돌고돌아 그냥 segmentation model 까지 왔다. 원래는 text-to-image 모델을 활용해서 segmentation 을 수행해보는걸 쭉 밀고가려 했는데, 아무리 해봐도 1) 근본적인 해상도의 차이, 2) attention map 과 segmentation mask 의 괴리 를 극복하지 못할 것 같았다. 그 와중에 text 를 가지고 segmentation 을 수행하는 논문이 나왔는데, 이거라면 self supervised learning 을 할 수 있을 것 같아 간단하게 핵심만 파헤쳐 보려고 한다.
Dataset
정말 많은 데이터셋을 활용했다.
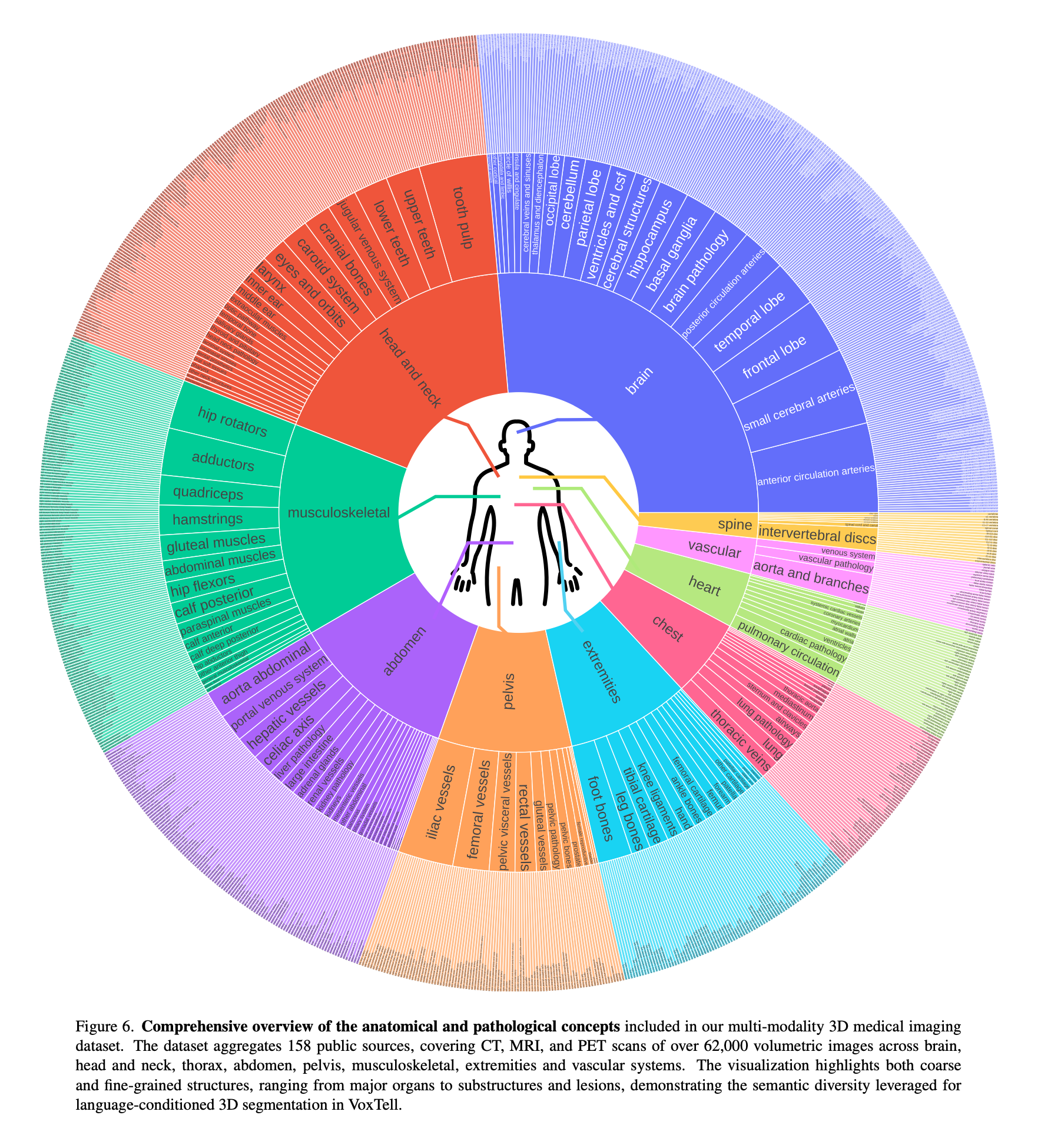
엄청 거대한 피규어가 있는데 (네이쳐 냄새가 난다), 무려 158개의 source 에서 62,000 개의 영상을 수집했다고 한다. 데이터셋은 anatomical structures (liver, heart) 및 pathological lesions (tumors, white matter hyperintensities) 를 포함하였다고 한다.
