자연어처리
1.텍스트 전처리

아래 내용은 wikidocs의 딥러닝을 이용한 자연어 처리 입문의 내용을 공부하고 요약한 내용입니다.wikidocs -딥러닝을 이용한 자연어 처리 입문 https://wikidocs.net/book/2155토큰은 의미있는 단위로 상황에 따라 다름. 때에 따라
2.단어의 다양한 표현 방법
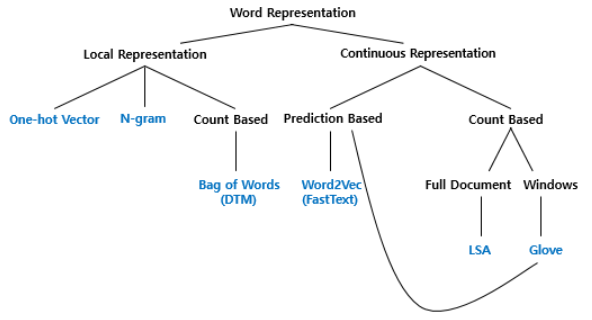
해당 글은 wikidocs의 딥 러닝을 이용한 자연어 처리를 재구성하여 다음과 같은 순서로 작성되었습니다.텍스트 전처리 (Text Preprocessing)불필요한 부분들 제거단어의 다양한 표현 방법 모델이 학습할 수 있게 text를 숫자로 표현하는 방법다양한 모델들참
3.다양한 모델들
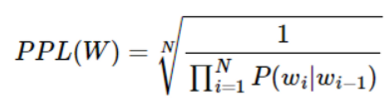
해당 글은 wikidocs의 '딥 러닝을 이용한 자연어 처리'를 학습하고 내용을 재구성하여 다음과 같은 순서로 작성되었습니다.텍스트 전처리 (Text Preprocessing)문장에서 불필요한 부분들 제거단어의 다양한 표현 방법모델이 학습할 수 있게 text를 숫자로
4.Topic modeling

문서들에 잠재되어 있는 공통된 토픽을 추출해 내는 기법토픽 모델링 알고리즘은 기본적으로 2가지 가정 하에 만들어짐개별 문서는 혼합된 여러 개의 주제로 구성개별 주제는 여러 개의 단어로 구성알고리즘 유형LSA (Latent Semantic Analysis), MMF(No
5.Bag-of-Words와 Naive Bayes Classifier

