어쩌다 https://github.com/fanconic/this-does-not-look-like-that 를 보게 되었다.
local_analysis_attack1.ipynb
이 노트북의 목적은 PGD (Towards Deep Learning Models Resistant to Adversarial Attacks에 등장) 사용해서 모델이 중요하게 보았던 패치에 변형 (perturbation) 을 최소한으로 가했을 때, prototype 이 전혀 중요하지 않은 곳으로 부터 나올 수 있게 만들 수 있다는 것을 보여주기 위함이다.

사진의 일부분에 아주 약간의 perturbation 만 가한 모습이다. 대충보면 잘 판별이 가지 않을정도로 minimal하다.

이럼에도 말도안되는 곳에서 높은 prototype similarity 를 구한다! ProtoPNet의 약점인 셈이다.
근데 ProtoPNet이 뭐길래 이런 연구를 했을까..?
1. ProtoPNet 의 구조
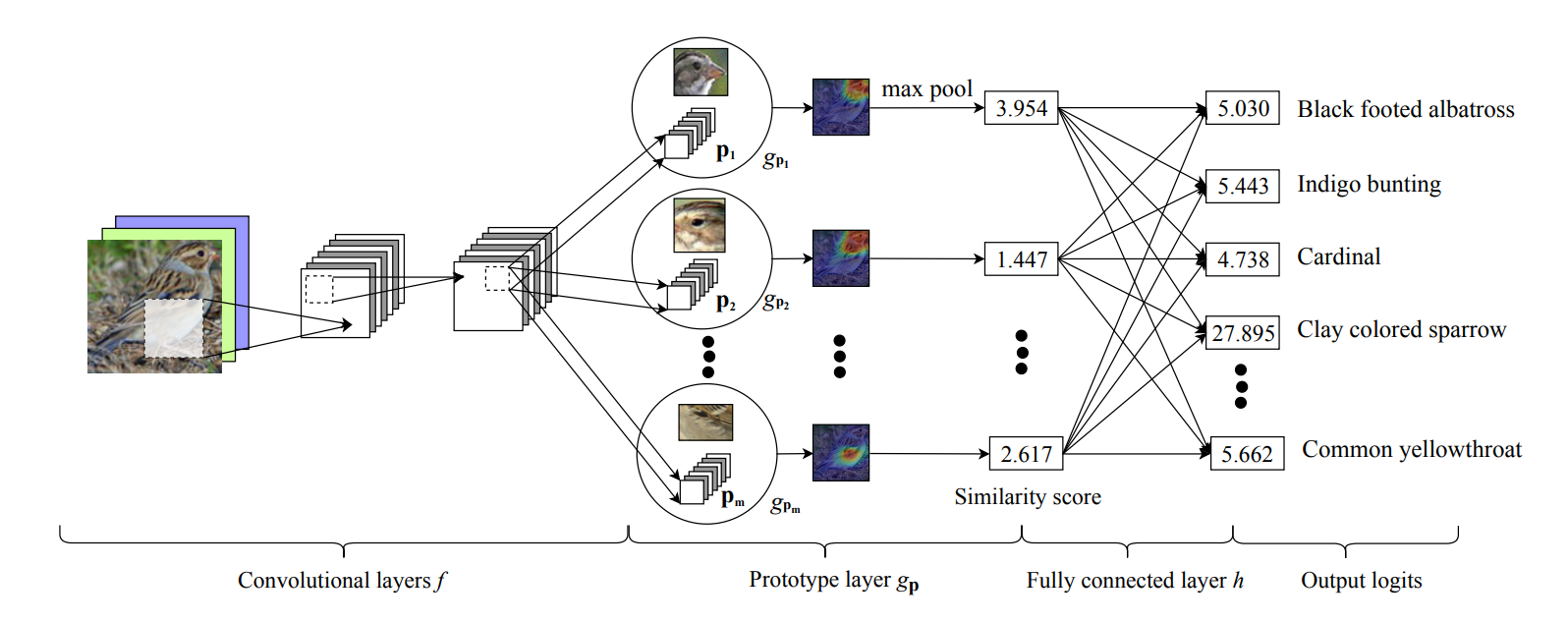
ProtoPNet의 구조는 (1) convolutional layer, (2) prototype layer, (3) fully connected layer 로 나눌 수 있다.
