이 논문도 T2I 논문이다. 근데 이 논문은 segmentation mask 까지 만들어준다!! 단순히 이미지를 생성하는 것을 넘어 segmentation dataset 증강을 노리는 것을 볼 수 있다.
데이터셋
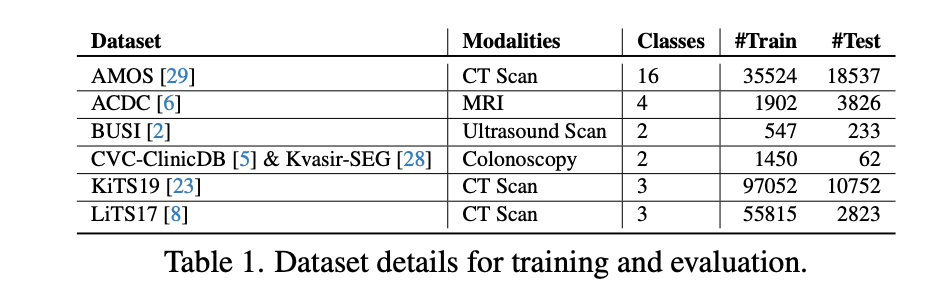
와 많이도 썼다!
- 이 논문은 2D 모델임 (256x256), 3D CT scan 같은건 axial slice 만 뽑아서 활용했음.
- CT, MRI, Ultrasound 를 활용함
- Text prompt 는 어떻게 만들었는지 명시안함. 아마 Class/structure names, modality, 그리고 segmentation mask 의 존재 등으로 만들지 않았을까 추측만 가능.
모델
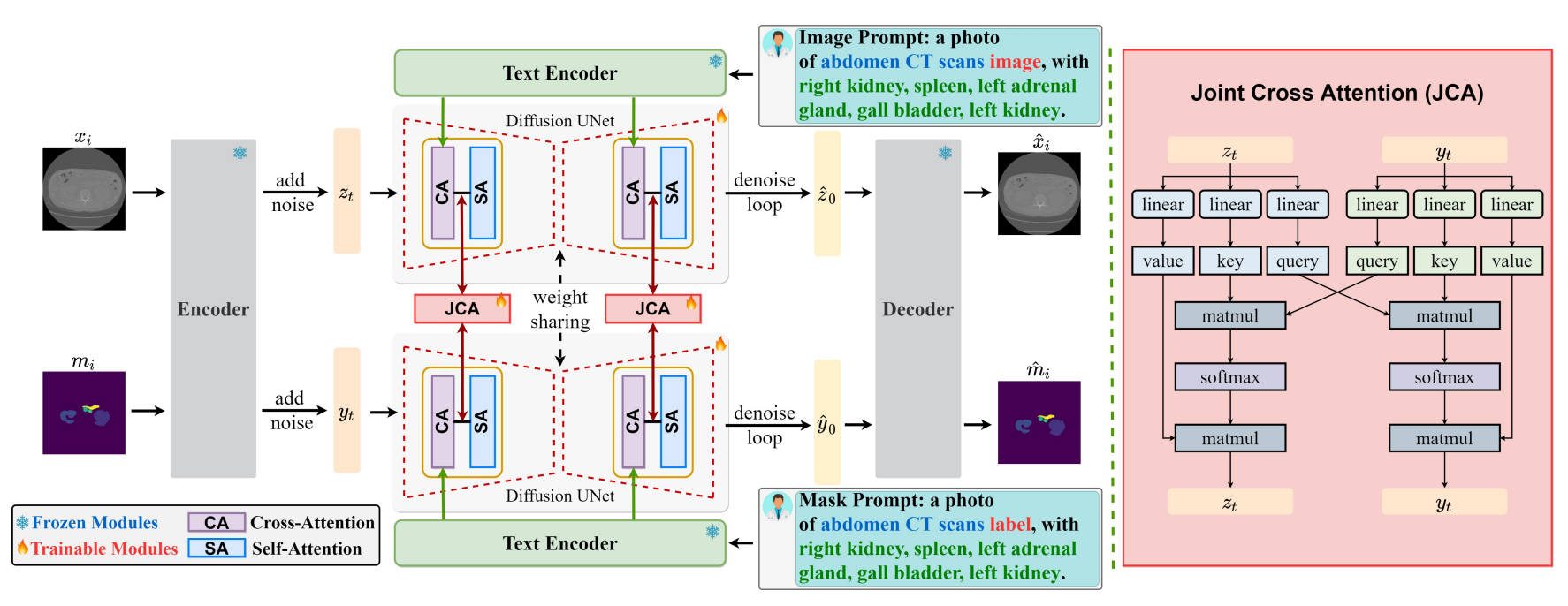
- Dual-stream generation framework: Image generation, mask generation 을 따로 수행하며, Cross attention과 self attention 사이에 Joint Cross Attention 을 수행함.
