순차적 행동 결정 문제는 MDP로 정의할 수 있다.
MDP (Markov Decision Process)
상태
에이전트가 관찰 가능한 상태의 집합, "자신의 상황에 대한 관찰"
'내가 정의하는 상태는 에이전트가 학습하기에 충분한 정보를 주는 것인가?'를 생각하고 상태를 정의해야 한다
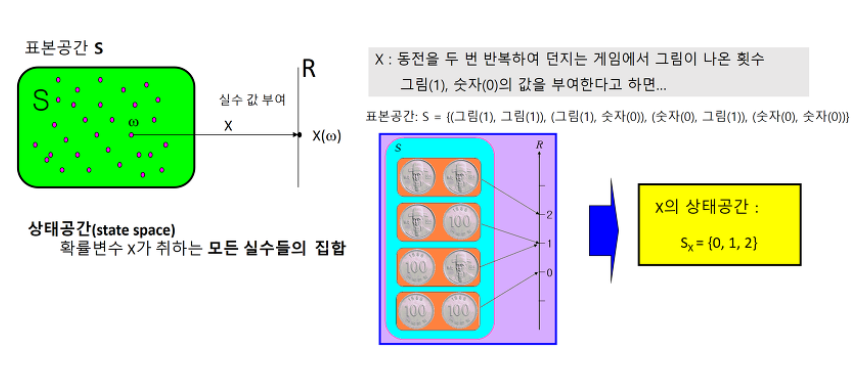
시간 t에서의 상태를 다음과 같이 표현하며 대문자 S는 사건 s를 실수값으로 변환해주는 확률 변수이다.
- 확률 변수란 무엇일까?
무작위 실험을 했을 때, 특정 확률로 발생하는 각각의 결과를 수치적 값으로 표현하는 함수
표본 공간에서의 하나의 사건을 실수값으로 대응시키는 함수라고 생각하면 됨
ex) 동전을 던져서 앞면이 나오는 사건을 X=1, 뒷면이 나오는 사건을 X=0으로 정의하면, X는 확률 변수가 되고 P(X=1) = 1/2, P(X=0) = 1/2가 된다. 실제로 우리가 P를 통해 구하는 것은
으로 이는 확률의 정의와 같다.
행동
에이전트가 상태 에서 할 수 있는 가능한 행동의 집합을 라 한다. 일반적으로 에이전트가 할 수 있는 행동은 모든 상태에서 같으므로 하나의 집합으로 나타낸다.
시간 t에서 에이전트가 행동 a를 했다면 다음과 같이 표현한다. 이때 A 또한 행동을 실수값으로 바꾸는 확률 변수이다.
행동에서 주의해야 할 점은 상태 s 에서 s'으로 가는 행동을 하더라도 외부적 요인으로 인해 달성되지 않을 수도 있다는 점이다. 이 때문에 상태 변환 확률이 존재한다.
상태 변환 확률
에이전트가 상태 s에서 행동 a를 해서 s'으로 가게 되는 확률
이 값은 보상과 마찬가지로 에이전트가 알지 못하는 값이다.
상태 변환 확률은 환경의 모델이라고도 부른다.
환경은 에이전트가 행동을 취히면 상태 변환 확률을 통해 다음에 에이전트가 갈 상태를 알려준다.
보상함수
보상은 에이전트가 학습할 수 있는 유일한 정보이며 환경이 에이전트에게 주는 정보다.
시간 t에서 상태가 s이고 행동이 a일 때 에이전트가 받을 보상을 다음과 같이 나타낸다.
이때 R은 s에서 a라는 행동을 했을 때 도달하는 s'에 따라 값이 달라지므로 확률변수가 된다.
- 보상함수는 기댓값으로 계산되는데, 이러한 이유는 보상을 에이전트에게 주는 것은 환경인데, 환경에 따라서 같은 상태에서 같은 행동을 취하더라도 다른 보상을 줄 수 있기 때문에 이를 종합적으로 계산하기 위해 기댓값을 사용한다.
(환경의 정의가 뭘까? 같은 상태에서 같은 행동을 하면 당연히 보상이 같아야 하는거 아닌가? 상태가 그만큼 많은 정보를 포함하진 않는건가?)
-> 환경은 상태 변환 확률과 정책을 알고 있는 어떤 것이라고 생각해야 할 거 같다.
그리고 상태 변환 확률에 따라 s에서 a를 한다고 해서 원하는 상태가 되는 건 확률에 따른 문제다. 따라서 다음 상태가 어디로 가냐에 따라 보상이 달라진다. 원하는 상태가 되지 않는 이유는 다른 외부적 요인이 있을 것이다. 예를 들어 바둑에서는 상대방이 두는 수라고도 생각할 수 있을 것 같다.
- 행동과 상태의 시점은 t인데 왜 로 계산할까? 이것은 보상을 에이전트가 알고 있는 것이 아니고 환경이 알려주기 때문이다. 시점 t에 상태 s에서 a를 하게 되면 환경은 에이전트에게 상태 s' (시점 t+1) 과 에이전트가 받을 보상을 알려준다. 즉, 보상이 결정되는건 시점이 t+1에서다.
할인율
미래의 가치를 현재의 가치로 환산하기 위해 곱해주는 값
ex) 만약 10억을 지금 받는 것과 10년 뒤에 받는 것을 생각해보면 현재에 10억을 받는 것이 수치적으로 더 가치가 있다. 은행에다 넣어두면 10년 뒤엔 더 큰 금액이 될 것이며 물가상승률을 고려하면 미래의 10억은 현재 10억보다 더 적은 가치를 가질 확률이 크다.
