아... Chest CT 로 text-to-image 모델 훈련하는거 너무 힘듬 ㅜㅜ
Prompt: "Massive pleural effusion is observed on the left. There is a total loss of aeration in the left lung. There is no pleural effusion on the right."
이런식으로 해서 만들어봤는데,
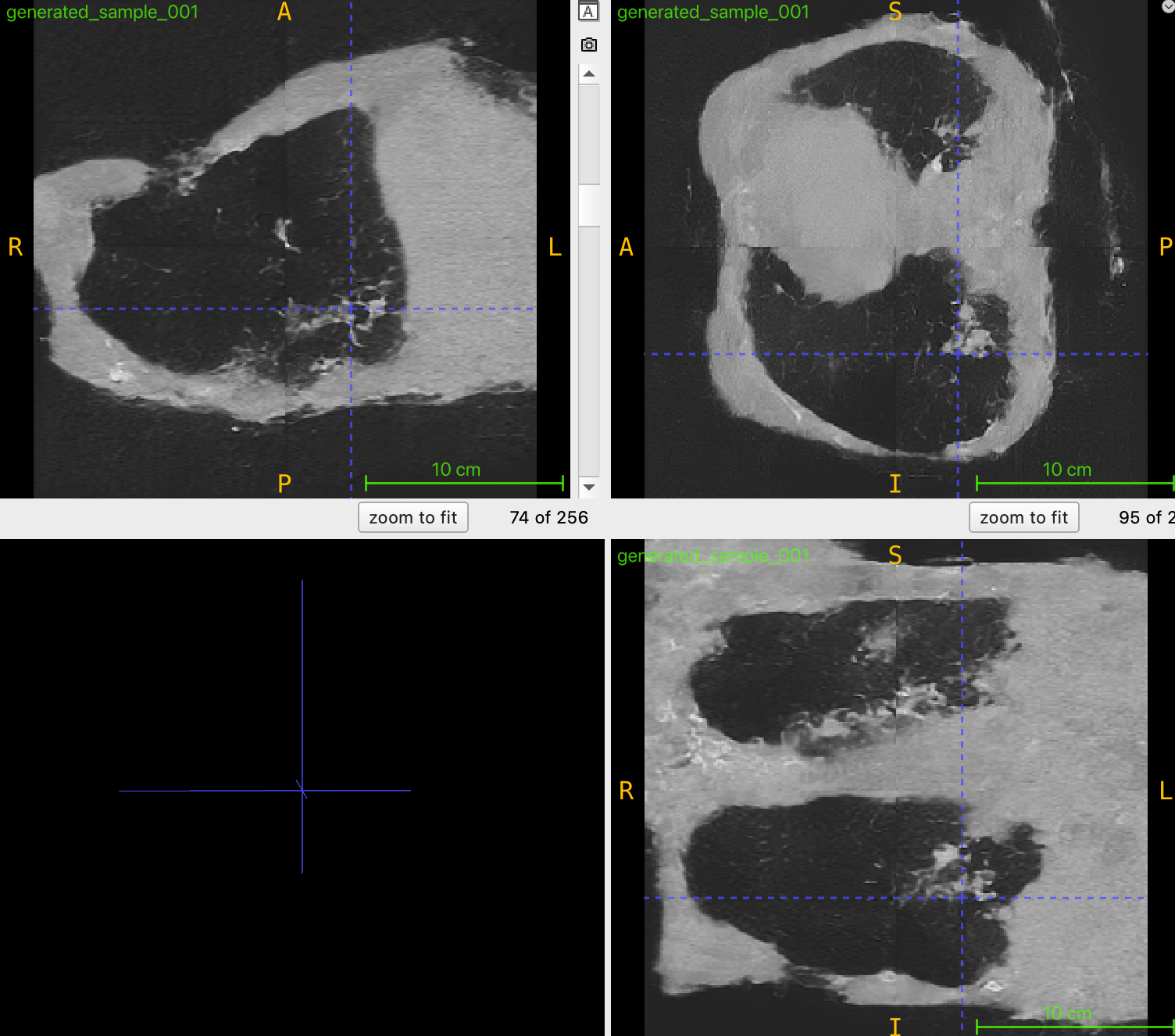
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ.. 퀄리티가 이상한건 그렇다 치고, 왼쪽에 massive pleural effusion 은 어디감??