- Convolutional layer
직관적인 합성곱 신경망의 구조이다. 임의의 이미지에서 특징을 추출하는 목적을 가진다.
원논문에서는 ImageNet-pretrained VGG, ResNet, DenseNet 을 비교했으며, 위의 노트북에서는 resnet18 을 사용했다. 간단히 입력과 출력만 보자면,
Input: [n, 3, 224, 224]
Output: [n, 512, 7, 7]
이 되겠다.
여기에 add_on_layers 를 사용하면 (channel 수를 줄이기 위함) 최종 conv_features (line 182) 는 [n, 128, 7, 7] 이 된다. *add_on_layers 의 채널 수는 supplementary 23페이지 하단에서 찾을 수 있음.
- Prototype layer
conv_features 를 라고 정의하자. Prototype layer 에 있는 j번째 프로토타입 (총 m=2000개) 는 에 있는 모든 같은 모양의 patch 와의 거리를 계산할 것이다. conv_features 의 spatial shape 가 [7, 7] 이였으니 한개의 프로토타입이 [1, 1] 이라고 할 때 총 49군데에서 거리를 계산하는 셈이다.
49군데에서 거리를 계산한 뒤 global min pooling 을 사용해 제일 낮은 거리 min_distance 만을 남긴다 (왠진 모르겠는데 distance 에 -1을 곱하고 max pooling 을 한 뒤 -1을 다시 곱했다. min pooling 이 없나?). 이와 같은 작업을 2000개의 프로토타입에 모두 수행하니, 이 단계를 지나면 min_distances ([1, 2000]) 이 남는다. 이 거리들을 log를 사용해 유사도 (similarity) 로 변환해주면 최종 output이 나온다.
왜 거리로 바꿔주는진 모르겠으나, 논문에선 가 거리에 대해 monotonically decreasing 이라는 점을 강조한다. 물론, 이는 latent space 에서의 유사도이기 때문에 input space 상에서의 유사도를 보장하지는 않는다!
마지막으로, 프로토타입의 수가 2000인 이유는 각 class 마다 (200개) 10개의 프로토타입을 부여했기 때문이다. 즉, 프로토타입의 수는 hyperparameter이다!
- Fully connected layer
단순한 fc layer. Bias와 ReLU가 없다! 이는 단순히 어떤 이미지에서 A의 프로토타입이 발견되었다면 A의 점수를 추가하고, B의 프로토타입이 발견되었다면 A의 점수는 낮추고 B의 점수를 올린다는 의도이다.
2. Training ProtoPNet
구조를 알아보았으니 훈련을 어떻게 시키는지 알아보자.
ProtoPNet 의 훈련은 (1) 마지막 층 전까지의 층에 대해 SGD, (2) 프로토타입의 정사영 (projection), (3) 마지막 층의 볼록 최적화로 나눌 수 있다.
(1) SGD of layers before last layer
첫 stage 는 이미지를 분류하기 위한 유의미한 latent space를 학습하는 것이 목표이다. 즉, 각 클래스의 특징을 가장 잘 표현하는 프로토타입을 학습하는 것이다. 프로토타입이 새 한마리마다 10개씩 있었으니, 같은 새를 표현하는 10개의 프로토타입은 latent space 상에서 가까이 뭉쳐있어야 할 것이며 (L2 distance 기준), 다른 프로토타입과는 멀리 떨어져 있도록 학습시킬 것이다. 이를 위해 convolutional layer 의 가중치 와 프로토타입 을 같이 (jointly) 학습할 것이다. 이미지에서 새의 특징을 잘 추출하게 하는 동시에, 그 특징들이 다른 새에서는 나타나지 않도록 유도하는 것이다. 즉, 다음과 같은 최적화 문제가 정의된다.

