입력 이미지에 activation map 을 씌운 모습이다. 위에서 보여준 프로토타입과 다시 대조해보자.
변명의 여지가 없이 망한 모델이다.
사실 마지막 feature map 에서의 activation 을 그대로 upsample 하는 것이 타당한지는 잘 모르겠다. 망이 깊으면 한 픽셀의 receptive field 가 굉장히 넓어지기 때문에, 최종적으로 activation 된 곳이 사실은 이미지의 다른 부분에서 시작했을 수 있다고 생각하기 때문이다. 다음 포스트에서는 모델을 조금 더 고도화하여 타당성 있는 프로토타입을 시각화 해 보도록 하겠다.
