해당 글은 아래 글을 base로 두고 공부하며 이해해 필요한 자료들과 함께 내용을 정리한 글입니다.
이 포스트에서는 1. MoE란 무엇인지, 2. MoE에서 다루게 되는 Load Balancing 문제란 무엇인지, 3. 언제 쓰면 좋은지 를 다루고 있으며 목차는 이에 맞게 재구성했습니다.
https://huggingface.co/blog/moe#what-is-a-mixture-of-experts-moe
1. Mixture of Experts (MoE)?
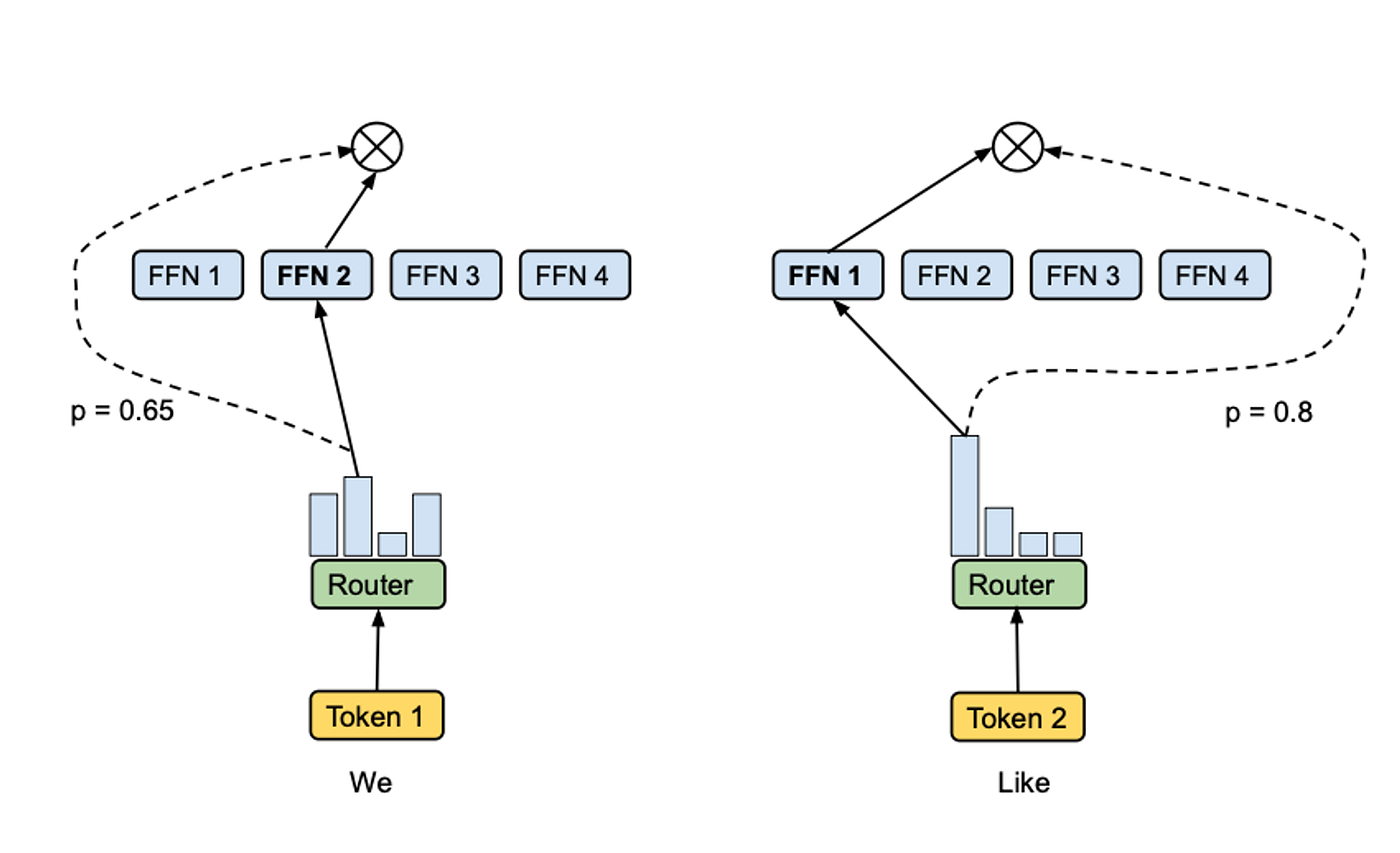
MoE는 일반 모델과 다르게 1. 여러 전문가 네트워크를 두어 2. 입력에 따라 전문가 일부만 활성화시키는 구조이다.
