해당 글은 아래 강의를 듣고 정리한 글입니다.
1. Miexed Precision Trainging
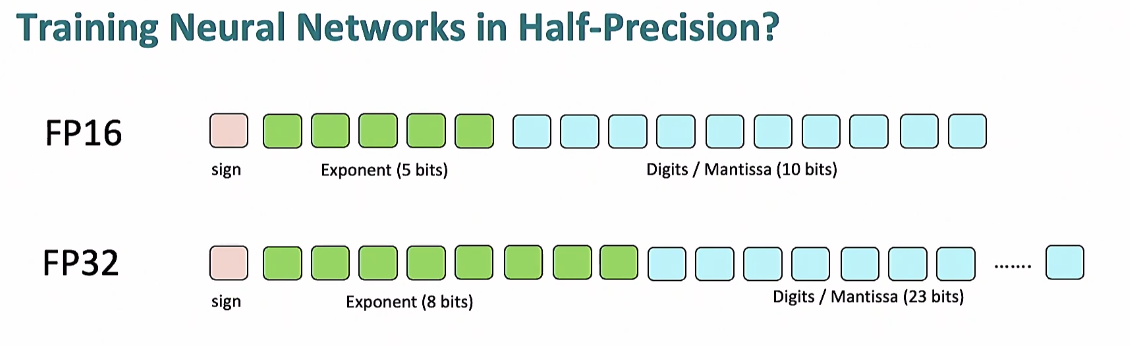
FP32보다 FP16은 지수부와 가수부 모두 줄어들었는데 이는 각각 수의 표현 범위, 정밀도가 줄어든다는 것을 의미한다.
FP32 최대 표현 범위 ≈(2−ϵ)×2^127
FP16 최대 표현 범위 ≈(2−ϵ)×2^15
normal의 경우
FP32 최소 표현 범위 ≈1.0×2^−126
FP16 최소 표현 범위 ≈1.0×2^-15
denormal (지수부가 0인 경우)
FP32 최소 표현 범위 = 2^-149
FP16 최소 표현 범위 = 2^-24
FP16으로 학습시킬 때 생길 수 있는 문제점
-
underflow - 만약 굉장히 작은 수라면 0이 되고, 굉장히 큰 수는 NaN이 됨 (지수부 모두 1)
-
정밀도의 한계로 인해 rounding error
ex) FP16 에서는 1.0001이 1이 됨
가수부의 마지막이 1이어도 2^-10≈0.001 이므로
솔루션 - Mixed Precision Training

진짜 저장용 파라미터는 FP32로 유지하고, 실제 GPU에서 계산되는 것들은 FP16으로 계산.
업데이트 직전에 FP32에서 업데이트
과연 안전할까? -> underflow
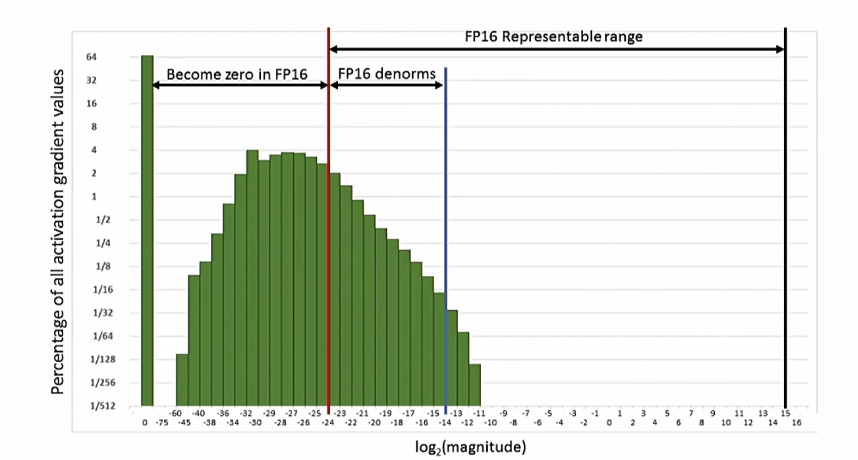
위 그림을 보면 학습 시킬 때 gradient 분포인데, 빨간색 왼쪽 부분은 FP16으로 학습 시 0이 되는 부분이다. 즉, 그냥 FP16으로 바꿔서 학습시킬 경우 0으로 사라지는 부분이 굉장히 많다는 것이다.