뭔가 훈련 스킴에 문제가 있다고 생각이 들었음. 범인은 아래 두 시나리오 중 하나라고 생각함.
- VAE 훈련이 어렵기 때문에 Latent diffusion model가 적합하지 않다.
- Radiologists findings 에 detail 이 너무 personalize 되어있어서 general 한 representation 의 학습이 어렵다.
물론 근본적으로는 데이터가 20,000 개 가량밖에 없어서 그런거긴 하지만, 그래도 뭔가 작동하는 모델 만들기는 충분하지 않은가?
어쨌든, 다른 사람들은 어떻게 했는지 진지하게 살펴볼 필요가 있다고 느껴서 논문 리뷰를 시작함.
GenerateCT
데이터 전처리
CT-RATE 사용했다. 데이터는 (512, 512, 201) 로 고정한다.
{age} years old {sex}: {impression}
프롬프트가 특이한데, findings 를 아예 안쓰고 그냥 환자 정보에 바로 impression 을 썼다 (!!). 이게 왜 의외냐면, findings 에 CT 에 관한 정보가 다 들어있기 때문이다... 어디에 무슨 병이 있는지, 크기는 어느정도인지 다 써놓는데, impression 에는 그런 정보가 없다. 그치만, 오히려 findings 가 너무 복잡해서 훈련이 안될 수 있다는 내 가설에 힘을 실어주는 전처리 방식이다.
Text prompt 는 T5 encoder 을 활용하여 처리한다.
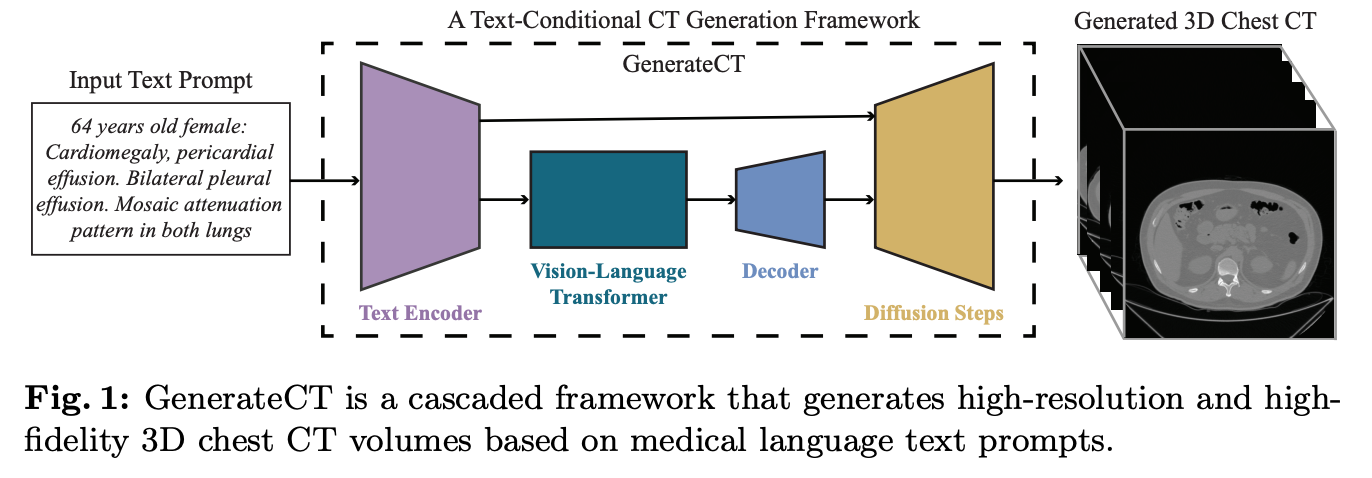
GenerateCT
CT-ViT
3D CT volume 을 인코딩하는 역할. (Latent representation 쓰겠다는 거죠?)