ReXgroundingCT
내가 지금 하고있는 Chest CT dataset (CT-RATE) 도 benchmark 로 활용했다. 이 데이터셋은 semantic segmentation 이 아닌, 각 instance 마다 annotation 을 해 놓았기 때문에 조금 특별한 dataset 을 구축했다고 한다.
- 기존 semantic lesion segmentation dataset 을 instance-level 로 변환: ToTalSegmentator 을 활용해서 lung lobe 를 추출한뒤 contextual anchor 을 활용했다 한다
- (이해못함) Location-rich public dataset 활용: Brain, head-neck domains 의 DICOM metadata 를 활용해서 structured location prompts 를 제작했다 함
Model Architecture
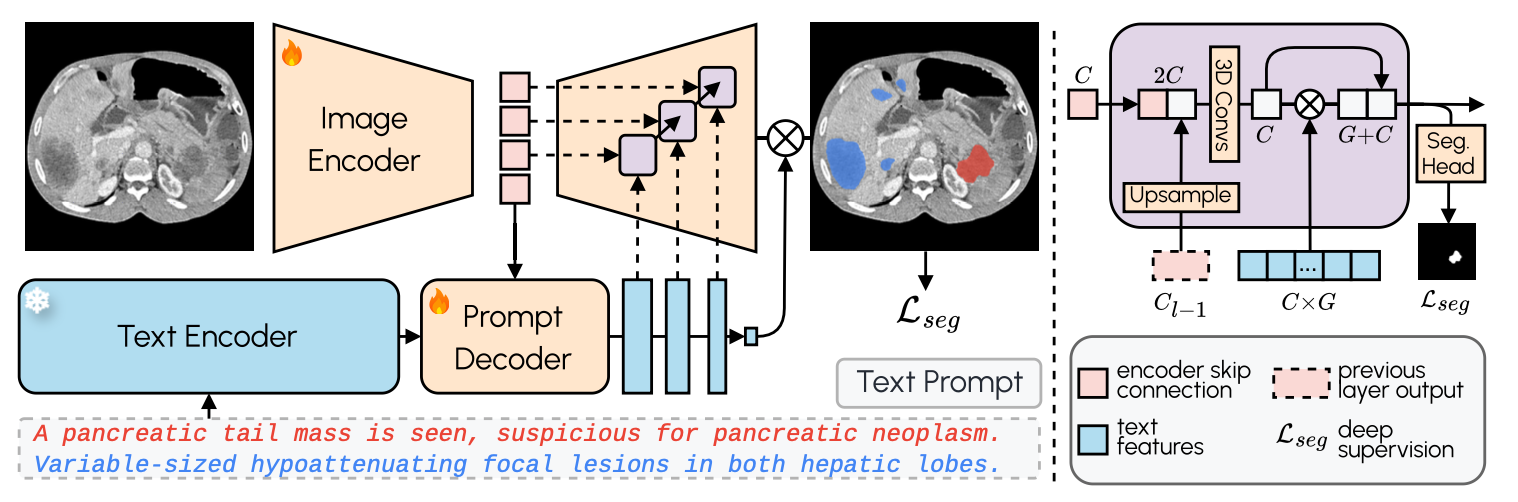
먼저, 이 모델은 SAT 를 많이 닮았다 (아래 그림).
