머신러닝 & 딥러닝
1.최적화 - Gradient Descent Methods
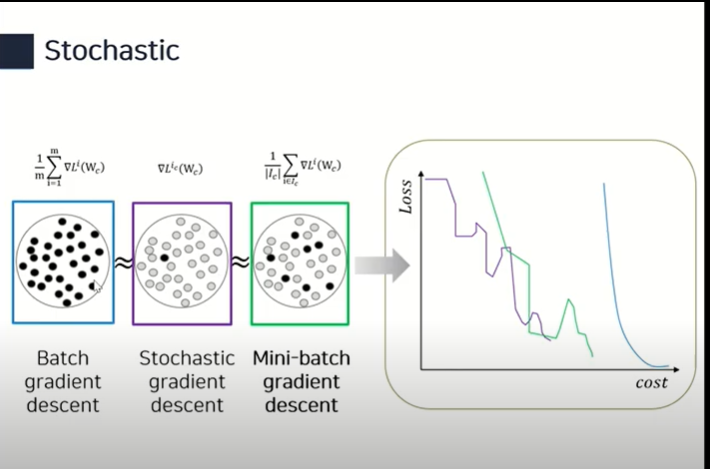
경사하강법은 3가지 종류로 구분된다. Stochastic gradient descent Update with the gradient computed from a single sample Mini-batch gradient descent Update with the
2.최적화 - Regularization

generalization gap 을 줄이기 위해 사용파라미터들이 너무 커지지 않게 파라미터들의 제곱을 더해서 패널티로 부여데이터를 늘려서 deep learning의 이점을 극대화 할 수 있음.노이즈를 train data, weight에 주게 되면 성능이 올라가는데 이
3.GAN
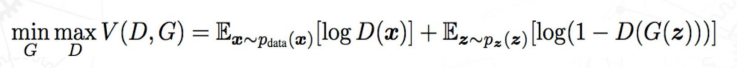
: We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative m
4.활성화 함수 - Activation function
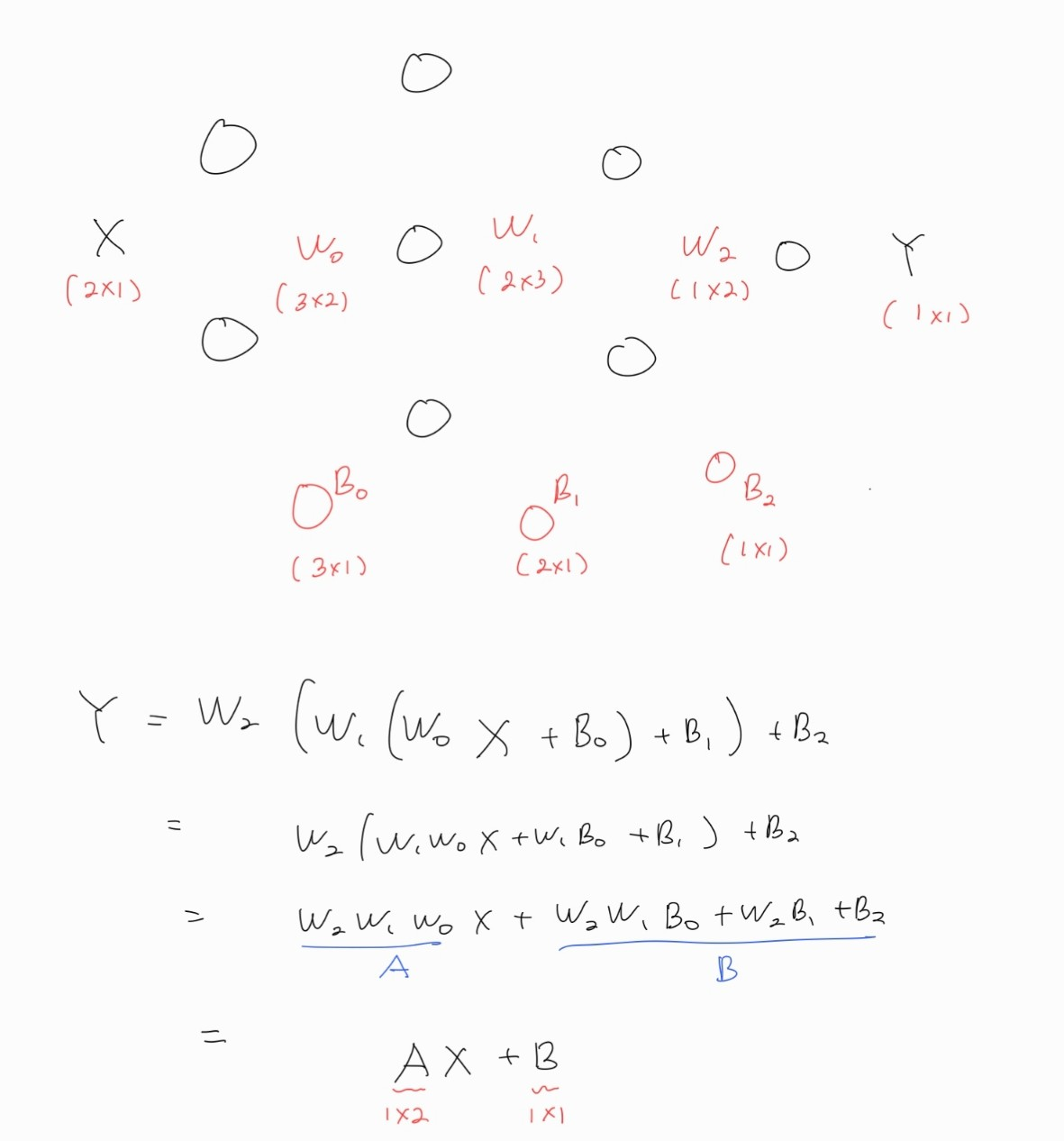