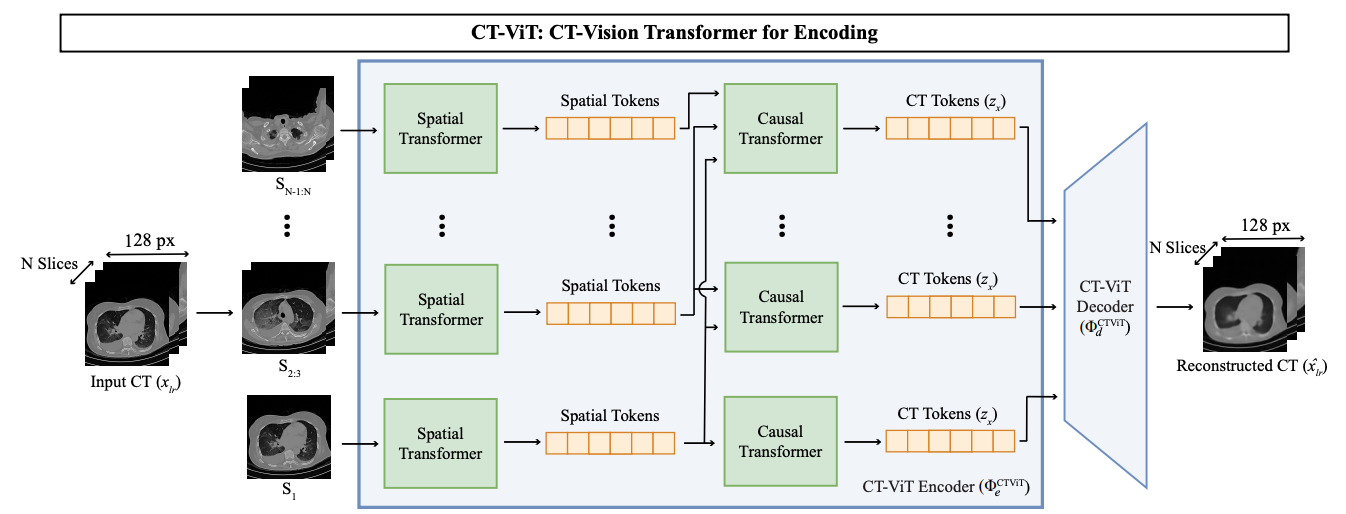
딱 보니 ViViT (video vision transformer) 쓴 티가 남.
- Patchfy: CT volume 을 (201) x 128 x 128 로 downsample 한 뒤, 첫 장은 16 x 16 patches 로 나누고, 그 뒤부터는 2 x 16 x 16 패치로 나눔. 즉 output embedded CT tokens 는 (101) x 8 x 8.
- Training objective: Reconstruction (L2) + perceptual loss + adversarial loss + vector quantization loss
Masked generative image-text transformer
Masked autoencoder 마냥 Patch 를 마스킹한다음에 self attention + text 와의 cross attention 을 통해 복구하는 작업.
masked_input = torch.where(mask_token_mask, self.mask_id, video_codebook_ids)
masked_input, = unpack(masked_input, packed_shape, 'b *')
maskgit_forward_context = torch.no_grad if only_train_critic else nullcontext
with maskgit_forward_context():
logits = self.maskgit(
masked_input,
video_mask = video_mask,
cond_drop_prob = cond_drop_prob,
text_mask = text_mask,
context = text_embeds
)또 하나 critic loss 라는 게 있다. Video codebook ID sequences 가 real 인지 generated 인지 확인해주는 (약간 spelling checker 느낌? 이라고 생각하면 될듯) 녀석인데, transformer architecture 을 활용해서 self attention + text report 와의 cross attention 을 활용해서 각 패치마다 logit 을 뽑아준다. Real / generated 여부는
critic_labels = (video_codebook_ids != pred_video_ids).float()으로 코드북 일치 여부를 통해 알아낸다.