현재의 시간 t로부터 시간 k가 지난 후에 보상의 가치는 다음과 같이 계산할 수 있다. (할인율 는 0과 1 사이의 값을 가진다.
(k-1이 아니라 k가 되어야 하는거 아닌가? k=1일 경우를 생각해보면 할인율이 적용이 안되는데..? 보상이 t+1에 주어져서 그런가?)
-> 맞다
정책
정책은 상태를 입력으로 받고 행동을 출력으로 내보내는 일종의 함수
즉, 현재 상태에서 무슨 행동을 할까? 를 알려주는 함수
가치함수
강화학습의 목적은 총 보상의 크기를 키우는 것인데, 에이전트가 현재 상태에서 앞으로 받을 보상들을 계산을 하기 위한 개념이 가치함수이다.
할인율 개념을 적용하여 현재 시점 t에서의 앞으로 받을 보상을 모두 더하게 된 값을 반환값 (return)이라고 한다.
여기서 G도 여러 가지 값을 가질 수 있으므로 확률변수가 된다.
이 책에서는 유한한 시간동안 상호작용 하는 경우만을 다룬다. 이러한 유한한 경우를 에피소드라 부른다.
특정 상태의 반환값은 에피소드마다 다를 수 있으므로 적절한 상태의 가치를 측정하기 위해서는 기댓값을 이용해야 한다.
따라서 그 상태의 가치는 다음과 같이 표현할 수 있다. 이때, 상태마다 의 확률 분포가 달라진다.
상태의 가치가 주요한 이유는 현재 상태에서 높은 가치를 가진 상태로 가기 위해 어떤 행동을 해야 할까에 대한 단서가 되기 때문이다.
이 식을 정리하면 다음과 같다.
2번에서 3번으로 넘어갈 갈 때 다음 성질을 이용한다.
기댓값 연산이 있다면 그 안에 있는 확률변수는 미리 기댓값 연산을 취해도 결과는 똑같다.
ex) X ~ 동전 하나를 던져서 앞면 1, 뒷면 0, E[2X+1] = E[2E[X] +1] = E[2*1/2 + 1]
3번에서 4번으로 넘어갈 때는 보상함수의 정의를 이용한다.
위 식을 좀 더 직관적으로 이해해보자.
는 현재 상태에서 받을 총 보상을 나타내는 확률 변수이고 v(s)는 현재 상태에서 받을 총 보상의 기댓값이다. s에 따라서 의 확률 분포가 달라지므로 총 보상의 기댓값 v도 달라진다.
현재 상태에서 얻을 보상의 기댓값 v는 다음 상태로 가서 얻는 기댓값 + 다음 상태에서 얻을 보상의 기댓값의 합이다.
가치 함수를 계산하기 위해서는 의 확률 분포를 알아야 한다. 즉, 현재 상태 s에서 s'으로 어떤 확률로 도달하는지 알아야 한다. 그렇기에 상태 변환 확률과 정책을 알아야 한다.
가치 함수는 정책에 의존하기에 다음과 같이 표현하면 좀 더 명확한 식이 되며 이를 벨만 기대방정식이라고 한다. 기댓값도 당연히 정책에 따라 계산 되어야 하므로 다음과 같이 표시해준다.
큐함수
가치함수는 상태의 가치를 알려준다. 그래서 상태 가치함수(state value-function)이라고 불린다.
에이전트가 상태의 가치를 비교하여 다음에 어떤 상태로 갈지 결정 했다면 이제 행동을 결정할 차례이다. 행동을 결정하기 위해 행동의 가치를 알려주는게 큐함수 (action value-function)이다.
특정 상태에서 어떤 행동을 했을 때 주어지는 총 보상을 의미하므로 큐함수는 상태 s와 행동 a를 인수로 가지며 가치함수와는 다음과 같은 관계를 가진다.
큐함수를 벨만 기대 방정식의 형태로 나타내면 다음과 같다.
이 식의 의미를 생각해보자.
는 s'으로 가서 얻는 보상이다. 이는 상태 변환 확률에 따라 계산할 수 있고, 에이전트가 다음 상태까지 갔다는 것을 의미한다.
는 s' 얻을 수 있는 보상의 합이다.
그러면 그냥 로 쓰면 되지 않을까?
-> 써도 되는데 아래 식을 활용하여 벨만 방정식 형태로 만드는게 계산을 위해서 좋다.
벨만 기대 방정식
벨만 방정식은 현재 상태변수의 가치와 다음 시간스텝의 상태변수의 가치와의 관계를 나타내주는 식이다.
벨만 기대 방정식이라고 부르는 이유는 식에 기댓값 개념이 들어가기 때문이다.
벨만 기대 방정식이 강화학습에서 의미가 있는 이유는 계속 값을 업데이트 하며 계산할 수 있기 때문이다. 이는 다이나믹 프로그래밍과 관련이 있다.
우선 값을 업데이트 하기 위해서는 우리는 이 식을 계산할 수 있어야 한다. 계산할 수 있는 형태로 바꾸면 다음과 같다.
위 식을 살펴보면 r(s,a)는 현재 상태 s에서 a라는 행동을 했을 때 얻는 보상이다. 그리고 는 상태 변환 확률이다.
(에이전트가 보상을 받는 시점은 언제인가?)
-> 현재 상태 s에서 a라는 행동을 했기 때문에 보상을 받는다고 이해해야 할 거 같다.
벨만 최적 방정식
벨만 기대 방정식을 진행하다 보면 언젠가 식의 왼쪽 항과 오른쪽 항이 동일해진다.
이 값이 수렴한다면 이 값을 정책 에 대한 참 가치함수 값이라고 한다.
최적 가치함수는 수많은 정책 중 가장 높은 보상을 얻게 되는 정책에서의 참 가치함수다.