MoE를 이해하기 쉽게 이전에 나왔던 연구들을 잠깐 살펴보자.
A Brief History of MoEs
MoE의 뿌리는 1991년에 나온 Adaptive Mixtures of Local Experts라는 논문이다.
이 연구를 보면 여러 전문가를 두었다는게 어떤 말인지 알 수 있다.
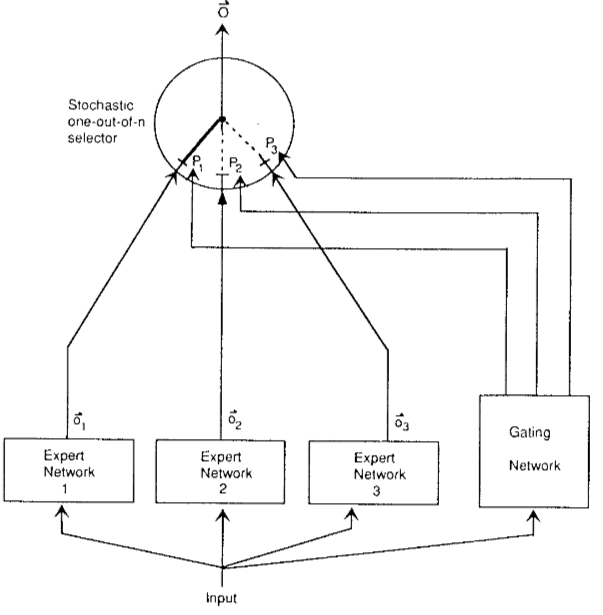
위 그림은 해당 논문 모델 구조인데, 동작은 아래와 같다.
- 각각의 Expert Network는 FFN으로 전문가 역할 수행
- Gating Network는 각각의 전문가 값을 얼만큼의 가중치로 활용할건지 결정 (소프트맥스 활용)
- 출력값 = (i 번 전문가 가중치) x (i번 전문가 출력값)
여기서 중요한 점은 여러 전문가 네트워크가 있고, 입력에 따라 Gating Nework가 전문가의 의견을 얼마나 반영할지 결정한다는 것을 보면, 입력에 맞는 전문가에게 힘을 더 실어준다는 의도가 보인다.
기타 아무 생각
- 여러 모델을 쓰고 가중치를 두어 결과를 합산하는게, 머신러닝에서 쓰이는 소프트 앙상블이랑 거의 비슷한 아이디어로 보인다.
- 그냥 앙상블과 다른 점은 입력을 기반으로 가중치를 결정한다는 건데 이런 점이 조금 더 좋은 결과를 낼 수 있을 것 같다.- 아이디어가 합리적이라고 해야할까... 잘 작동되겠는데? 라는 생각이 들어서 저자가 누군지 봤더니 제프리 힌튼 형님
하지만 위 연구를 보면 아직 2. 입력에 따라 전문가 일부만 활성화하진 않고 전부 활성화해서 계산량이 높다는 것을 알 수 있다. 이러한 특징은 뒤 이은 연구에서 볼 수 있다.
2010 ~ 2015 사이에 나온 두 가지 연구 흐름 (+ Conditional)
두 가지 연구 흐름이 현대 MoE 구조에 영향을 끼치게 된다.
- Experts as components
- 이전까지는 MoE를 하나의 전체 네트워크로 사용했다면 이제는
하나의 구성 요소로 사용해서 더 깊은 모델 만들기!
