LLM
1.MoE (Mixture of Experts) 간단 개념
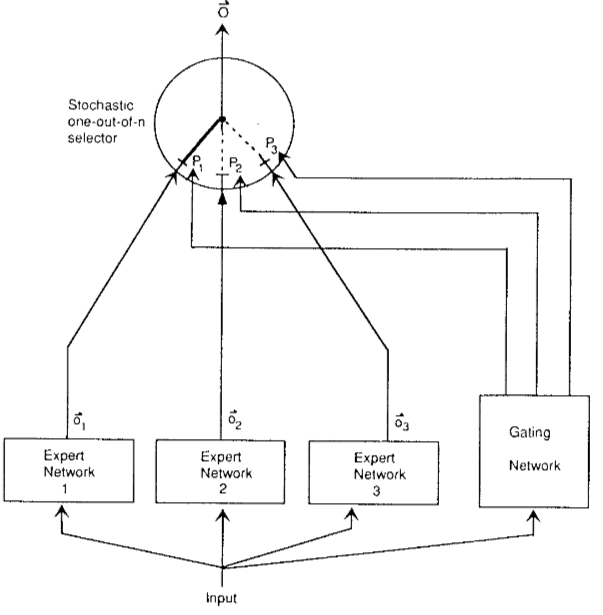
해당 글은 아래 글을 정리한 내용입니다. 목차는 아래 글과 동일하게 구성했으며 중간중간 이해에 필요한 추가 자료를 넣었습니다.https://huggingface.co/blog/moecomputing 자원이 고정된 상황이라면 큰 모델을 적게 훈련 시키는 것이,
2. Stanford CS224N: NLP w/ DL | Spring 2024 | Lecture 12 - Efficient Training, Shikhar Murty
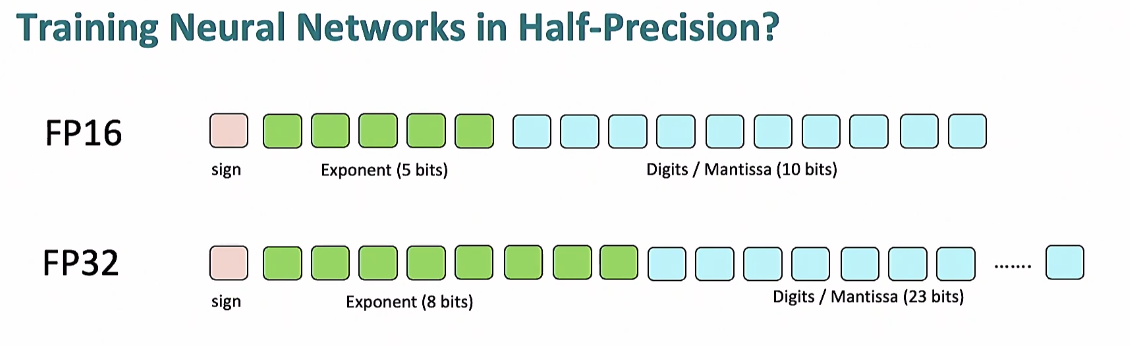
참고자료https://tutorials.pytorch.kr/beginner/dist_overview.htmlDTensor와 DeviceMesh는 N차원 프로세스 그룹 위에서 샤딩되거나 복제된 텐서 기반 병렬 처리를 구성하기 위한 기본 구성 요소DTensor :
3. [kakao tech 리뷰] All About LLM: 카카오 AI메이트, 학습부터 서빙까지의 모든 것 - 작성중
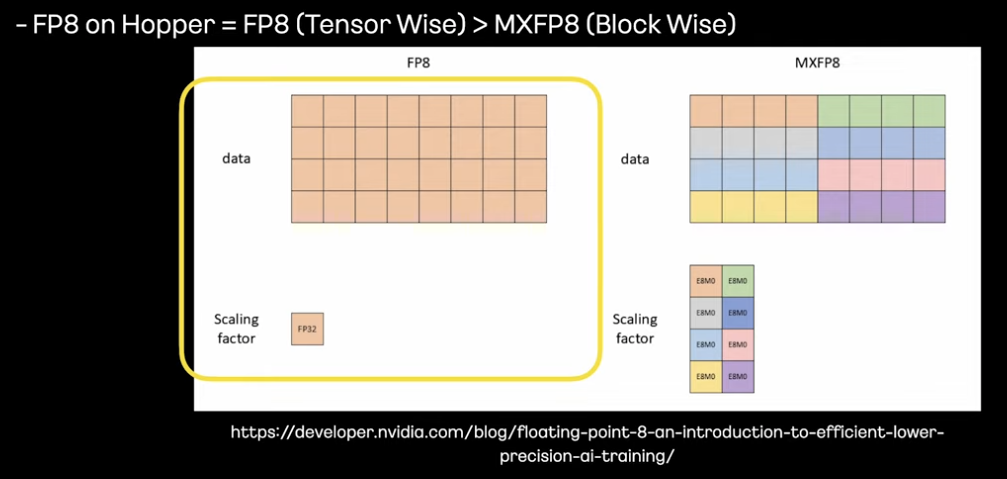
해당 글은 kakao tech 발표 내용을 바탕으로 정리한 글입니다. > 참고 자료 https://www.youtube.com/watch?v=U0IqPwxydHE&t=340s 1. AI 메이트, 손쉽게, 똑똑하게, 빠르게 손쉽게 = LLM 기반 오케스트레이터 (직
4.Stanford CS336 Language Modeling from Scratch | Spring 2025 | Lecture 7: Parallelism 1
