Key Hypothesis: Voxel Grid based (VoxelNet) approach 와 Set Abstraction based (PointNet) 을 합치면... 성능이 떡상??!?!?!?
그런데... 어떻게 합치지?
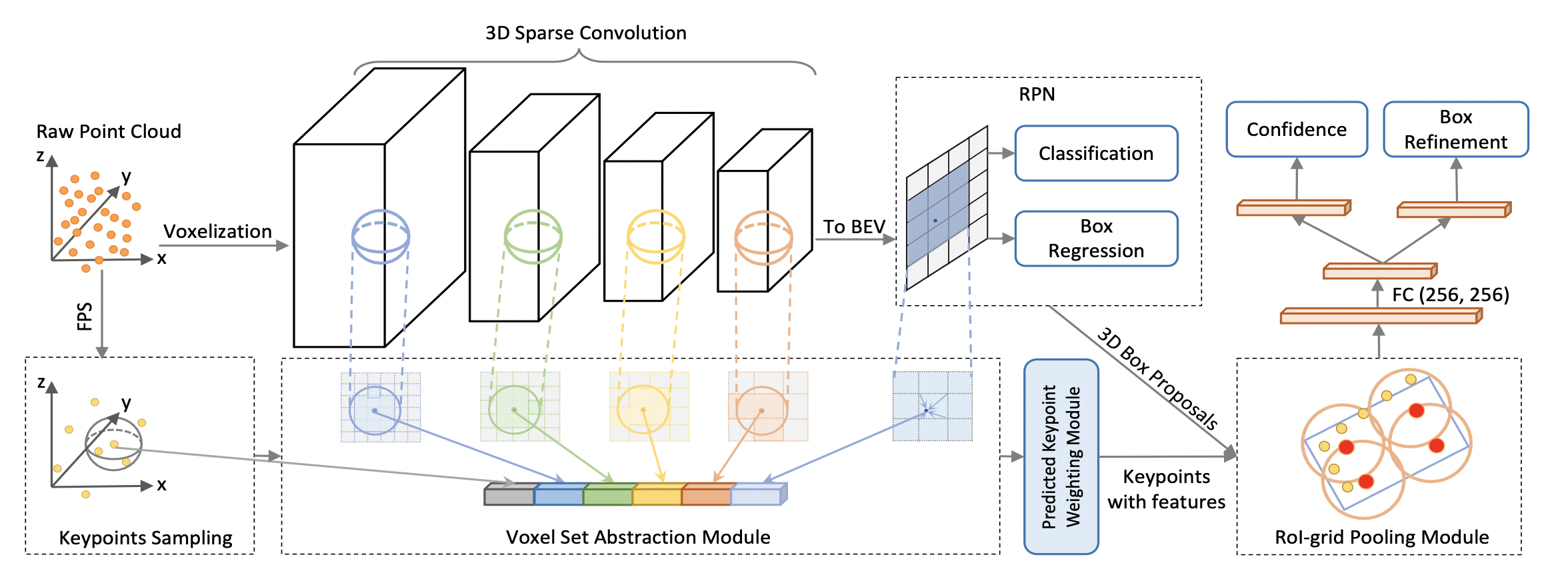
PV-RCNN
Voxel based 는 multi-scale features 을 효율적으로 만들어 낼 수 있으며, set abstraction operations 는 유연한 receptive field 로 정확한 위치 정보를 잡아냄.
그래서, 저자들은 아래 두 과정을 제시함
- Voxel-to-keypoint scene encoding
3D sparse convolution을 이용한 voxel CNN 진행. 모든 정보를 encode 하는데 너무 많은 voxel 을 생성하는 것을 대비해 furthest point sampling (FPS) 기법을 사용해 voxel 정보를 함축함. 각각의 centroid 는 인접한 voxel 들의 정보를 grouping함.
- Keypoint-to-grid RoI feature abstraction
각 Grid point 에서 box proposal 이 있을 때, 각 grid point 에서 multiple radii 의 set abstraction layer 을 적용햄. 이를 RoI-grid pooling 이라고 지칭.
