그냥 아카이브 논문이긴 한데.. Text to image model 중 하나니 요약만 하려고 한다...
데이터셋
-
CT-RATE + RadChestCT (out-of-distribution evaluation, data-augmentation experiments)
-
FID for image quality, CLIP score for text-image alignment
전처리
- Llama-3-70B 로 리포트 정리
- Prompt 가 4종류가 있음 (general, demographics, findings, impression). LLM 으로 한번씩 processing 했다고 하는데 (pg 5, sec 3.1., "Td, Tf, Ti denote the augmented variants") supplementary에 이 부분은 자세히 작성되어있지 않음. 신기한건 list of organs 도 넣음 (왜?)
- Voxel spacing: 0.75 x 0.75 x 1.5 (512x512x192)
모델
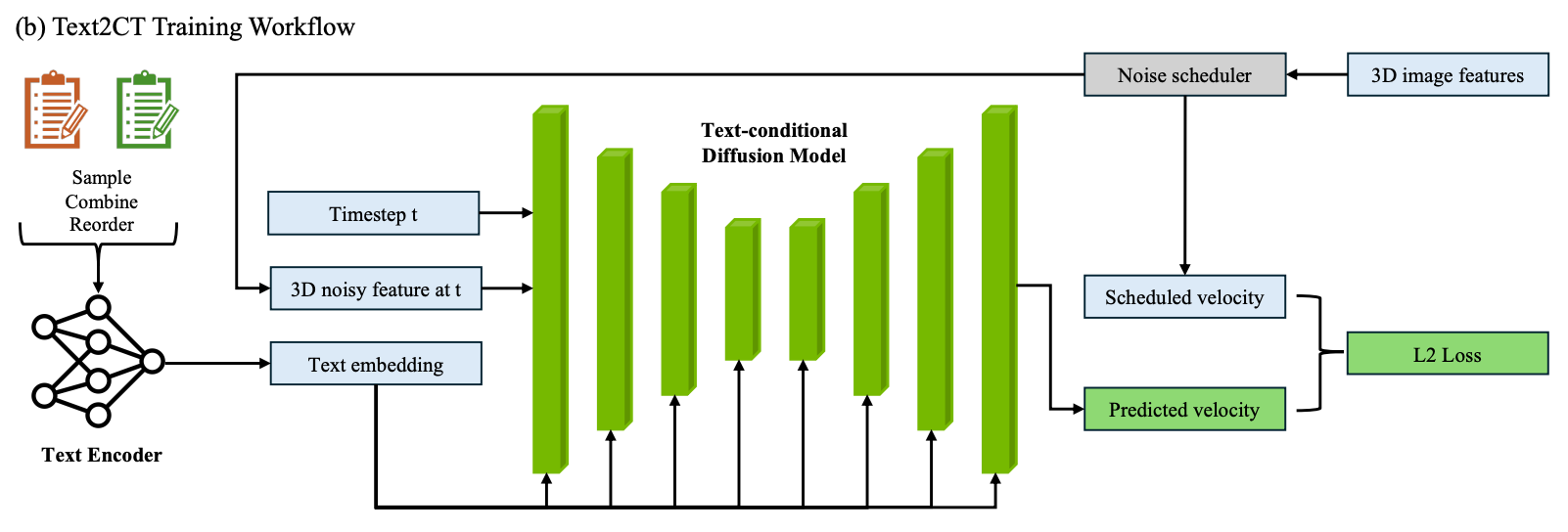
-
Text Encoder: Biomed-CLIP, T5
-
Image encoder: MAISI 4x downsampling. Tensor splitting parallelism for distributed GPU usage.