- Conditional Computation
- 모든 layer 활성화하지 않고 input token에 따라 동적으로 일부 layer 활성화
위 두 가지 흐름을 가지고 나온 모델 구조가 아래 구조 (137B나 되는 LSTM) (논문)
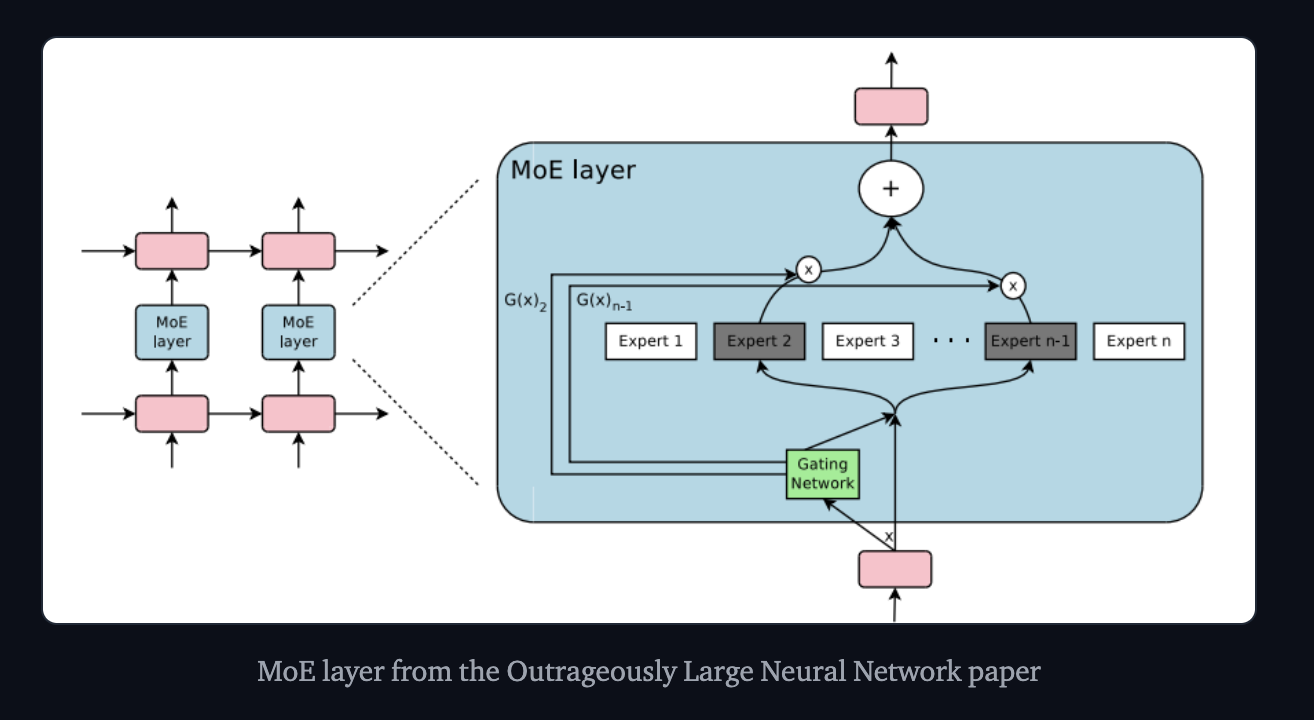
- 여기서 보면 MoE가 하나의 구성요소로 사용된 걸 볼 수 있음
- MoE 내부에서 Expert가 모두 작동되지 않고 conditional하게 작동되는 걸 볼 수 있음
위 구조는 LSTM에서 1. 여러 전문가 네트워크를 가지고 2. 입력에 따라 전문가 일부만 활성화 하는 것을 볼 수 있는데, 이게 현대 MoE의 구조이다.
Conditional은 간단하게 구현할 수 있는데 Router(=gate network)를 거친 후에 top k개의 전문가만 뽑는 것이다. 식으로 보면 아래와 같다.