솔루션 - scale loss

3번 5번 스텝이 추가됨. loss를 증가시켜서 위 그래프를 오른쪽으로 평행이동 시키는 것.
chain rule에 따라 loss에 상수배 곱해지면 gradient도 상수배가 됨.
gradient가 커진만큼 다시 나눠서 올바른 gradient로 업데이트하게끔 5번 스텝 추가
이건 안전할까? -> overflow
수를 곱해주는 것만큼 이번엔 반대로 overflow 위험이 있을 수 있음
다시 돌아가서 왜 Scale을 했어야 할까?
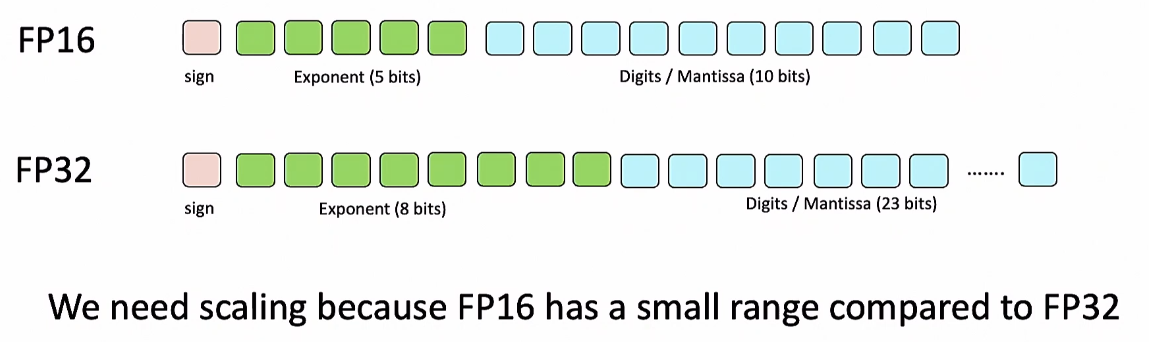
그건 underflow 때문이고, 이 문제는 FP32의 표현 범위보다 FP16의 표현 범위가 굉장히 적기 때문!
그리고 표현 범위는 지수부(초록색)에 의해 결정
-> 그렇다면 정밀도를 희생하고 지수부를 늘려서 underflow 문제를 해결하면?
BFloat16
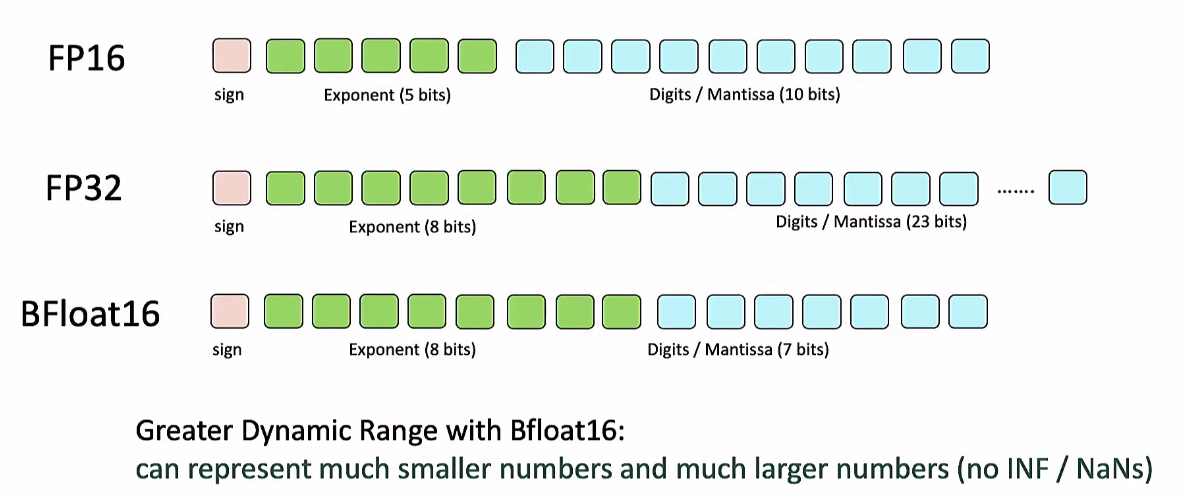