나는 이 즈음 '어.. 그럼 어떻게 한 클래스당 10개의 프로토타입을 고정할 수 있는거지..?' 라는 의문을 가지게 되었는데, 이 stage 에서 마지막 fully connected layer 은 고정된 상태로 진행된다. 같은 클래스의 프로토타입은 1의 가중치를 가질 것이고, 다른 클래스의 프로토타입은 -0.5 의 가중치를 가지게 된다.
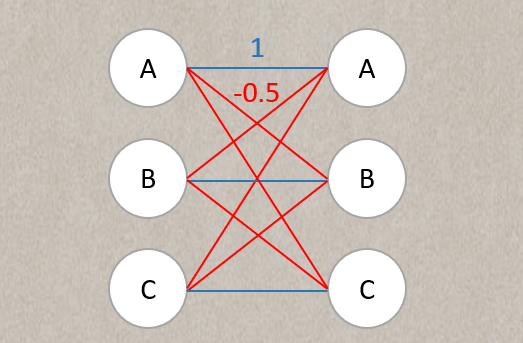
마치 이 그림처럼. 그렇다면, 여기서 각 클래스당 10개씩 1의 가중치를 가진 프로토타입 뉴런을 지정해주면 그만이다!
(2) Prototype Projection
프로토타입은 [128, 1, 1] 의 latent patch 일 뿐이고! 이걸 실제로 훈련에 사용된 이미지와 연관지으려면 정사영 (projection) 을 수행할 필요가 있다. 마치 Grad-CAM 처럼. 그래서, 우리는 프로토타입을 *같은 클래스* 에서 가장 가까이 있는 latent training patch 와 연결시키는 작업이 필요하겠다.
수식이랍시고 이렇게 적어 놨는데, 모든 패치 (즉 class k의 모든 이미지를 conv layer 에 때려박은 뒤 나온 패치들) 들 중 가장 비슷한놈 찾으란 거다. latent space상에서. (이게.. 문제가 될 수 있겠지? ^^)
자. 그래서 프로토타입 는 f(x) 의 latent representation 중 한 패치와 똑같다. 즉, 를 시각화하기 위해서는 그 패치가 만들어진 x 를 모델에 입력한 뒤 나온 activation map 을 upsampling 하면 된다! (아래 그림의 step 1)
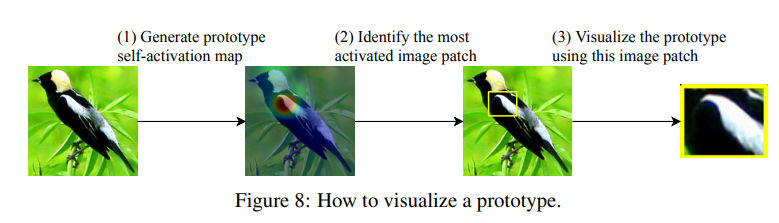
Activation map 을 구했다면, 그 activation 의 95%를 포함하는 네모난 영역을 prototype patch 로 시각화한다.
Push 에 사용되는 코드를 조금 살펴보자.
# update each prototype for current search batch
def update_prototypes_on_batch(search_batch_input,
start_index_of_search_batch,
prototype_network_parallel,
global_min_proto_dist, # this will be updated
global_min_fmap_patches, # this will be updated
proto_rf_boxes, # this will be updated
proto_bound_boxes, # this will be updated
class_specific=True,
search_y=None, # required if class_specific == True
num_classes=None, # required if class_specific == True
preprocess_input_function=None,
prototype_layer_stride=1):
'''
push_forward 는 conv_output, distances 를 output
protoL_input_ : (75, 128, 7, 7)
proto_dist_ : (75, 2000, 7, 7)
'''
protoL_input_, proto_dist_ = prototype_network_parallel.push_forward(search_batch_input)
# 각 class 마다 img 의 리스트를 index 로 넣어줌
if class_specific:
class_to_img_index_dict = {key: [] for key in range(num_classes)}
# img_y is the image's integer label
for img_index, img_y in enumerate(search_y):
img_label = img_y.item()
class_to_img_index_dict[img_label].append(img_index)
# (2000, 128, 1, 1)
prototype_shape = prototype_network_parallel.module.prototype_shape
n_prototypes, proto_h, proto_w = (2000, 1, 1)
max_dist = prototype_shape[1] * prototype_shape[2] * prototype_shape[3] # 128
# 2000개의 프로토타입에 대해 각각 push 진행
for j in range(n_prototypes):
# 방금 class : [idx1, idx2, ...] 꼴로 처리를 했으니 각 프로토타입이 속해있는 클래스의 모든 이미지와의 거리를 proto_dist_j 에 저장함
'''
proto_dist 가 (75, 2000, 7, 7) 이였다.