Text-conditional diffusion models for super-resolution
마지막으로는 diffusion-based super-resolution model 이다. 128 x 128 슬라이스들을 512 x 512 로 upsampling 하는 과정이다. 이 때,
- Bottleneck stage 에서 T5 embedded text token 과의 cross-attention layer 이 있음. Low resolution image 에도 condition 함
Results
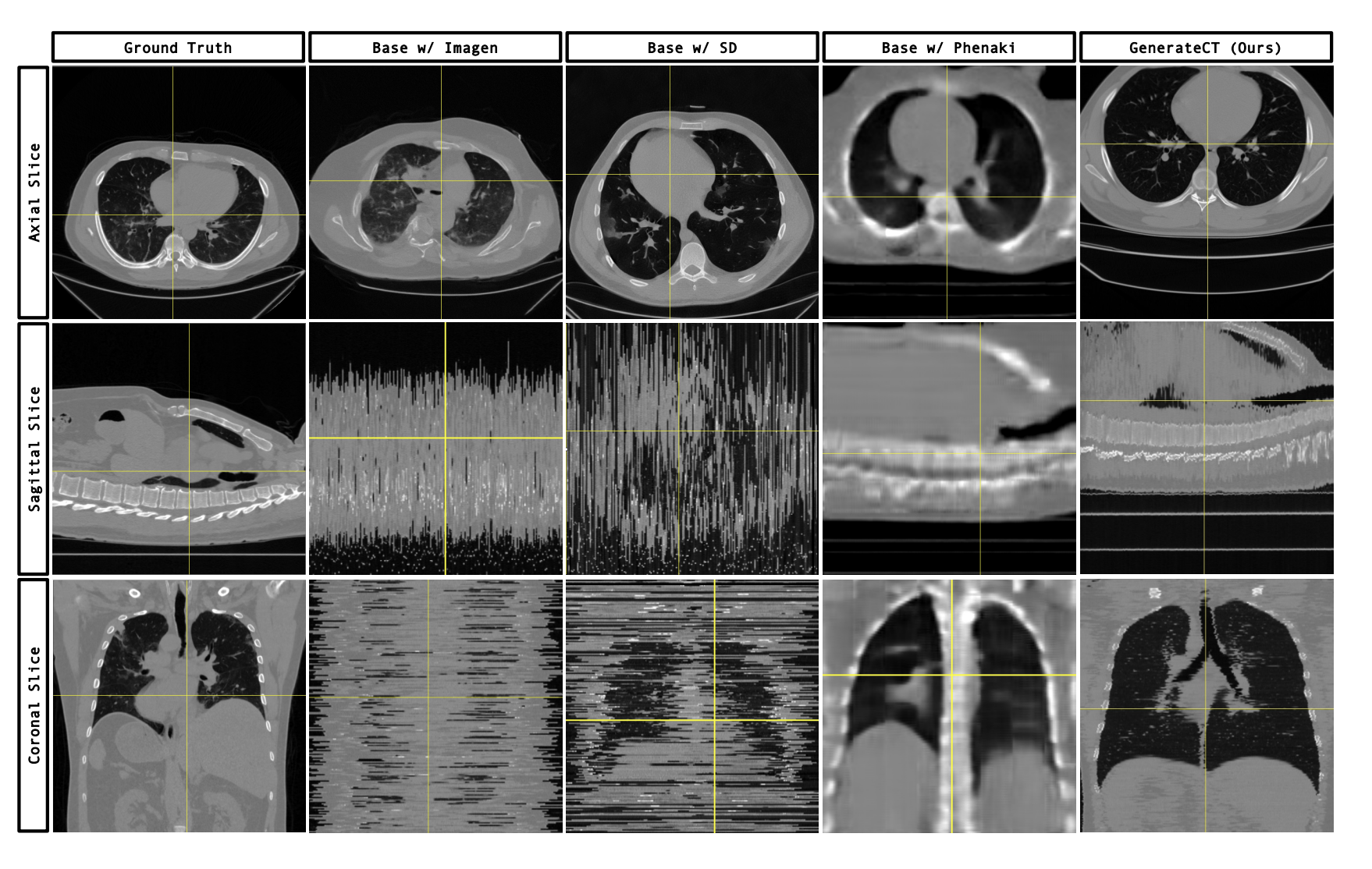
- 초기 연구다 보니 baseline 이 다 약한 모습을 보임. 다 2D 기반이며, GenerateCT 조차 axial slice artifact 가 있음.