단어를 one-hot vector로 나타내어 이를 기반으로 문장과 문서를 표현하는 방법이다.단어 : 0,0,0,1문장 : 1,2,3,1 ⇒ 들어간 단어 one hot vector 합문서 : 51,31,41,23 ⇒ 들어간 문장 vector 합현재 자주 쓰이는 word
6.Word2Vec
Word2Vec은 sparse한 one-hot vector로 단어를 표현하는 대신 더 적은 차원의 dense vector로 단어를 표현하는 방법이다. 이 방법은 단순하지만 강력한 가정을 기반으로 단어를 학습한다. > 가정 : 단어의 의미는 주변 단어가 결정한다.
7.LSTM
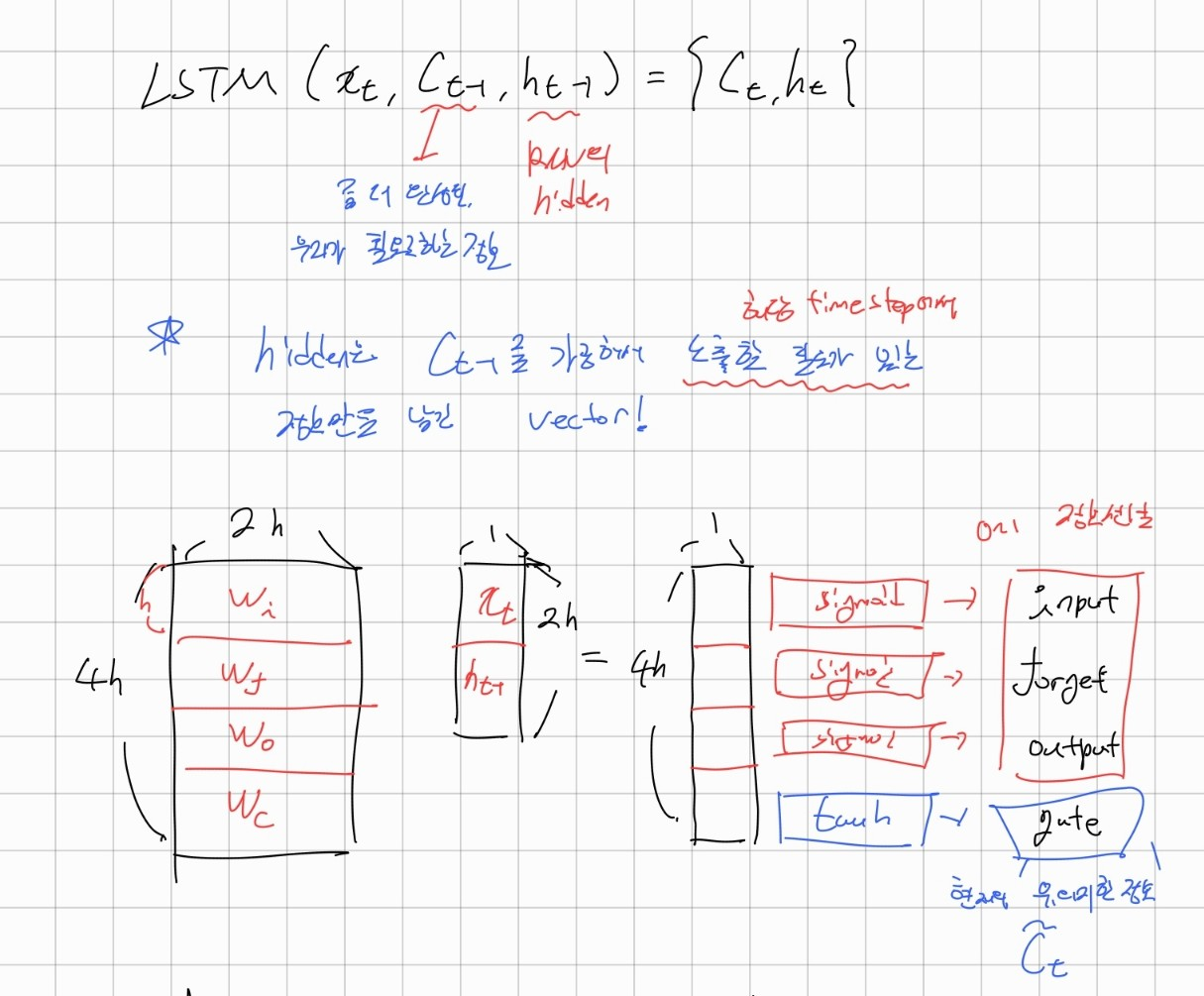
LSTM은 기존 RNN 모델의 gradient vanishing 문제를 해결하기 위해 제안된 모델이다.기본적으로 거의 비슷한 구조를 가지고 있지만 크게 두 가지 차이가 있다.hidden state를 hidden state와 cell state로 나누었다.cell sta
8.NNLM (Neural Network Language Model)
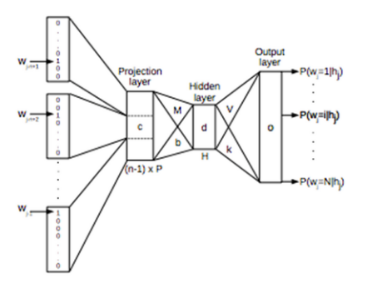
단어가 너무 많아서 불필요하게 메모리 공간 차지단어 간 유사도가 전혀 반영이 안 됨 = 단어의 의미가 반영이 안 됨이 두가지를 해결하는 방법이 Word Embedding단어를 vector space에 mapping 하는 작업이때, 단어의 의미를 잘 반영하기 위해 sem
9.GloVe
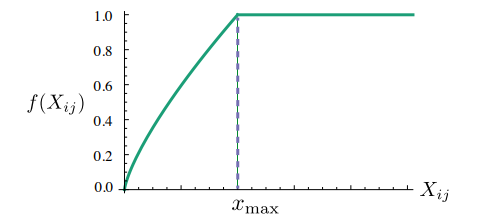
GloVe는 LSA와 Word2Vec의 단점을 개선한 Word representation 방법이다.Word2Vec의 단점 :윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스 전체적인 통계 정보를 반영하지 못한다는 점,LSA의 단점 : Word2Vec 처럼 단어
10.Training language models to follow instructions with human feedback
링크에 논문 리뷰가 있습니다.
11.Transformer 시간복잡도
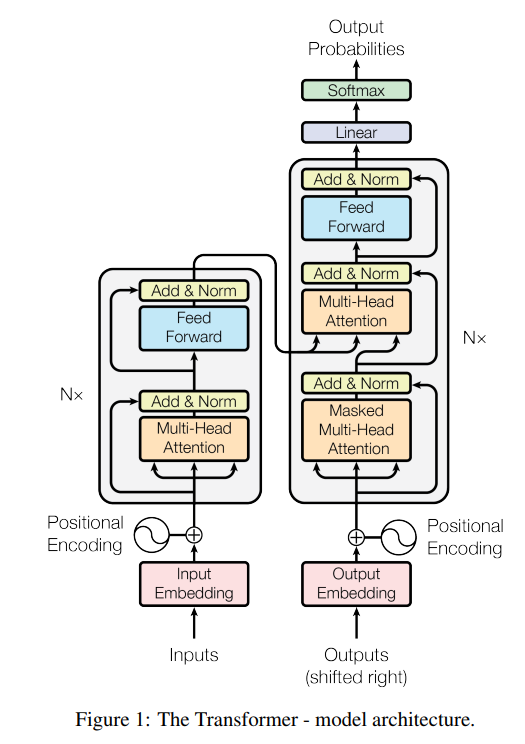
transformer의 Encoder 부분의 시간복잡도를 계산해보자.transformer의 시간복잡도를 계산하기 위해서는 행렬의 시간복잡도를 계산할 수 있어야 한다.A : n x d, B: d x n 행렬 두 개가 있다고 하자.두 행렬의 곱 AB의 시간복잡도는 O(n^