LDA에 대한 자세한 설명
https://acoustic-basin-638.notion.site/LDA-Latent-Dirichlet-Allocation-de7f53bf705e49ffb55cd39d6401544a?pvs=4
문서들에 잠재되어 있는 공통된 토픽을 추출해 내는 기법
토픽 모델링 알고리즘은 기본적으로 2가지 가정 하에 만들어짐
- 개별 문서는 혼합된 여러 개의 주제로 구성
- 개별 주제는 여러 개의 단어로 구성
토픽 모델링 알고리즘 유형
1. 행렬 분해 기반
LSA (Latent Semantic Analysis), MMF(Non Negative Factorization)
잠재 의미 분석 (Latent Semantic Analysis, LSA)
BoW에 기반한 DTM , DT-IDF는 단어의 빈도 수를 이용한 방법이기 때문에 단어의 의미(문맥, 순서)를 고려하지 못함. 이를 보완한게 LSA임.
LSA를 이해하기 위해서는 SVD를 이해 해야함.
특이값 분해 SVD(Singular Value Decomposition).
직교 행렬은 교환법칙이 성립하는 역행렬을 말하고, 대각 행렬은 k*E를 말한다.
즉, 대각행렬은 i와 j가 같은 부분이 0이 아니고 나머지가 0인 행렬
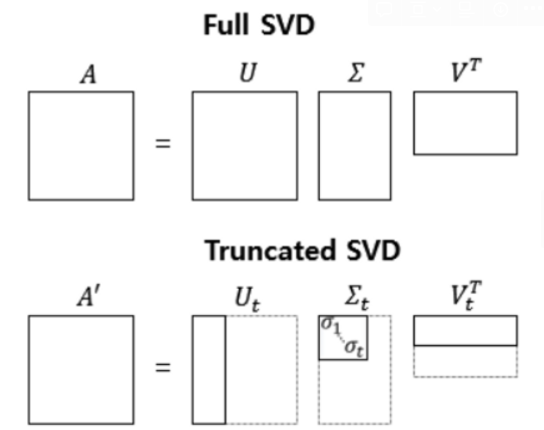
특이값 분해란 A 행렬은 다음과 같이 3개의 행렬의 곱으로 분해하는 것.
A 행렬이 m x n 행렬일 때,

즉, “VV에 있는 열벡터(→xx→ 혹은 →yy→)를 행렬 AA를 통해 선형변환 할 때, 그 크기는 σ1σ1, σ2σ2만큼 변하지만,
여전히 직교하는 벡터들 →u1u→1, →u2u→2를 찾을 수 있겠느냐?” 라고 묻는 것이다
중요 성질
각각의 벡터들을 하나의 열로 여러개를 합친 것으로 행렬을 이해할 수 있는데, 이때 단위 벡터의 경우 각 행에 1이 하나이므로 각각 내적 시 값이 0임. 즉 서로 직교한다고 볼 수 있음.
이게 의 의미임. 즉, 각 성분의 중요도
U의 차원은 문서의 개수 x 토픽의 수 t이다. 즉 , 각 행은 문서마다 가지고 있는 토픽의 성분을 말하는 것이다.
V^T는 토픽의 수 t x 단어의 개수의 크기이다. 즉, 각 열은 단어의 각 토픽에 대한 잠재 의미를 표현한 벡터라고 볼 수 있다.
2. 확률 기반
LDA (Latent Drichlet Allocation), pLSA