여기서는 underflow 문제가 해결되었으므로 gradient salce을 할 필요가 없음
BF16의 문제는 모든 gpu에서 이걸 지원하진 않는다는 점
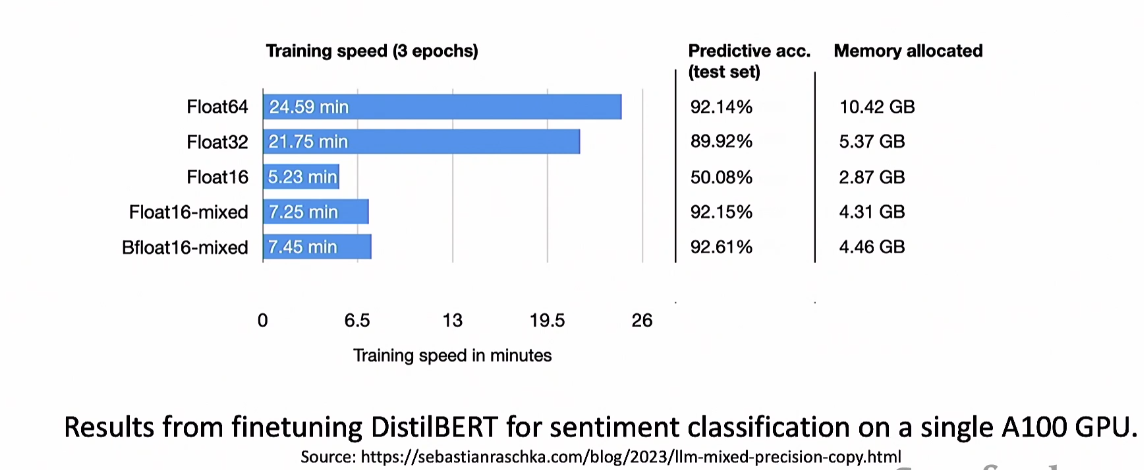
위 결과는 DistilBERT를 각각 훈련한 것
시간을 1/3 정도로 줄여서 학습할 수 있고, memory 부분에서 많은 이득을 가져갈 수 있음
여기서 메모리를 보면 Float16은 Float16-mixed에 비해 메모리가 적은데 이건 mixed precision training에서 master (FP32)를 들고 있기 떄문일 것
결론적으로 왜 mixed precision training을 하냐? 라고 한다면
1. 학습 속도
2. 메모리 절약
2. Multi-GPU Training
일반적인 학습 시 gpu 사용량

기본적인 모델 파라미터 + optimizer 관련 파라미터