3.1. 3D Voxel CNN for Efficient Feature Encoding and Proposal Generation
3D Voxel CNN
First, divide input points into voxels of size L x W x H.
- 이 때, non-empty voxel 의 feature 값은 그 voxel 안에 있는 값의 mean 이 됨
- 주로 3D coordinates, reflectance intensities가 사용됨
- 그 후, 3D convolutions 연산을 통해 1X, 2X, 4X, 8X size 로 downsample함.
3D proposal generation
8X downsampled 3D feature volumes 를 2D bird eye view 로 변환하여 anchor-based region proposal 을 생성함.
Discussion
지금까지의 3D 모델들은 2D maps 나 3D RoI features를 pooling 했음. 이 접근의 두가지 단점은:
-
생성된 feature volume 의 spatial resolution 이 매우 낮음
-
Upsampling 한다고 하더라도 주변의 정보가 굉장히 sparse 하기 때문에 대부분 0 을 처리하는데 연산량을 낭비하게 됨
이에 반해, PointNet++의 Set Abstraction은 주어진 크기의 voxel이 아닌 임의의 수의 근접점 에서 feature 을 extract 하기 때문에 feature poins 를 encoding 하는 데에 강한 성능을 보였음.
따라서, 저자는 set abstraction 을 stage 2 에 활용할 것을 제시함. 물론, 단순히 활용만 할 생각이라면 그냥 각 복쉘마다 생성된 box proposal 들을 모두 계산에 포함하면 되겠지만... 18000 voxels (무려 4X downsample을 했는데도!) 마다 크기가 3 x 3 x 3 인 box proposal 100개를 처리할 생각을 하면... 아찔하다.
3.2. Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
먼저, 너무 많은 복쉘을 small number of keypoints 로 정리함. 이를 위해 Farthest Point Sampling (FPS) 를 사용해 2048개의 keypoints 를 추출함 (KITTI 기준)
Voxel Set Abstraction Module
목적: 3D CNN feature volumes 로부터 multi-scale semantics 를 추출해 keypoints 에 encode
[ Recall! ] PointNet++ 에서는 PointNet 을 recursively 활용해 voxel-wise features 를 aggregate 했음! 점묶음별로 PointNet 을
진행했음을 기억하자.
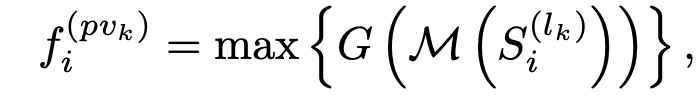
어... 어디서 본 것 같다!
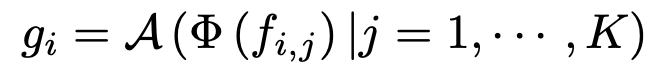
!! PointMLP 에서 봤던 맥락이다. 이 때, A = Aggregation Function (여기선 max pooling 이 되겠다), 이며, 안에 들어가는 G(M(x)) 가 feature extractor 이 되겠다.
- M: Randomly Sampling (Max T_k)
- G: Multi Layer perceptron network
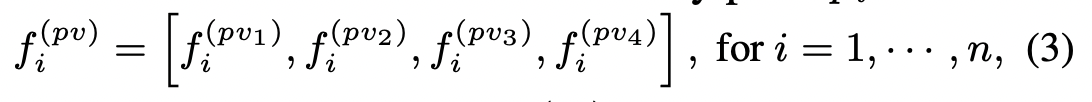
이런 식으로 set abstraction 을 여러 level 에서 수행한 결과를 얻을 수 있으며, 결과적으로 f_i^pv 에서는 3D CNN 을 수행한결과와 Set abstraction 을 수행한 결과를 얻을 수 있다.
Extended VSA Module
(아마 성능 올리려고 잡기술 쓴게 아닌가...)
위의 keypoint feature 에 더해 raw point cloud features 와 bird's eye view features 를 추가해 구조적인 정보량을 더 챙겼다.