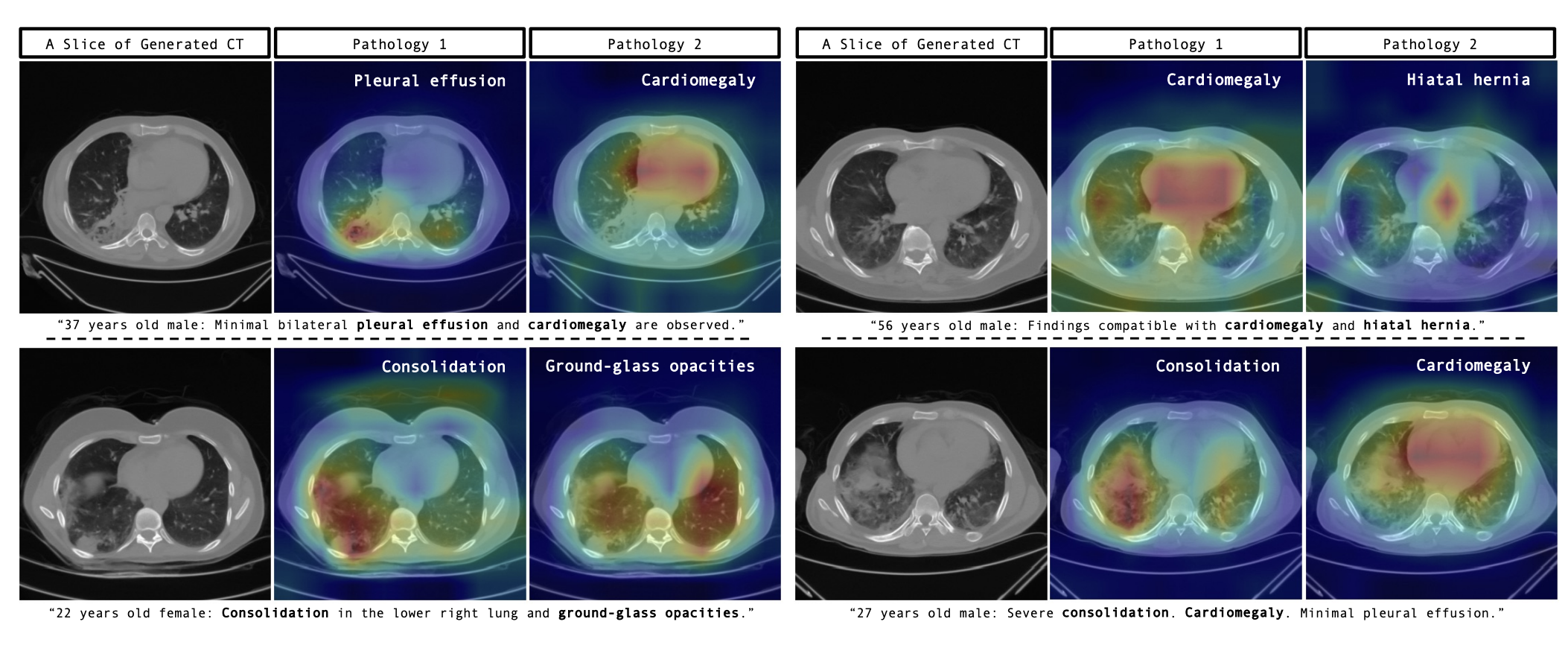
- Cross attention map 이 의외로 볼만한데, pleural effusion 과 cardiomegaly 를 각각 따로따로 localize 할 수 있음을 보인다. 물론 attention map 이 굉장히 coarse 해서 lung nodule 같이 조그만한 것은 할 수 없었던 것으로 보인다.