- 입력이 라우터를 거친 후 노이즈를 더하여 스코어를 뽑는다. -> 노이즈를 더하는 이유는 load balancing 부분에서 나온다.
- k개만 쓸거니까 정규화 softmax(-inf)값은 0이라 쓰지 않겠다는 의미다. -> 즉, 해당 전문가는 꺼도 된다.
- 합쳐서 1 되도록 정규화 한다.
MoE + Transfomer
최근은 주로 Transformer에 MoE를 결합한 형태를 많이 사용한다.
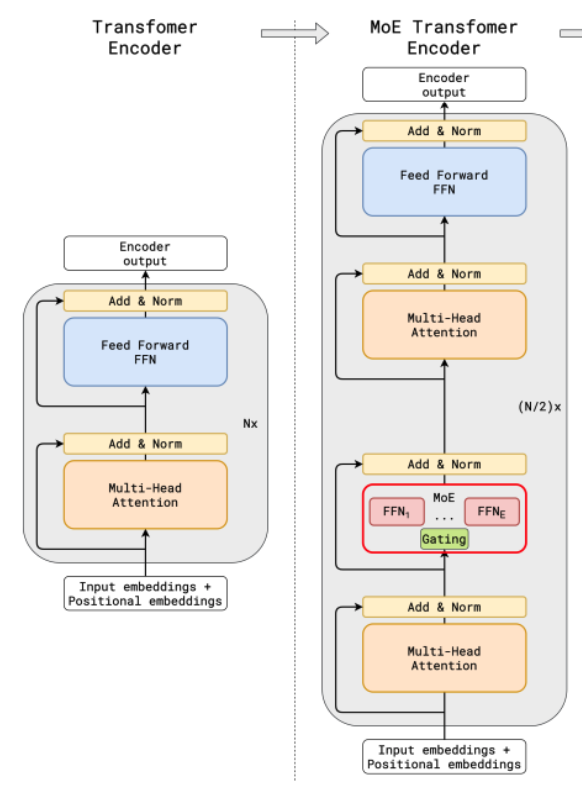
다양한 방식이 있는데, 예를 들어, 위 그림과 같이 Transformer에서 Attention 부분은 기존대로 유지하고, FFN 부분을 MoE layer로 대체해서 사용한다.
이때 2. 입력에 따라 전문가 일부만 활성화 에서 입력이란 개별 token이고, router가 적절한 전문가한테 보내주는 형식이다.
전문가는 뭘 배울까?
여러 전문가가 각각 어떤 걸 배우는지 ST-MOE 논문에서 볼 수 있다.
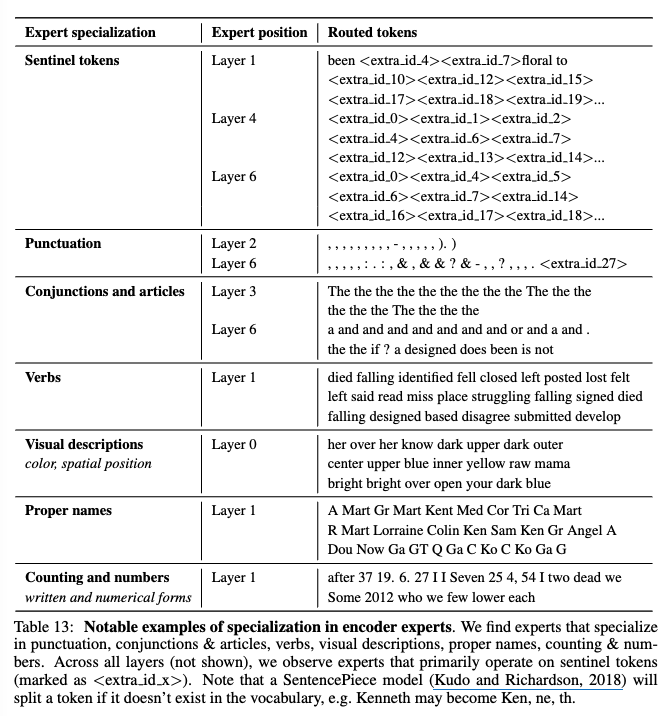
위 사진은 논문에서 7. Tracing Tokens Through the Model에 해당하는 부분으로, 학습된 모델에게 토큰을 넣고 어떤 전문가에 할당되는지 확인한 것이다.