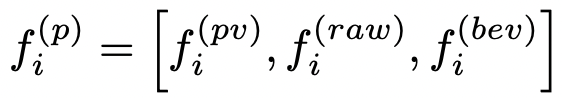
Predicted Keypoint Weighting
목적: Keypoints encoding 이 끝난 후, keypoints 는 다시 proposal refinement 에 활용됨. 이 때, foreground 에 속해있는 keypoints 에 더 비중을 주고 싶음.
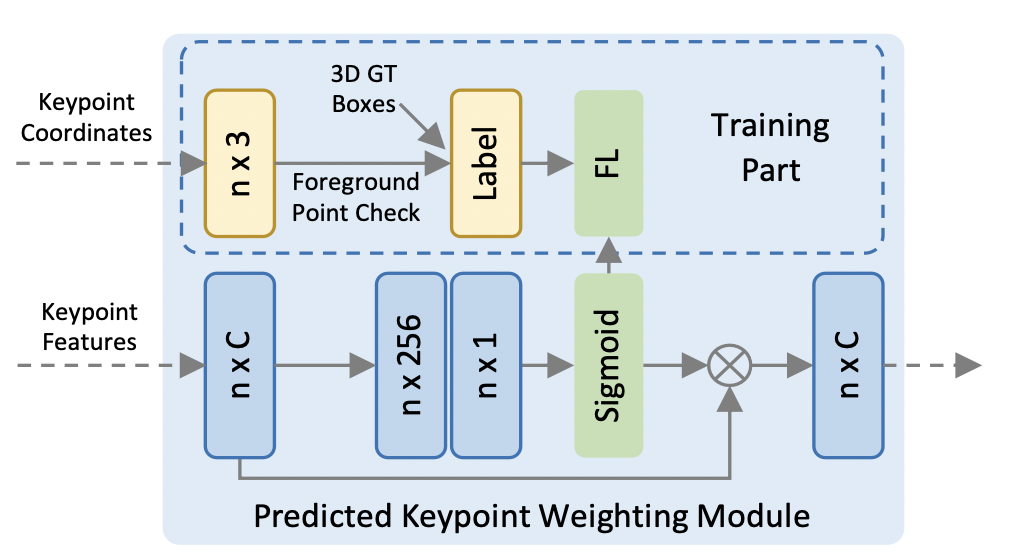
(약간 squeeze excitation 냄새가 나긴 한다...)
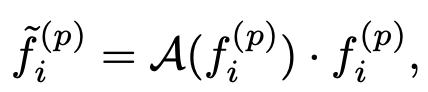
하여튼 A(·) 는 three-layer MLP 위에 sigmoid 를 얹어서 각 keypoint 의 confidence score 를 출력하게 된다. 이 때, PKW 는 focal loss 를 사용해 훈련하게 된다.
3.3. Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
이제 keypoint가 다 추출되었다!