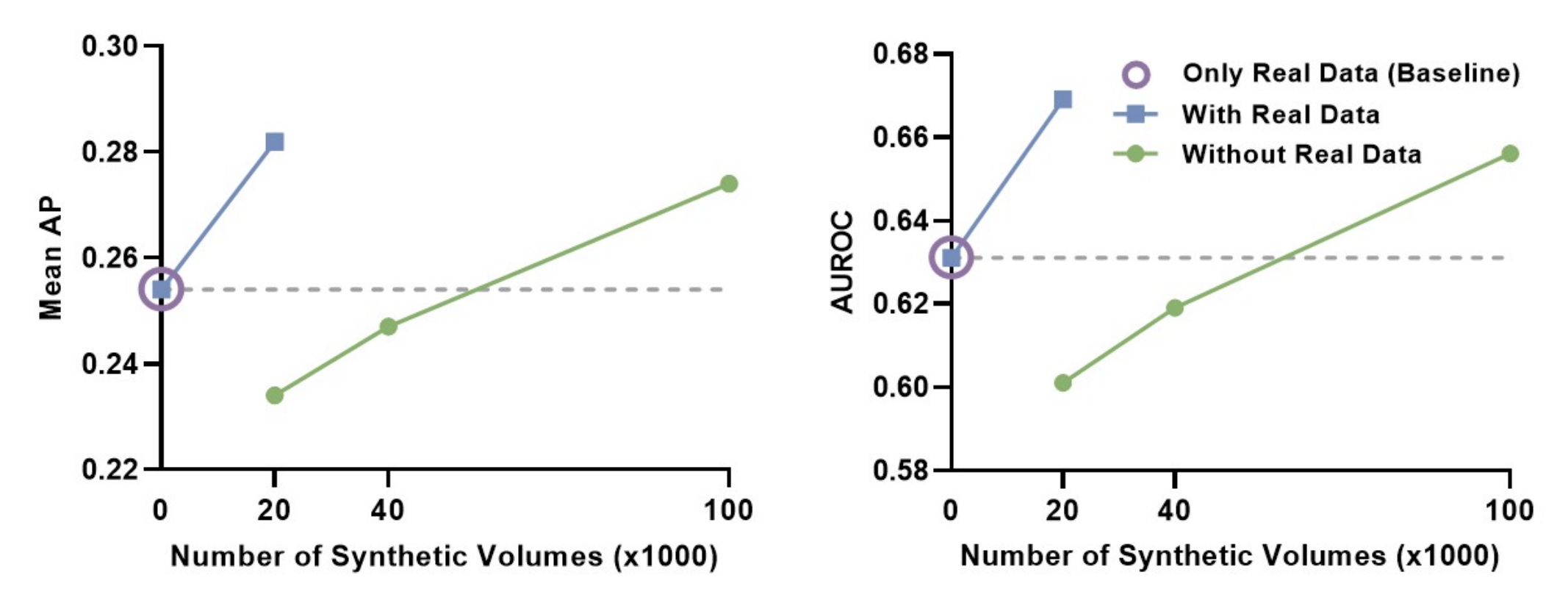
- 마지막은 text-to-image diffusion model 에서 단골로 등장할 결과물인 classification model performance 이다.
- 주요 논리는 text-to-image model 을 활용해 augmentation 을 했을 때 AUROC (classifcation metric) 이 올라간다는 내용인데, real data + 20000 synthetic volume 을 활용했을 때 AUROC가 0.63에서 0.67로 증가했다 (물론 그래도 임상에서 쓸만한 퍼포먼스는 아니다..)
Key takeaways
- 첫 text-to-CT model 이며, Video transformer + T5 encoder 을 활용했다.
- 이 때문인가? slice artifact 가 온전히 해결되지 못했다. - Impression 부분만을 사용했기 때문에 radiologist report 를 온전히 활용하지 못한 단점이 있다.
- 훈련이 1주일 (...) 이나 걸리며, 더 효율적인 훈련 구현이 필요해 보인다.