만약 활성화 함수가 없다면 선형변환의 중복은 선형변환이 된다. 아래는 간단하게 3층짜리 layer를 가진 활성화 함수 없는 신경망이다. (또는 활성화 함수가 y=x 라고 할 수도 있다.) 이 변환을 쭉 계산해보면 아래 그림처럼 $Y = AX+B$ 꼴이 나오고, 이는 결
5.Loss function
머신러닝 종류에는 지도학습과 비지도학습 그리고 강화학습이 있다.이 포스트에서는 지도학습과 비지도학습의 loss function을 다룬다.지도학습 문제는 회귀 문제와 분류 문제로 나눌 수 있다.만약 예측값이 연속적인 값을 가진다면 그건 회귀문제이다.회귀에서는 정답값과 예
6.Layer Normalization
Layer Normalization은 Batch Normalization과 함께 Normalization을 시켜주는 방법이다.딥러닝에서의 Normalization의 효과는 다음과 같다.일반적인 경우 layer의 활성화함수 직전에 batch normalization을 배
7.Entropy (엔트로피)
엔트로피란 정보량의 가중평균이다.정보량을 계산할 때 중요한 점은 뻔한 이야기일수록 정보량이 낮다는 것이다.우리가 통신을 하려고 정보를 송신하고 있는데, 오늘 해가 떴다는 사실을 송신한다고 하자.이런 당연한 이야기는 들어도 전혀 놀라지 않을, 즉 정보량이 없는 것이다.반
