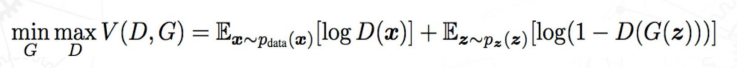
GAN (한글)
Overview
1. GAN의 정의 및 원리
GAN의 정의
: We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimatesthe probability that a sample came from the training data rather than G.
참고문헌
Goodfellow, Ian, et al. "Generative adversarial nets." NIPS. 2014.
GAN의 구조
: 일반적인 GAN 모델의 경우 우리는 2가지 모델을 학습시켜야 한다. 하나는 Discriminator이며 나머지 하나는 Generator이다. 그들이 하는 역할은 다음과 같다.
Discriminator는 input으로 데이터를 받고 그것이 진짜인지 아닌지 학습한다. 예를 들어 진짜 고양이인지 아닌지. 이는 label이 있으므로 Supervised Learning이라고 할 수 있다.
Generator는 latent vector를 input으로 받고 학습된 확률분포를 통해서 이미지를 생성하는 작업을 한다. 이는 label이 없으므로 Unsupervised Learning이다.
GAN은 두 가지 모델이 각각의 목표를 가짐으로써 생성 모델의 역할을 하게 된다.
Generator의 목표는 Discriminator가 눈치채지 못하도록 진짜 같은 이미지를 만드는 것이다.
Discriminator의 목표는 이미지가 들어왔을 때 이게 실제 이미지인지, Generator가 만든 이미지인지를 완벽히 구분하는 것이다.
GAN의 학습 (손실함수)
: 위와 같은 두 모델의 목표를 이루기 위해,
전통적인 GAN 모델에서는 다음과 같은 손실함수를 가지고 학습을 진행한다.
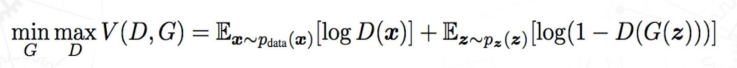
먼저 각각의 Notation이 의미하는 바를 알아보자.
x~ p_data(x) : 데이터 x가 실제 데이터에 대한 확률 분포 p_data(x)에서 추출한 데이터임을 의미
z : latent vector로서 이미지에 대한 정보를 저장하고 있는 vector.(word2vec와 비슷하다.) 이를 벡터 정보를 이용하여 Generator는 이미지를 생성한다.
z ~ p_z(z) : latent vector z가 가정분포(ex, 정규분포, 균등분포 등) p_z(z)에서 추출된 latent vector임을 의미.
D(x) : Discriminator에게 데이터 x가 주어졌을 때 진짜일 확률.
G(z) : z라는 latent vector 가 들어왔을 때 학습된 확률분포 p_model(x)에 따라 이미지를 생성.
이제 위의 Notation을 기반으로 위 식을 살펴보자. (이때, E는 batch size 와 관련한다.)
Discriminator의 성능이 뛰어날수록 실제 데이터에서 온 x에 대해 D(x)→1, 또한 가짜 데이터인 G(z)에 대해 D(G(z))→0이 될 것이므로, V(D,G)의 값이 커진다.
→ Discriminator의 목표는 V(D,G)를 최대화 하는 것이다. 이게 max(D)의 의미이다.
반면, Generator의 성능이 뛰어날수록 D(G(z))→1이 되어 V(D,G)의 값이 작아진다.
→ Genorator의 목표는 V(D,G)를 최소화하는 것. min(G)
GAN의 학습 (과정)
GAN의 학습과정은 세 단계를 거친다.
- 실제 데이터를 통한 Discriminator 학습
- 를 통한 D 학습.
- 가짜 데이터를 통한 Discriminator 학습
- 를 통한 D 학습
- 판별기의 결과를 통한 Ganerator 학습
- 를 통한 G 학습
- 하지만 초반에 G가 만들어낸 이미지는 형편없으므로 D(G(z))의 값이 0에 가깝다. 따라서 초반에는 log(1-x)의 x=0에서의 기울기는 작으므로 학습이 느리다. 이를 위해 초반에 를 사용하기도 한다.
Goodfellow, Ian, et al. "Generative adversarial nets." NIPS. 2014.
결국 이러한 과정을 거치게 되면 최종적으로는 Generator의 확률분포가 실제 데이터의 확률분포를 따르게 되면서 가 됨.
가 되면 점점 그럴듯한 데이터를 생성할 수 있게 되고 이는 판별기를 잘 속일 수 있음.