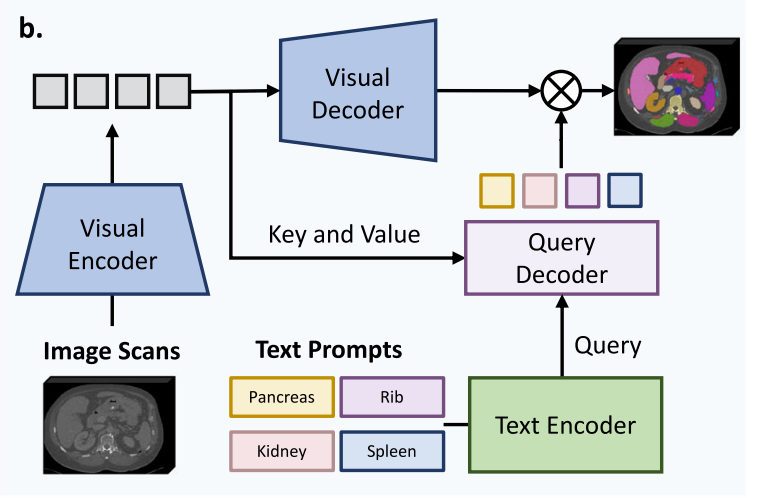
- Image Encoder 을 활용해 feature extraction
- Text Encoder 을 활용해 prompt embedding, 그리고 Decoder 을 활용해서 projection.
- Text prompt 가 query, Image feature 이 key-value pairs 가 된다.
여기서 다른점은 Image decoder 에 있다. SAT 는 최종 query feature 와 generic image feature을 dot product하는 late fusion을 활용하지만, VoxTell 은 hierarchical fusion 을 활용해서 image decoder 의 모든 layer 에서 cross attention 이 수행되도록 한다. 그 이유는?
We argue that robust free-text promptable segmentation in 3D requires repeated cross-modal interaction throughout the decoding hierarchy.
라고 한다. 사실 내 경험적으로도 한 레이어만 쓰는거보다 pyramidal features 를 다 쓰는건 일반적으로 좋았다. 합리적인듯?
Cross-Scale Fusion
Decoder feature 이 어떻게 text prompt 와 fusion 되는지 좀 자세히 알아보겠다.
먼저, 이전 layer 과 skip connection feature 을 합쳐준다. 각 scale 에서, 이전 stage 에서 나온 upsampled output 인 와 encoder skip connection 를 concatenate 하여 convolution block 에 집어넣는다.