-
Training scheme:
- v-prediction
- U-Net with cross attention in every block
Results
뻔한 레파토리인 quantitative metrics (FID, CLIP Score) 은 생략
Data augmentation 성적도 딱히 감흥없어서 생략
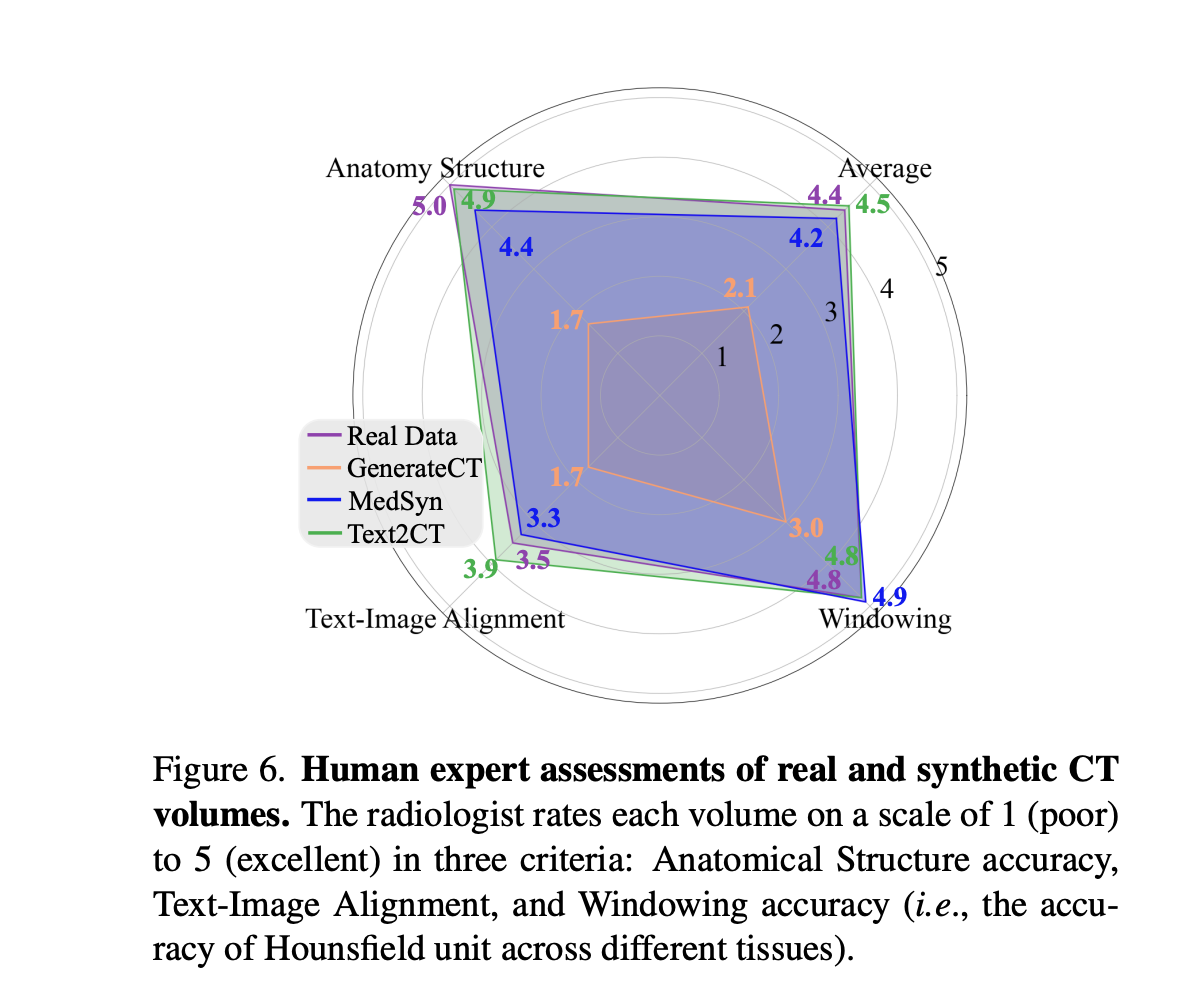
Human expert assessment 를 포함했는데 (2 radiologists), text-image alignment 가 real data 보다 점수가 높았음 (3.5 vs 3.9). 이거보고 스캠논문아닌가? 라는 생각이 들었음.
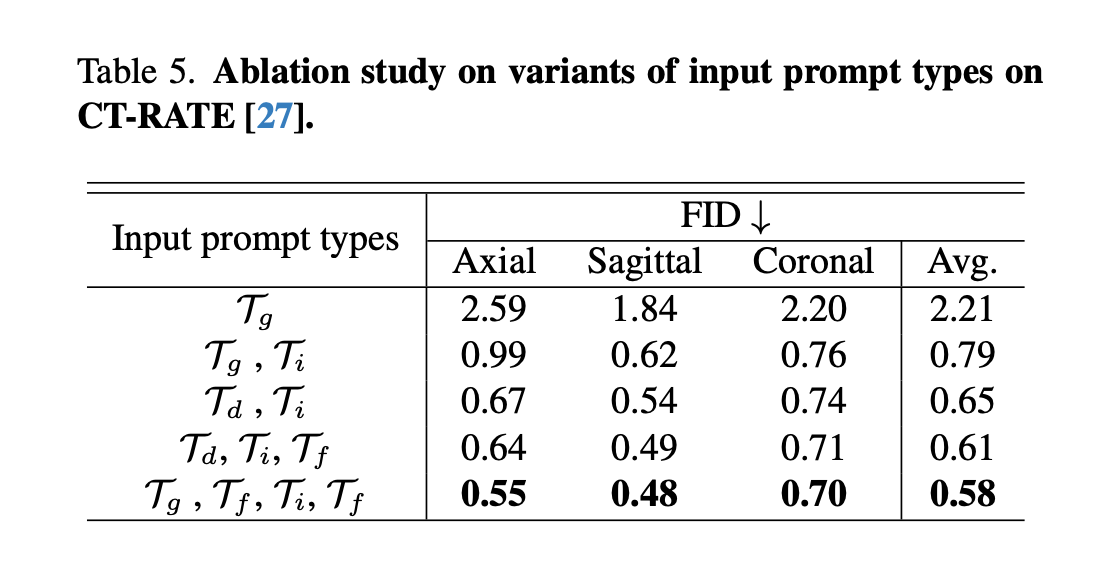
Input text prompt types ablation study 에서는 impression + demographics 조합의 FID 가 가장 유효하게 나왔음. 하지만, findings 에서 제공하는 정보가 제일 많은데, axial FID 가 0.03밖에 올라가지 않았다는 것은 아직 해당 테크닉이 findings section 의 정보를 다 반영하지 못한다는 것을 의미한다.