- 참고, GAN을 훈련시 주의사항 (GAN 첫걸음) : GAN에서 하나만 먼저 훈련하고 같은 데이터로 다시 한번 다른 모델을 훈련하는것은 좋지 않은 이유
-
판별기가 너무 빨리 학습한다면 생성기는 어떤게 맞는 건지 몰라서 픽셀을 마구잡이로 다시 만들 것. 어떤 방향으로 갈지 모름.
-
반면 판별기가 너무 늦게 학습한다면 생성기는 이미지를 아무렇게나 만들어도 점수를 얻으므로 제대로 된 학습이 안됨.
제대로 훈련하기 위해서는 둘 모두 동시에 훈련시키면서 양쪽 모두 비슷한 수준으로 훈련
-
2. GAN의 종류

https://roytravel.tistory.com/109
2-1. DCGAN (Deep Convoluntional Generative Adversarial Networks)
기존 Discriminator나 Generator의 학습에서는 Fully connected NN 구조를 사용했는데 DCGAN은 CNN으로 사용했음. 이를 통해서 NN구조에서의 Black box 문제를 해결하고 어떤 층이 무슨 역할을 하는지 알 수 있게 되었다.
2-2. ProgressiveGAN (PGGAN)
기존 모델과 달리 점진적으로 학습하여 고화질 이미지 생성을 가능하게 한 모델.

**Progressive Growing of GANs for Improved Quality, Stability, and Variation.”arXiv.2017**
https://arxiv.org/abs/1710.10196
기본적으로 고화질 데이터는 Discriminator의 판단 근거가 더 많으므로 Generator가 속이기 어렵다. 따라서 기본 GAN에서는 고화질 데이터 학습이 어렵다.
이러한 문제를 해결하기 위해 ProgressiveGAN은 먼저 낮은 해상도로 학습을 진행하고, 점점 화질을 높여가면서 학습을 했다.
2-3. CycleGAN (Cycle-Consistent Adversarial Networks)
CycleGAN 이전의 Image-to-Image Translation 모델인 Pix2Pix의 경우 다음과 같이 쌍으로 데이터셋을 구하기 쉬웠음. 그러나 풍경 같은 데이터셋은 도메인에 따른 데이터를 구축하기 힘듦. 이러한 문제를 해결한게 CycleGAN.
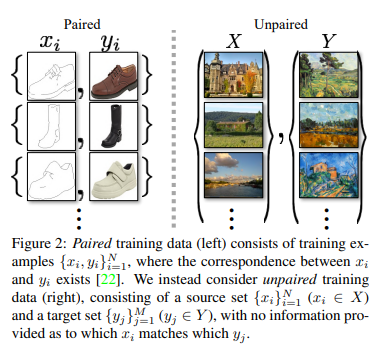
Unpaired Image-to-Image Translation
using Cycle-Consistent Adversarial Networks “arXiv.2020
기존 Image-to-Image Traslation에서 별도의 제약 없이 이미지 A의 일부 특성을 타겟 도메인 X에서 타겟 도메인 Y의 특성으로 바꾸고자 한다면 A의 일부 특성이 손실될 수도 있음. 예를 들어 물을 마시는 황색 말을 얼룩말로 바꾸자할 때 Discriminator를 속이기 위해서 물을 마시는 얼룩말이 아닌 뛰어다니는 얼룩말로 바꿀 수가 있음.
이러한 문제를 해결하기 위해 cycleGAN은 G(x)가 다시 원본 이미지 x로 재구성 될 수 있는 형태로 만들어져야 한다는 제약을 추가함으로써 해결함.
이는 데이터를 구할 수 없는 다양한 분야에 대해서 GAN이 적용 가능하다는 것을 암시함.
2-4. StarGAN
기존 연구에서 Image-to-Image translation은 한 모델 당 두 개의 도메인에 대해서 동작했음. 따라서 여러가지 도메인(머리색, 인종, 나이 등) 을 바꾸기 위해서는 각각의 도메인 당 하나의 모델이 필요했음. StarGAN은 이러한 문제를 해결하여 하나의 모델로 여러 도메인을 바꿀 수 있게 함.
3. GAN을 이용한 응용 분야 (구체적인 예시)
3-1. **Computer Vision (Data augmentation)**
컴퓨터 비전 분야는 데이터가 많을수록 일반적으로 더 좋은 모델을 만들 수 있음. 그러나 원하는 사진을 만드는 것은 때에 따라선 비용이 너무 많이 듦. 이러한 부분을 GAN이 해결해줄 수 있음. GAN의 생성모델은 가지고 있는 데이터를 기반으로 새로운 데이터를 합성할 수 있음. 이러한 기술은 자율 주행 자동차, 가상 현실과 같은 곳에 적용될 수 있음.