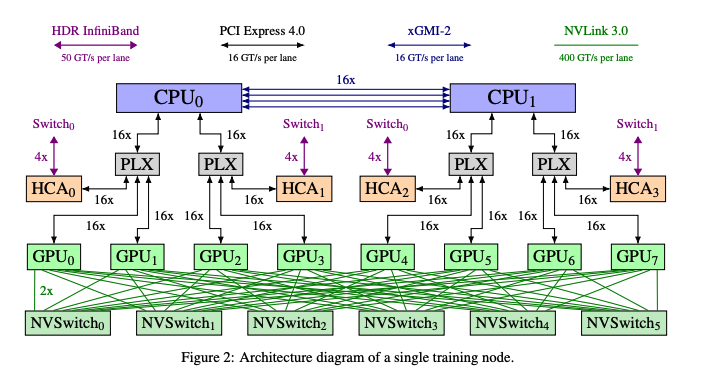
위 그림에서 하고 싶은 말은 노드 내부 GPU 통신은 400 GT/s per lane인 반면, GPU 외부 통신은 50 GT/s per lane. 즉, 외부 노드 간 통신 보다 노드 내부 통신을 쓰는게 유리하다는 inter node <<< intra n
5.[kakao tech] 필요한 순간 말을 걸어주는 온디바이스 AI
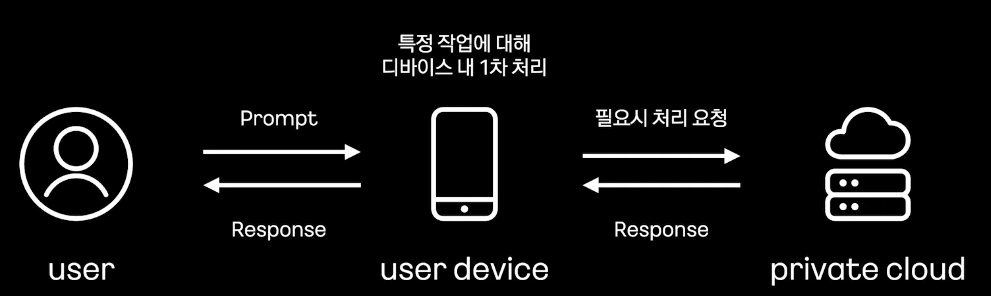
해당 글은 kakao tech의 발표 내용을 듣고 일부를 재구성하여 정리한 글입니다. 발표 자료https://www.youtube.com/watch?v=4wwsyiLmVkA&list=PLwe9WEhzDhwG1H81qHrjc05sj75cGa1fi&index=1
6.Preference tuning에서의 Reward Model
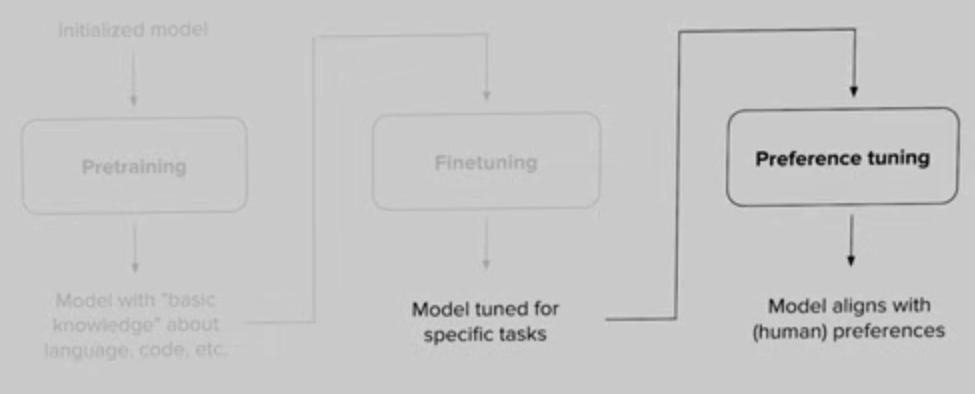
참고 자료https://www.youtube.com/watch?v=PmW_TMQ3l0I&list=PLoROMvodv4rOCXd21gf0CF4xr35yINeOy&index=5일반적으로 LLM 모델 학습은 아래와 같은 세 단계를 거친다.Pretraining\->
7.RLHF와 관련된 알고리즘들 (REINFORCE, PPO, GRPO)
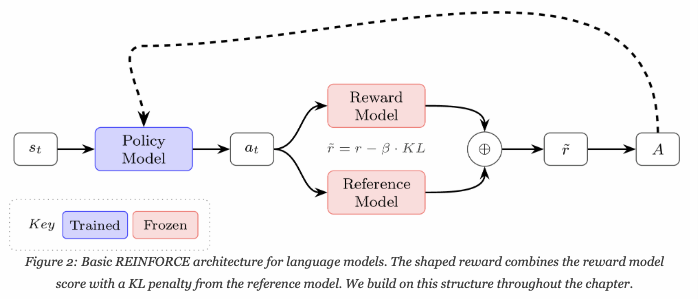
해당 글은 아래 참고자료를 보고 일부를 정리한 내용이다. > 참고 자료 https://rlhfbook.com/c/06-policy-gradients#ref-schulman2015high 언어모델 RLHF에서 자주 쓰이는 알고리즘들은 policy-gradient 기반