DDP (Distributed Data Parallel)
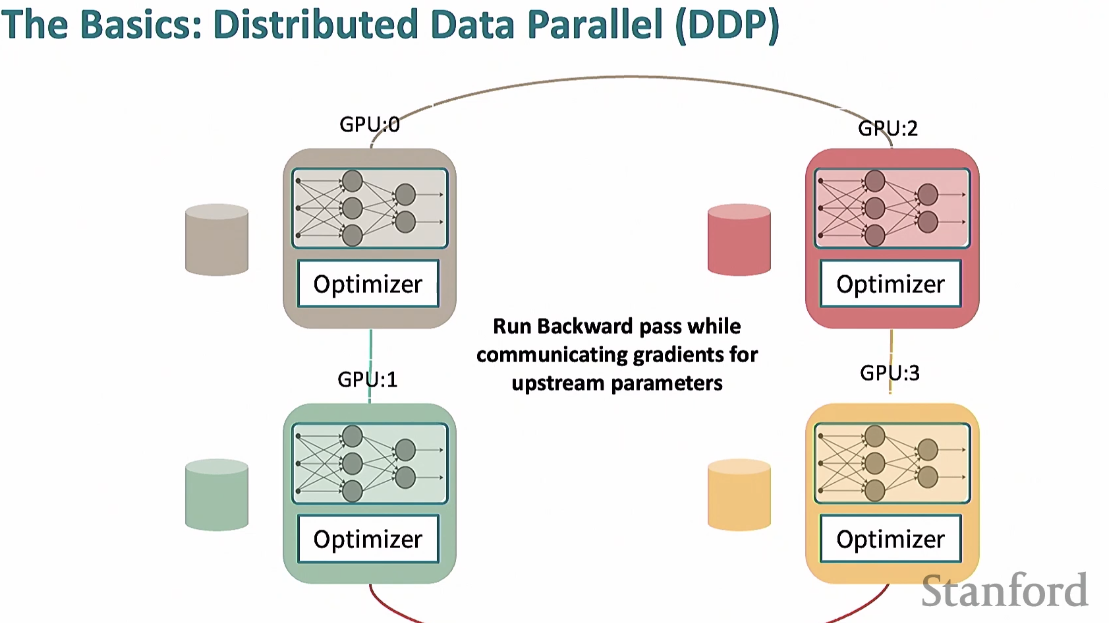
데이터를 나눠서 모두 다 다른 gradient를 가지고 있음.
따라서 동기화를 해야 하는 상황
어떻게?
All reduce

우리는 FP16 gradient를 사용하기 때문에 파라미터 당 2 bytes 소요
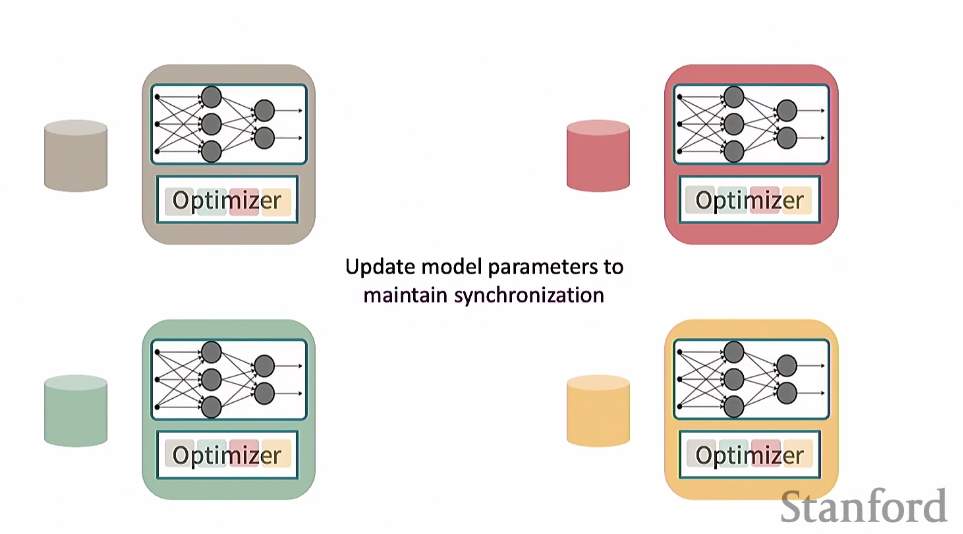
All reduce를 거치고 나면 모든 optimizer가 full gradient를 가지게 되고 이거로 업데이트 하면 동일한 결과를 얻을 수 있음
DDP의 메모리 소비
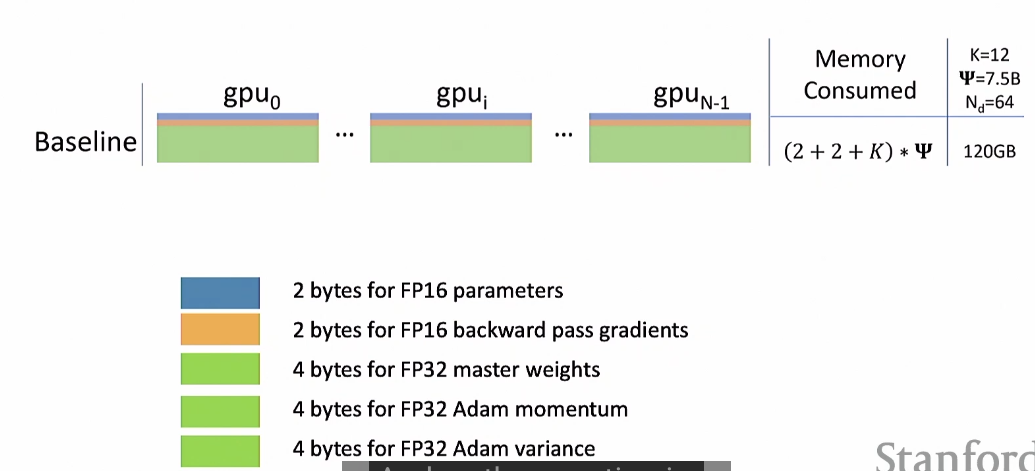
메모리를 조금 더 효율적으로 사용할 순 없을까?
ZeRO (Zero Redundancy Optimizer)
ZeRO = 모든 GPU가 모든 파라미터를 저장하는게 아니라 나눠서 저장하면 어떨까?