RoI Grid Pooling
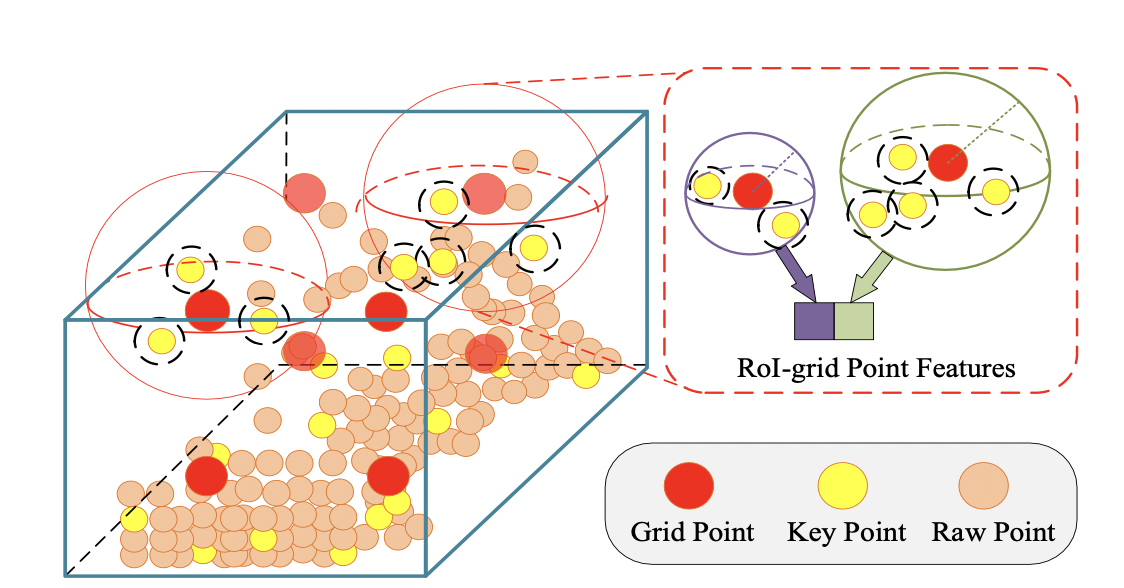
(사실 그림이 직관적이다)
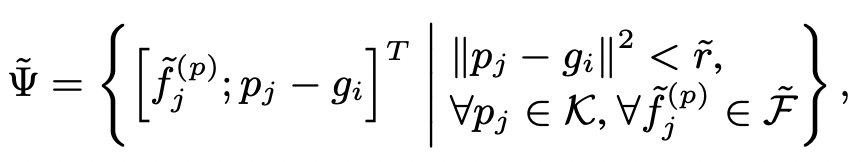
먼저, 각 grid point 에 대해서 radius r 안에 있는 keypoint 들을 sample 함. 이 때, pj-gi 정보를 추가함으로써 local relative position 도 encode 함. 이후, 위에서 했던 것처럼
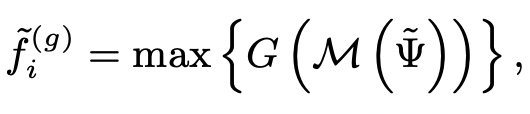
각 grid point 근처의 keypoint features 를 aggregate 하게 됨. 이를 여러 크기의 radius (...) 에 대해서 진행하면 다양한 receptive field 에 대한 정보를 수집할 수 있음.
3D proposal refinement and confidence prediction
목적: RoI feature 을 가지고 size and location residuals 를 학습 (그러니까.. IoU 를 maximize 하고 싶다구요!)
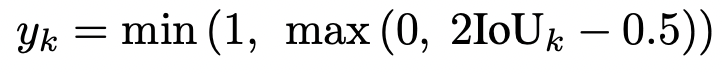
Cross Entropy 를 사용해 학습.
3.4 Training Loss
loss = loss_rpn + loss_point + loss_rcnn- Region Proposal Loss
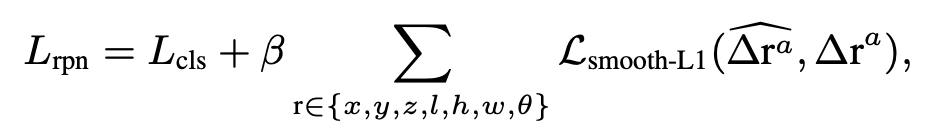
-
Keypoint Segmentation Loss (background foreground)
-
Proposal refinement loss
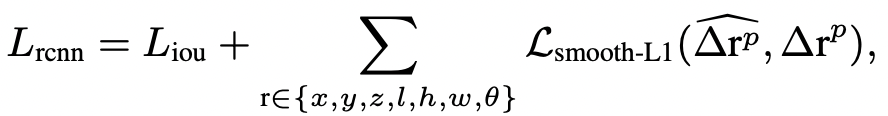
Final Architecture
TMI: Waymo dataset 에 훈련하기 위해 32대의 1080-Ti를 썻다...