8.라그랑주 승수 (Lagrange Multiplier)
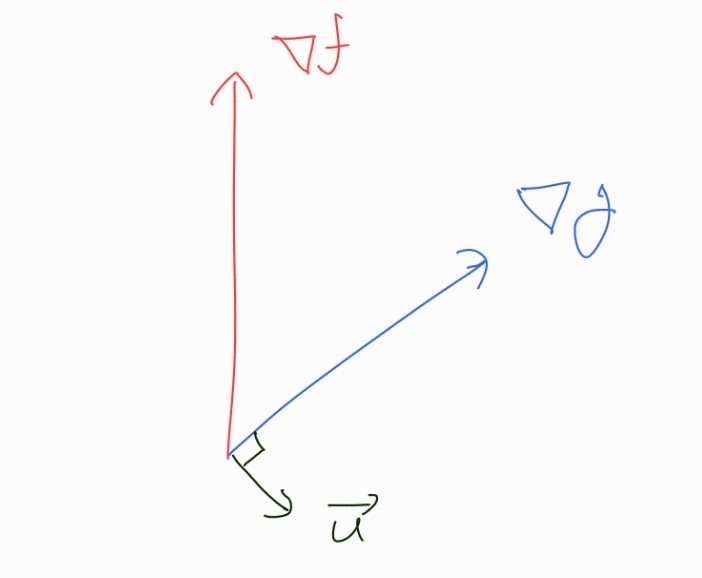
이 방법은 제약조건(Contraint)이 있을 때, 최적화 문제를 푸는 방법이다.제약조건이 없는 상황에서의 최적화 문제를 푸는 경우엔 간단히 미분을 통해서 해결할 수 있다.만약 우리가 함수 f(x) 의 최솟값을 찾는 최적화 문제를 풀고 있다고 생각해보자.그렇다면 우리는
9.Association Rule Mining
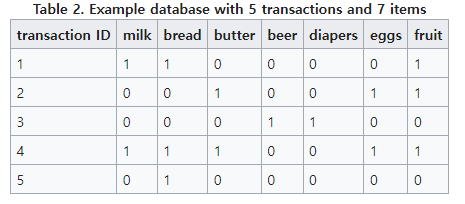
참고자료1\. 강필성 교수님 강의2\. https://en.wikipedia.org/wiki/Association_rule_learning연관 규칙 분석이란 item set X,Y에 대해 'X를 사면 Y를 산다.'와 같은 규칙, 즉 X->Y 에 해당하는 X,Y
10.Support Vector Machine (SVM)
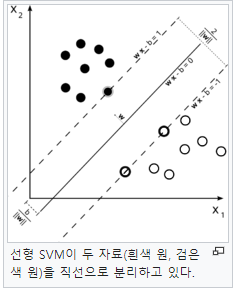