- Stable Diffusion-based backbone. VAE 도 stable diffusion 것을 사용함. Mask 그대로 encoding 해도 됐었을지는 의문.
- Text encoder: SD1.5 CLIP encoder (medical dataset 과 domain gap 있을 확률 높음)
- Joint Cross Attention: 각자 modality 가 query, 반대편 modality 가 key, value 임.
Implementation
- Classifier guidance (scale 7.5 for inference)
- 50 Step denoising process
- 4 A6000 GPUs, 300 epochs with. batch size of 20
Results
Quantitative Comparison
스킵. MAISI가 3D라고 포함안했는데 납득이 되는 부분인진 모르겠음.
Alignment
스킵. 다른 모델은 mask 랑 alignment 가 약하다는데 clinical 한 설명이 없음.
Diversity
같은 프롬프트로 여러번 돌린걸 보여줌. 유의미하긴한데, 실제로 가능한 영상인지 의문이고, 잘못된 영상은 얼마나 나오는지 알 수 없음.
Segmentation Performance
논문 메인. 다른 모델에 비해 DSC 를 올려줬다는 내용인데, 통계적으로 유의미한지 확인이 필요해보이긴 한다.
Limitations
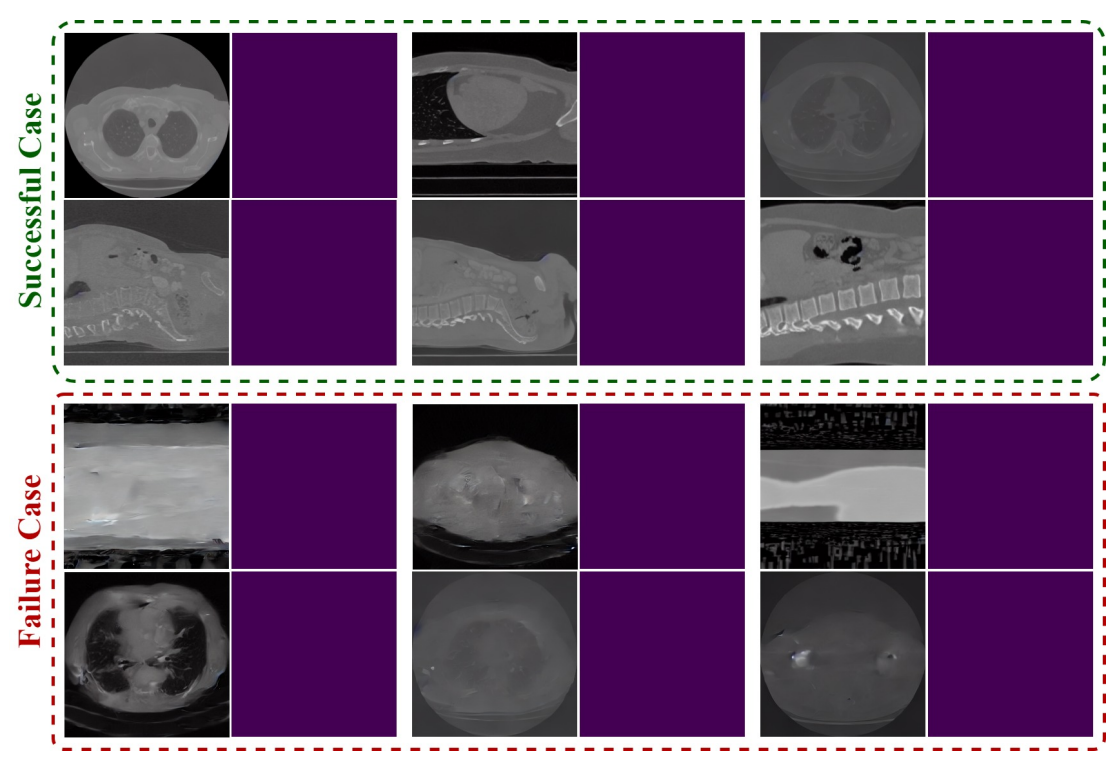
Segmentation mask 없을 때 blurry 한 영상이 나오는 failure case 가 있다고 한다. 얼마나 나오는지 궁금하긴하다.

지식이 모자라서 논문리뷰를...