proto_dist_j 는 프로토타입 j 가 속해있는 클래스의 모든 이미지 (보통 30장이나 15장) 과 그 프로토타입의 거리를 담은 배열임.
class_to_img_index_dict 가 {0: [0, 1, 2, 3, 4], 1: [5, ..., 24], 2: [], 3: [25, ..., 74]} 같이 있다고 치고, target_class 가 0 이라면,
proto_dist_j 는 배치의 [0, 1, 2, 3, 4] 번째 이미지와의 거리를 포함하는 것임.
'''
if class_specific:
# target_class is the class of the class_specific prototype
target_class = torch.argmax(prototype_network_parallel.module.prototype_class_identity[j]).item()
# if there is not images of the target_class from this batch
# we go on to the next prototype
if len(class_to_img_index_dict[target_class]) == 0:
continue
proto_dist_j = proto_dist_[class_to_img_index_dict[target_class]][:,j,:,:]
else:
# if it is not class specific, then we will search through
# every example
proto_dist_j = proto_dist_[:,j,:,:]
# 지금 배치에서 minimum distance 를 batch_min_proto_dist_j 에 저장
batch_min_proto_dist_j = np.amin(proto_dist_j)
# 이 batch 에서 global minimum 이 나왔다면 update!
if batch_min_proto_dist_j < global_min_proto_dist[j]:
'''
먼저 그 배치에서 몇번째 이미지였는지부터 저장
np argmin: 으로 제일 distance 가 작은 이미지의 idx 를 찾음
np unravel_index: 그것이 원래 matrix에서 어디에 위치해있는지 역연산
예: [ [1,2,3] [4,5,6] ] 을 넣는다면, argmin 은 0 을 반환할 것이고,
np_unravel_index 를 사용하면 (0, 0) 으로 원래 좌표를 찾을 수 있을 것이다.
예를 들어,
proto_dist_j.shape = (15, 7, 7)
batch_argmin_proto_dist_j (6, 4, 0)
이렇게 나올 수 있는데, 이는 배치에서 6번째 idx 에 있는 사진의 (4, 0) 에 위치한
패치가 프로토타입 j 와 가장 가까운 거리를 가지고 있음을 뜻한다.
'''
batch_argmin_proto_dist_j = \
list(np.unravel_index(np.argmin(proto_dist_j, axis=None),
proto_dist_j.shape))
if class_specific:
'''
change the argmin index from the index among
images of the target class to the index in the entire search
batch
우리가 클래스 별로 있는 거리들만 계산해서 다시 모든 이미지 기준의 index 로 변환해줘야함
'''
batch_argmin_proto_dist_j[0] = class_to_img_index_dict[target_class][batch_argmin_proto_dist_j[0]]
# retrieve the corresponding feature map patch
# protoL_input_ (이미지들을 push 한 것) 에서 패치를 따와서 batch_min_fmap_patch_j 에다 저장
# [?] prototype_layer_stride 를 곱하는 이유는 아직 모르겠음
img_index_in_batch = batch_argmin_proto_dist_j[0]
fmap_height_start_index = batch_argmin_proto_dist_j[1] * prototype_layer_stride
fmap_height_end_index = fmap_height_start_index + proto_h
fmap_width_start_index = batch_argmin_proto_dist_j[2] * prototype_layer_stride
fmap_width_end_index = fmap_width_start_index + proto_w
# 방금 찾았던 이미지의 (6, 4) 가 패치에 저장되는 모습
batch_min_fmap_patch_j = protoL_input_[img_index_in_batch,
:,
fmap_height_start_index:fmap_height_end_index,
fmap_width_start_index:fmap_width_end_index]
global_min_proto_dist[j] = batch_min_proto_dist_j
global_min_fmap_patches[j] = batch_min_fmap_patch_j
# get the receptive field boundary of the image patch
# that generates the representation
# rf 는 receptive field 임
'''
protoL_rf_info: [7, 32, 435, 0.5]
rf_prototype_j: [13, 0, 224, 0, 218]
resnet 의 receptive field 가 굉장히 넓기 때문에 구하는 의미가 있나...? 싶음
'''
protoL_rf_info = prototype_network_parallel.module.proto_layer_rf_info
rf_prototype_j = compute_rf_prototype(search_batch.size(2), batch_argmin_proto_dist_j, protoL_rf_info)
# crop out the receptive field
rf_img_j = original_img_j[rf_prototype_j[1]:rf_prototype_j[2],
rf_prototype_j[3]:rf_prototype_j[4], :]