그 다음, text features 와의 channel-wise dot product 를 수행한다. 약간 attention 이라고 생각하면 될듯? 는 skip connection 한번 해주고 concat 한다.
Deep Supervision
위의 는 각 intermediate decoder 의 output 이다. 이를 최종 segmentation prediction 으로 다듬어 주기 위해 segmentation head 를 하나 붙여준다. 즉, 모든 scale 에서 유의미한 segmentation mask 를 만들고자 하는 것이다. 이를 위해 다음 손실함수를 정의했다:
이 때, 는 각 scale 에 맞게 downsample 된 ground-truth mask 이고, 는 Dice and cross-entropy losses 이다.
Results
Table 1
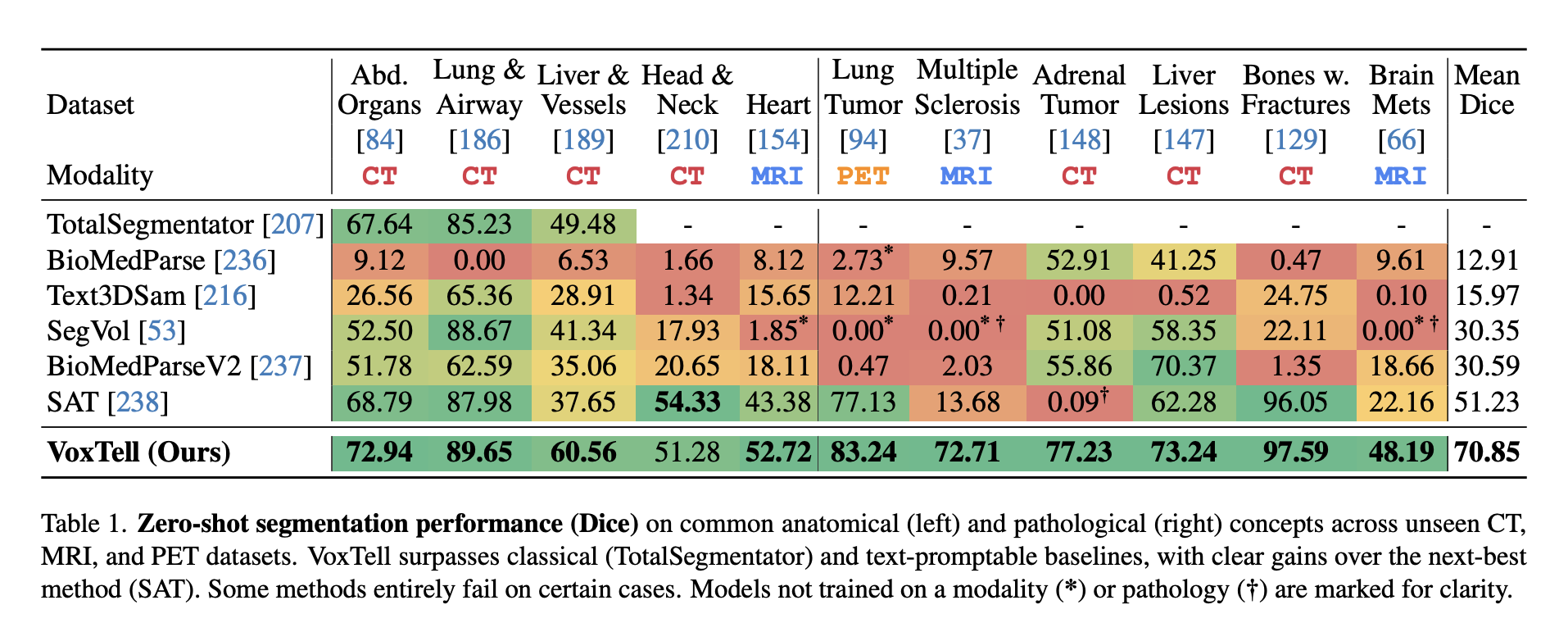
먼저 메인 피규어다. Zero-shot segmentation performance 를 비교해놓았다. 솔직히, SoTA 를 찍었다는걸 보여주고 싶은 마음은 알겠는데, 다른 모델이 훈련되지 않은 modality 나 pathology 까지 합쳐가지고 평균을 내는건 좀 bias 가 심하다는 생각이다...
Table 2
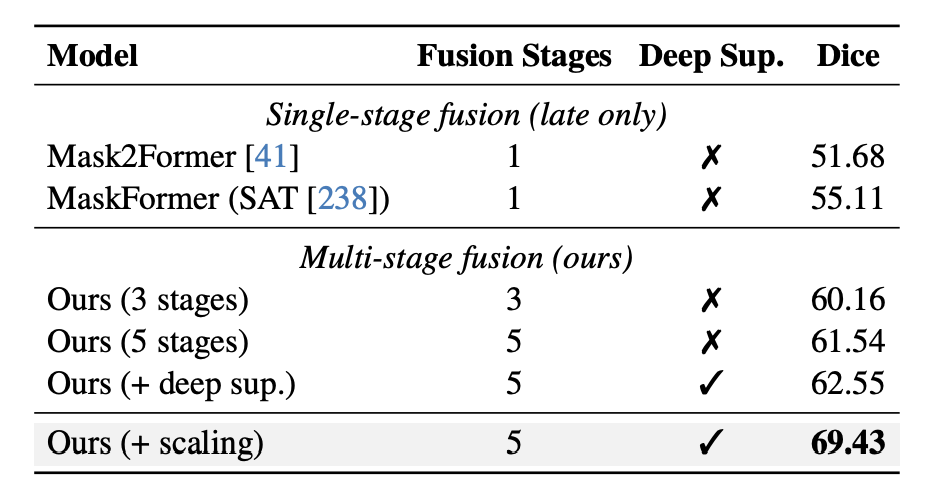
내가 생각하는 메인 결과이다. MaskFormer 에서 단순히 fusion strategy 의 변경으로 +6.43 DSC (55.11->61.54) 를 이끌어냈고, deep supervision 과 scaling 으로 +7.89 DSC 를 만들어냈다. 다만, 여기서 deep supervision 보다 scaling 의 중요성이 주목할만한데, 단순히 batch size 를 2 에서 128 로 올린것으로 이런 성능 상승을 확보한 것이라 training strategy 가 중요하다는 것을 확인할 수 있다.