It is not a secret that any Computer Vision Model (and to that extent any neural-network-based model) is hungry for data — the more data you have, the better the model you can potentially create. However, manually annotating data labeling for training is a slow and costly process. Many companies cannot afford it.
A possible solution (at least partial) can be found in the generative model domain — it turns out generative models can work as a tool for the synthesis of new labeled data samples based on a relatively small number of hand-crafted assets. This approach is taken by Israel startup DataGen that reported to have secured 18.5 mln USD of funding in March 2021.
참고자료:
https://mobidev.biz/blog/gan-technology-use-cases-for-business-application
3-2. Text to Image
사람의 생각을 그림으로 옮겨주는 디자이너와의 협업에서 종종 요청사항과 다른 경우가 있는 경우들 또는 나중에 책을 그림책으로 바꾸는 일, 영상으로 바꾸는 일등에 Text to Image가 응용될 수 있다.
stackGAN이나 그를 이용한 AttnGAN을 활용하면 Text to Image 작업이 가능하다. 물론 현재는 DALL E 2 등의 알고리즘이 더 뛰어난 성능을 보이는 것 같다.
참고자료:
https://openai.com/blog/dall-e/
3-3. 3D Object Generation
음성 혹은 영상의 경우는 쉽게 학습 데이터를 확보할 수 있지만 3차원 데이터는 3D센서를 통해 얻었다 하더라도 다양한 후처리 작업이 필요하다. 이러한 문제를 해결하기 위해 3D-GAN등의 모델을 활용하여 3차원 데이터를 확보할 수 있다.
참고자료:
https://ettrends.etri.re.kr/ettrends/178/0905178002/34-4_15-22.pdf
4. 연구기관, 산업체에서 GAN을 사용하는 사례 조사 (국내, 해외 기업 또는 연구기관에서 GAN을 활용하여 서비스를 제공하거나 독창적인 기술 발표들을 정리)
4-1. MelGAN (Mel Spectograms)
사람이 음성을 인식할 때는 mal-sacle로 음성을 인식한다. spectogram을 이용하면 복잡한 오디오 신호를 각각의 주파수에서 해석이 가능하다.
따라서 TTS(Text-to-Speech) 알고리즘에서는 Mel Spectograms를 사용하여 음성으로 만드는데, 보통 WaveNet을 이용하여 만들었다. WaveNet은 attention 정보를 활용하여 Mel Spectograms를 음성으로 만들었다.
MelGAN은 Mel Spectograms → audio 에서 GAN을 적용했다.
독창적인 기술인 것 같아서 정리했다.
참고자료:
https://enchiridion.tistory.com/71 (MelGAN 참고)
4-2. 네이버 webtoon AI (Generate Cartoon Characters)
네이버 웹툰 AI의 경우 딥러닝 기술을 활용해 웹툰 작가들을 위한 3가지 기능을 발표함. 그리고 그 의도는 진입 장벽을 낮춰 누구나 웹툰 작가가 될 수 있게 하는 것.
-
Sketch Simplification (GAN 기술의 활용은 아님)
콘티를 스케치로 바꿔주기
-
Automatic Colorization (현재 GAN을 쓰는지는 모르겠음)
특정 화가의 화풍으로 채색하기
-
Cross-Domain Transfer (GAN 모델 활용)
세계 최초로 GAN 모델 기반으로 얼굴 변한 모델을 이용한 서비스를 웹툰 ‘마주쳤다’에 적용함.
참고자료
:https://sigai.or.kr/workshop/AI-for-everyone/2018/slides/네이버-웹툰과-AI.pdf
4-3 가상 인물 (Virtual model)
가상 유튜버 ‘루이(RUI)’의 경우 평소 외모에 대한 걱정 때문에 유튜버 활동을 하지 못했었는데, 가상 얼굴을 사용함으로써 유튜브 활동을 제약 없이 할 수 있었음. 한국 가상 인플루언서 ‘로지’는 아예 존재하지 않는 인물로서 MZ세대가 선호하는 얼굴형을 모아 만들어진 인물. 국내 뿐만 아니라 외국에서도 버추얼 모델을 사용하기도 함.
또한, 국내에서 가상 아이돌(ETERN!TY)도 등장하고 있는데 아마 GAN을 활용하는 것으로 생각된다.
참고자료:
https://m.post.naver.com/viewer/postView.naver?volumeNo=32664236&memberNo=27908841
