Released: 2 Aug 2019
Previous Methods
Two branches
- Proposal based (Mask R-CNN)
High accuracy, but low resolution and fps
Also, spatial-invariance of FCN is nto suitable for embedding methods.
- Proposal free (discriminative loss)
Flexible but not so accurate
Spatial Embeddings
The loss function optimizes the iou of each object's mask.
During inference, instances are recovered by clustering around the learned centers.
Kendall et al. proposed to assign pixels to objects by pointing to its object's center (how?)
- Avoids spatial-invariance by learning position relative offset vetcors
Method
Instance segmentation = pixel assignment problem (classification?)
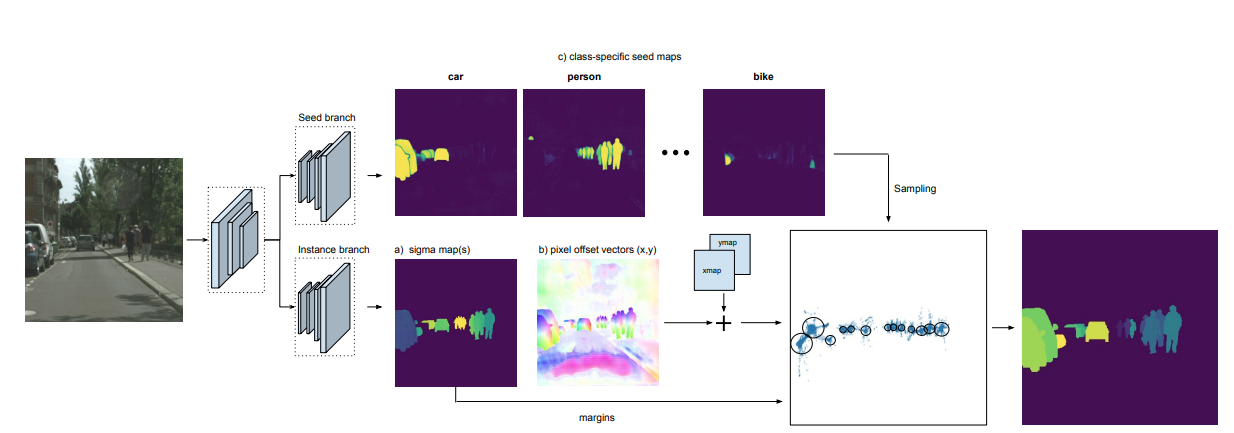
Segmentation pipeline is divided into two parts.
The upper part is responsible for predicting a seed map for each semantic class. High value indicates pointing to the center. border pixels have low value since they do not know where to point at.
The bottom part is responsible for predicting a sigma value for each pixel.
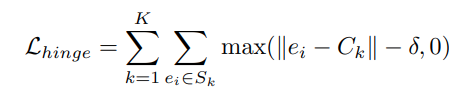
Regression loss with a hinge loss variant determines the margin delta such that smallest objects can be distinguished, but this means lower accuracies on the bigger objects.
Instead, we consider an instance specific margin: small margin should be used for small instances; bigger margin for bigger ones. This relaxes the loss for pixels further away.
Moreover, we use the Lovasz-hinge loss instead of the standard cross-entropy loss because Lovasz-hinge loss is piecewise linear.
Sigma is not direvctly supervised, but jointly optimized to maximize iou.
Loss를 조금 자세히 살펴보자면,
spatial_emb = torch.tanh(prediction[b, 0:2]) + xym_s # 2 x h x w
sigma = prediction[b, 2:2+self.n_sigma] # n_sigma x h x w
seed_map = torch.sigmoid(
prediction[b, 2+self.n_sigma:2+self.n_sigma + 1]) # 1 x h x wPrediction Tensor을 세 부분으로 나눈다
Spatial Embedding:
아마 feature map이 아닐까?
Sigma
각 인스턴스의 margin size로 추정된다. Sigma가 크다는 것은 그만큼 물체가 크다는 의미이기도 하다.
Seed Map
Loss Extensions
We can use 2-dimensional sigma to account for elongated objects such as a long stick.
Training
The model is first trained on 500x500 crops around objects to save computation time. Then, the model is finetuned for 1024x1024 crops to improve performance on large objects.