# find the highly activated region of the original image
# proto_act_img_j 에 activation 정보가 담겨있고 이걸 upsampling 해서 원 이미지의 사이즈에 맞춤.
proto_dist_img_j = proto_dist_[img_index_in_batch, j, :, :]
proto_act_img_j = np.log((proto_dist_img_j + 1) / (proto_dist_img_j + prototype_network_parallel.module.epsilon))
# 주의! ProtoPNet 은 새 이미지가 224, 224 여서 original_img_size 를 반복했으나, 이는 실제로 다를 수 있음.
upsampled_act_img_j = cv2.resize(proto_act_img_j, dsize=(original_img_size, original_img_size),
interpolation=cv2.INTER_CUBIC)
proto_bound_j = find_high_activation_crop(upsampled_act_img_j)
# crop out the image patch with high activation as prototype image
proto_img_j = original_img_j[proto_bound_j[0]:proto_bound_j[1],
proto_bound_j[2]:proto_bound_j[3], :]
Receptive Field Calculation
잠깐 receptive field 를 구하는 공식을 살펴보았다. 위에
rf_prototype_j = compute_rf_prototype(
search_batch.size(2),
batch_argmin_proto_dist_j,
protoL_rf_info)이 있었는데,
def compute_rf_prototype(img_size, prototype_patch_index, protoL_rf_info):
img_index = prototype_patch_index[0]
height_index = prototype_patch_index[1]
width_index = prototype_patch_index[2]
rf_indices = compute_rf_protoL_at_spatial_location(img_size,
height_index,
width_index,
protoL_rf_info)
return [img_index, rf_indices[0], rf_indices[1],
rf_indices[2], rf_indices[3]]
def compute_rf_protoL_at_spatial_location(img_size, height_index, width_index, protoL_rf_info):
n = protoL_rf_info[0]
j = protoL_rf_info[1]
r = protoL_rf_info[2]
start = protoL_rf_info[3]
print('n, j, r, start', n, j, r, start)
assert(height_index < n)
assert(width_index < n)
center_h = start + (height_index*j)
center_w = start + (width_index*j)
print('center_h, center_w', center_h, center_w)
rf_start_height_index = max(int(center_h - (r/2)), 0)
rf_end_height_index = min(int(center_h + (r/2)), img_size)
rf_start_width_index = max(int(center_w - (r/2)), 0)
rf_end_width_index = min(int(center_w + (r/2)), img_size)
return [rf_start_height_index, rf_end_height_index,
rf_start_width_index, rf_end_width_index]이 두개의 함수로 이루어져 있다.
먼저 parameter 부터 살펴보자.
search_batch.size(2) 는 224 가 들어간다. 이미지의 크기값이다.
batch_argmin_photo_dist_j 에는 [15, 1, 5] 같은 배열이 들어간다. 배치에서 15번째 사진의 (1, 5) 패치라는 뜻이다.
photoL_rf_info 엔 [7, 32, 435, 0.5] 이 들어간다. Conv feature map 이 7,7 이여서 7, downsampling 5번해서 2^5 = 32, 그리고 receptive size 435 인 것으로 추측된다.
(3) Convex Optimization
다른건 다 freeze 하고 마지막 fc layer 만 업데이트 하는 작업.