참고자료1\. 김성범 교수님 강의2\. 위키백과3\.서포트 벡터 머신은 이진 분류를 위한 분류 모델이다.SVM은 이진 분류를 수행하기 위해 두 클래스의 경계면을 찾는다.만약 데이터가 단순히 2차원 상에 존재한다면 경계면은 직선, 3차원이라면 평면이 될 것이다. 즉, n
11.밑바닥부터 시작하는 딥러닝 3권 리뷰
해당 글은 밑바닥부터 시작하는 딥러닝 3권에 대한 글입니다. 1. 책 리뷰 이 책은 총 5장으로 이루어져 있으며 각각의 장에서 다루고자 하는 내용은 다음과 같다. (책에서는 각각을 '고지' 라고 표현하지만 이 글에서는 장이라고 표현한다.) 1장 - 미분 자동 계산
12.Feature Selection 1 - Information Gain
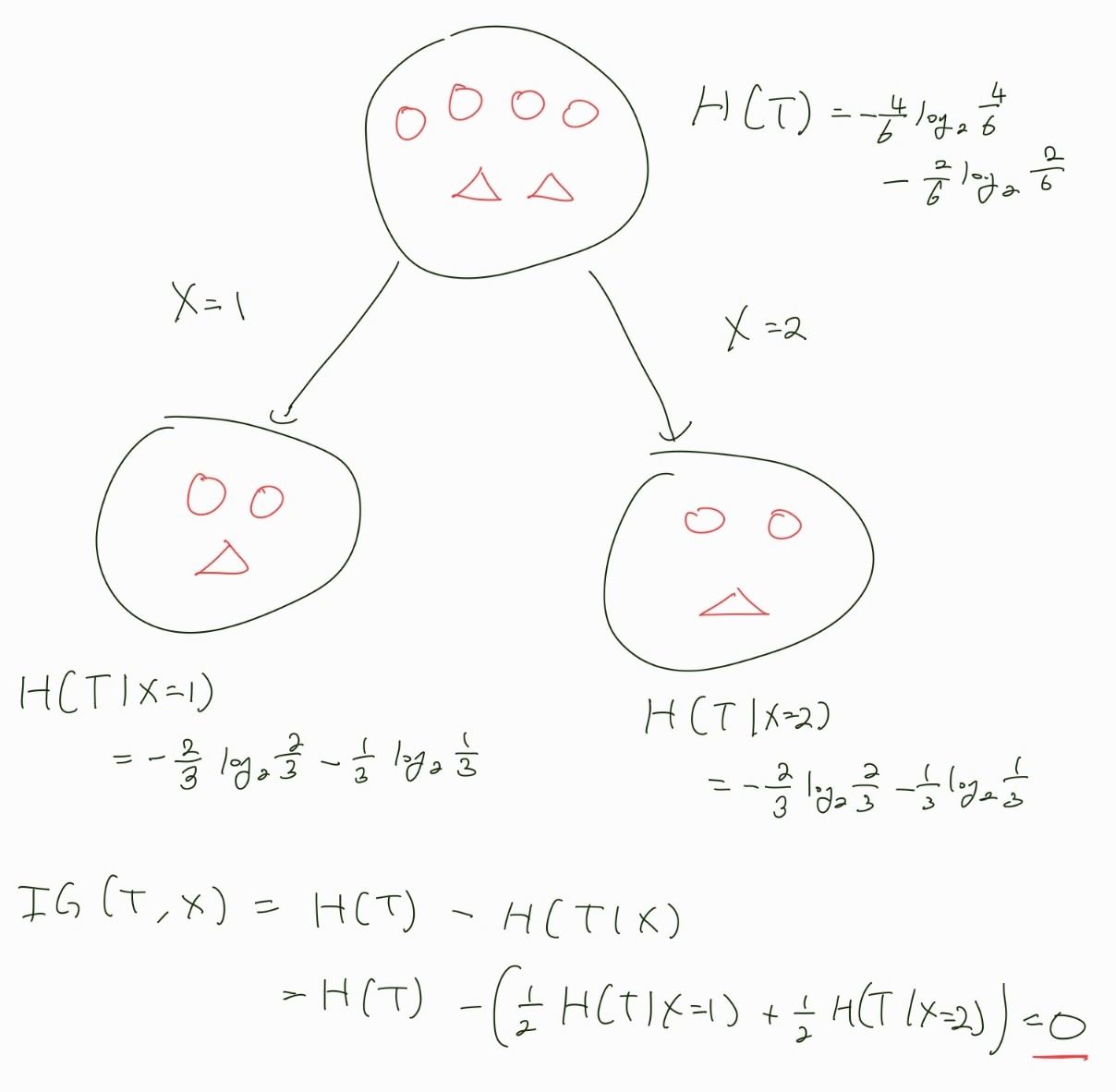
1
13.AutoML과 Bayesian Optimization
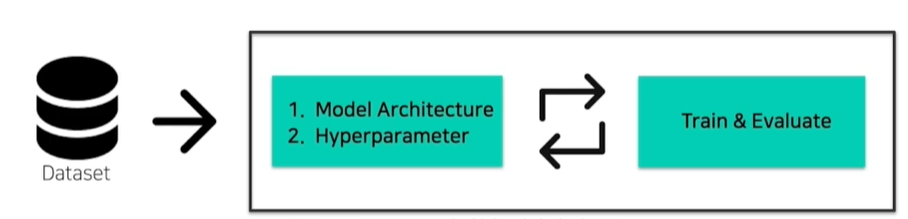
머신러닝 프로세스는 보통 어느 정도 데이터 전처리가 끝난 후 다음과 같이 model과 hyperparameter를 찾는 과정을 거치게 된다. (물론 나중에 다시 데이터를 수정하기도 한다.)실험 전 자원과 데이터를 보고 가장 좋은 model 구조와 hyperparamet