해당 모델은 아래와 같은 task를 수행하도록 학습되었다.

표 그림을 보면 각각의 Expert마다 잘하는(책임지는) 부분이 있는 걸 확인할 수 있다.
sentinel tokens에 특화된 전문가, Puncuation에 특화, Verbs에 특화된 전문가 등등...
2. Load Balancing
MoE 학습에서는 한 가지 주의할 점이 있다.
일반적은 MoE 훈련에서 어떤 전문가로 보낼지 결정해주는 router가 학습하면서 소수의 전문가만 활성화 하는 경향이 있다.
이렇게 되면 특정 전문가들이 더 많이 학습되고, 훈련을 많이 받은 전문가들이 자주 선택되게 되면서 self-reinforcement가 발생한다.
이렇게 일부 전문가에게 선택이 치중되는 현상을 방지하기 위한 해결 책으로 몇 가지 방법이 있다.
Noisy top-k gating
위에서 잠시 router 알고리즘을 확인했는데, 거기서 노이즈를 더하는 식이 나온다. 이러한 노이즈를 더하는 이유는 무작위성을 더해서 균등하게 분배되도록 하는 의도가 담겨있다.
Random routing
Top-2 라우팅 설정에서 가장 높은 점수를 나온 전문가 둘을 선택하는게 아니라 가장 높은 점수를 가진 전문가 하나와 가중치에 비례하는 확률로 나머지 전문가를 선택하는 방법이다.
Auxiliary Loss
이 방식은 Loss를 통해서 제어하는 방식이다.

위 그림은 switch transformers 논문에서 가져온 Auxiliary Loss에 대한 사진이다.
notation을 정리 겸 아래 식을 해석하면 아래와 같다.
N : 전문가 수
B : 배치 사이즈
T : 총 토큰 수
p(x) : 각 토큰 x에 대해 전문가 선택 확률 분포
: i 전문가에 할당된 토큰 비율
: 토큰 전체적으로 router가 i 번째 전문가를 선택할 확률
: 하이퍼 파라미터
해당 loss의 경우 f와 p 벡터가 모두 uniform distribution이 될 때 최소가 되므로, f와 p 모두 1/N이 되도록, 즉 모든 전문가에게 균등하게 분배되는 것을 목적으로 학습
Expert Capacity
Load balancing을 해야하는 이유가 학습 외에도 overflow를 방지하기 위함이다. 이를 위해 각 전문가에게 할당될 수 있는 토큰에 제한을 두고 나머지는 drop하는 등의 조치를 취하는 방법이다.
잡담
load balancing을 위해 분배가 중요하지만 무작위성은 전문가의 전문성을 해쳐서 성능을 저하시키는 요인이 될 수 있지 않을까 싶다.
예를 들어, 코드 토큰을 위주로 학습하고 있던 전문가에게 load balancing을 이유로 언어 토큰을 준다면..?이런 의미에서 과도한 load balancing은 좋지 않을 것 같다. (갑자기 든 생각이라 확실하진 않다)
3. MoE를 언제 쓰는지?
MoE를 쓰면 좋은 점 = 모델의 크기 늘리기
모델의 규모가 커질수록 모델의 퀄리티가 높아지는 것을 토대로 생각하면 computing 자원이 고정된 상황이라면 큰 모델을 적게 훈련 시키는 것이, 작은 모델을 여러 번 훈련시키는 것보다 이득이 된다.
MoE의 Sparsity라는 특성으로 인해 이게 가능하게 되는데, 결과적으로 동일 computing 예산 하에서 Dense 모델에 비해 모델의 크기를 늘릴 수 있다는 장점이 있다.
