강화학습
1.3장 Dynamic Programming

해당 글은 서울대학교 이정우 교수님의 강의를 보고 정리한 내용입니다.https://www.youtube.com/watch?v=o85AaCB5Nck&list=PLKs7xpqpX1beJ5-EOFDXTVckBQFFyTxUH: 시간에 따라 순차적으로 policy를 찾
2.2장 Markov Decision Process
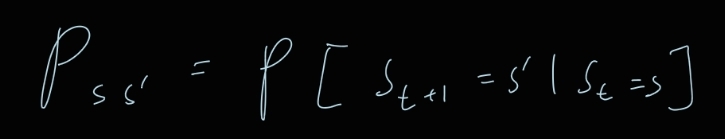
해당 글은 서울대학교 이정우 교수님의 강의를 보고 정리한 내용입니다.https://www.youtube.com/watch?v=o85AaCB5Nck&list=PLKs7xpqpX1beJ5-EOFDXTVckBQFFyTxUH배우는 이유 : 현대에 나와 있는 모든 강화
3.1장 강화학습 개요
에이전트가 환경을 탐색하면서 얻는 보상들의 합을 최대화하는 "최적의 행동양식, 또는 정책"을 학습하는 것(강화학습은 환경에 대한 정확한 지식이 없어도 시행착오를 통해 학습할 수 있다. 이건 어떻게 보면 완전 탐색과 비슷하다고 생각이 든다. 그리고 그만큼 시간이 많이 걸
4.2장 강화학습 기초 1: MDP와 벨만 방정식
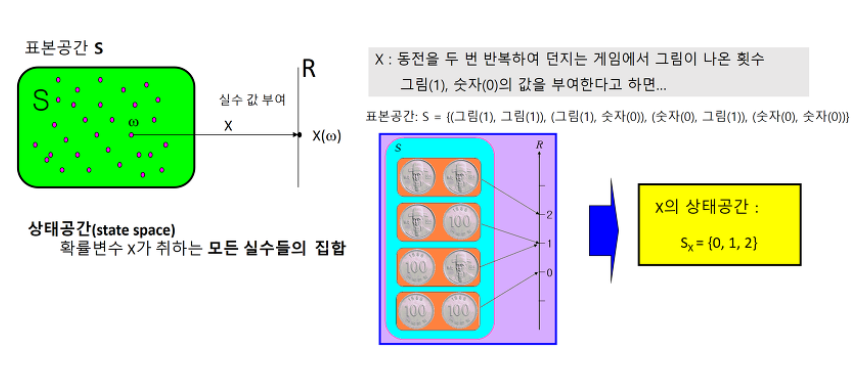
순차적 행동 결정 문제는 MDP로 정의할 수 있다.에이전트가 관찰 가능한 상태의 집합, "자신의 상황에 대한 관찰"'내가 정의하는 상태는 에이전트가 학습하기에 충분한 정보를 주는 것인가?'를 생각하고 상태를 정의해야 한다시간 t에서의 상태를 다음과 같이 표현하며 대문자
5.MDP의 최적 정책을 구하는 방법
MDP를 안다 = 상태 전이 확률과 보상함수를 안다.MDP를 알 때 이를 이용하여 정책을 개선하는 것을 플래닝이라고 한다.prediction - 정책 $\\pi$가 주어졌을 때 각 상태의 value를 평가하는 것control - 최적의 정책 함수를 찾는 것본 과정은 크
6.3장 강화학습 기초 2: 그리드월드와 다이내믹 프로그래밍
순차적 행동 결정 문제를 푸는 단계를 세 단계로 나누어 보면 다음과 같다.순차적 행동 문제를 MDP로 전환한다.가치함수를 벨만 방정식으로 반복적으로 계산한다.최적 가치함수와 최적 정책을 찾는다다이내믹 프로그래밍의 핵심은 큰 문제를 작은 문제로 쪼개었을 때, 만약 작은
7.4장 강화학습 기초 3: 그리드월드와 큐러닝
3장에서 본 dynamic programming은 환경에 대한 모든 정보를 가지고 모든 경우의 수를 계산하기 때문에 시간이 오래 걸린다. 반면 인간의 경우 오목이나 바둑을 둘 때, 모든 경우의 수를 계산하지 않고 일단 해보고 복기를 한다.강화학습도 마찬가지로 에이전트가
8.MDP를 모를 때 value 평가하기
한번에 state value 를 추정하는 방법 - 여기서 N은 방문 횟수가 된다.$$v\_\\pi(s_t) =\\frac{V(s_t)}{N(s_t)}$$근데 이러한 방법보단 한 번의 에피소드마다 업데이트하는 방법이 유용하다.$$V(s_t) \\leftarrow V(s_
9.MDP를 모를 때 value 평가하기
한번에 state value 를 추정하는 방법 - 여기서 N은 방문 횟수가 된다.$$v\_\\pi(s_t) =\\frac{V(s_t)}{N(s_t)}$$근데 이러한 방법보단 한 번의 에피소드마다 업데이트하는 방법이 유용하다.$$V(s_t) \\leftarrow V(s_
10.MDP를 모를 때 value 평가하기
한번에 state value 를 추정하는 방법 - 여기서 N은 방문 횟수가 된다.$$v\_\\pi(s_t) =\\frac{V(s_t)}{N(s_t)}$$근데 이러한 방법보단 한 번의 에피소드마다 업데이트하는 방법이 유용하다.$$V(s_t) \\leftarrow V(s_
11.Deep RL
state space가 비약적으로 클 경우, 또는 연속적인 state space를 가질 경우 기존 table 기반 학습법으로는 모든 상태를 방문할 수가 없다. 따라서 (s,v(s))를 학습하여 학습하지 못한 상태에 대해서도 가치함수를 추정할 수 있게 해야 하는데, 그
12.Policy Gradient
이 글은 아래 강의를 참고하여 쓴 글입니다.\- 강화학습 7강이전까지 가치 기반 방법들의 경우는 v 함수, (state value function)과 q 함수 (action value function)을 추정하여 문제를 풀었다.일반적으로 model free 환경의 경우