Sparse model과 대조되는 개념으로는 Dense model이 있는데, Dense model은 모든 parameter가 활성화 되는 모델을 말한다.
Sparsity는 일부 파라미터만 활성화하여 conditional computation을 가능하게 만드는 것인데, conditional computation을 사용함으로써 연산량을 증가시키지 않고 MoE의 전문가를 늘리면서 모델의 크기를 확장할 수 있게 한다.
한편, 이렇게 MoE가 모델의 크기를 늘릴 수 있지만, 늘린 만큼 요구 VRAM이 커져서 VRAM 용량이 충분할 때 사용할 수 있다.
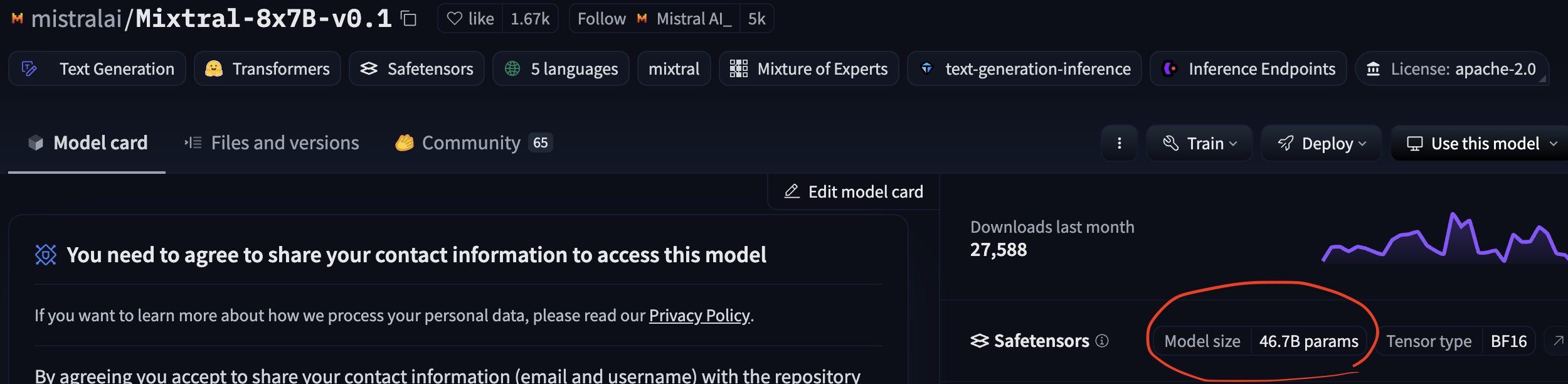
- 예를 들어 Mixtral 8x7B 모델을 사용한다고 하면 VRAM을 47B 파라미터를 감당하도록 해야함.
왜 56B가 아닌 47B지?
-> 전문가 이외의 파라미터는 공유하기 때문에 실질적인 파라미터는 47B
모델의 크기를 늘리는게 정답이면 전문가를 엄청 많이 늘리면 되는거 아닌가?
전문가의 수가 늘어나면 샘플 효율성이 늘어나지만 어느 수준에서는 늘려도 VRAM만 늘어나지 큰 효과가 없음 (주로 256이상부터 이런 현상이 보인다고 함)
여기서 샘플 효율성이 좋아졌다는 말은 전문가가 늘어나면서 모델의 크기는 커지지만 필요한 데이터 양은 그대로기 때문에 해당 크기의 모델을 학습하는데 필요한 데이터 양이 줄어들어 효율이 좋아졌다는 의미로 이해됨. (이 부분은 본문에 자세히 나와있지 않아서 확인 필요!)
나가는 글
요즘 이슈가 되는 모델들은 MoE를 많이 사용하고 있기에 MoE 대해서 간단하게 개념을 정리해봤다. 추후 기회가 되면 Fine-tuning, Inference에 대해서도 포스팅 할 예정이다.