ZeRO Stage 1 : Optimizer state Sharding
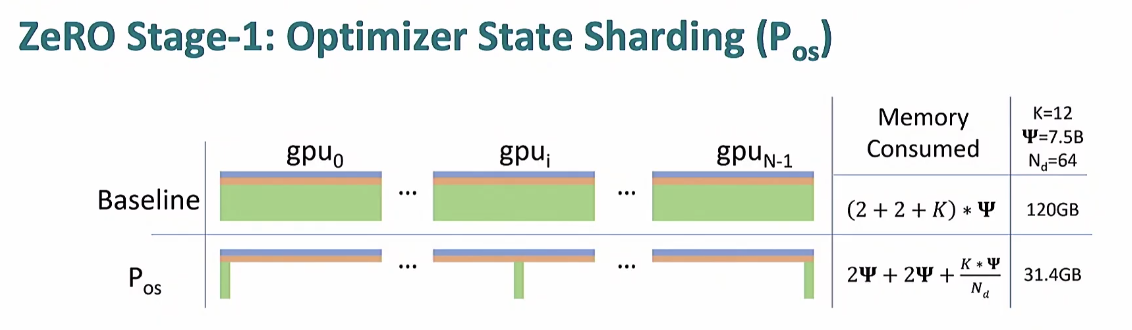
여기서는 optimizer state를 나눠서 가진다.
파라미터를 업데이트 하기 위해서는 gradient와 optimizer가 있어야 하므로, 각 gpu는 자기가 가지고 있는 옵티마이저에 해당하는 파라미터를 업데이트 할 의무를 가진다!


자세한 동작은 위와 같은데,
- 각각의 노드들은 자신들이 가진 데이터에 대해 gradient 구함
- 자신들이 업데이트 할 부분에 대한 정보 받음 reduce-scatter
- 파라미터 업데이트
- 모든 업데이트된 파라미터를 모음 all-gather
-> 원래도 Coummication overhead는 2bytes per parameter 이었으므로 메모리만 아끼고 연산 비용은 그대로!!
ZeRO Stage 2 : Optimizer State + gradient sharding
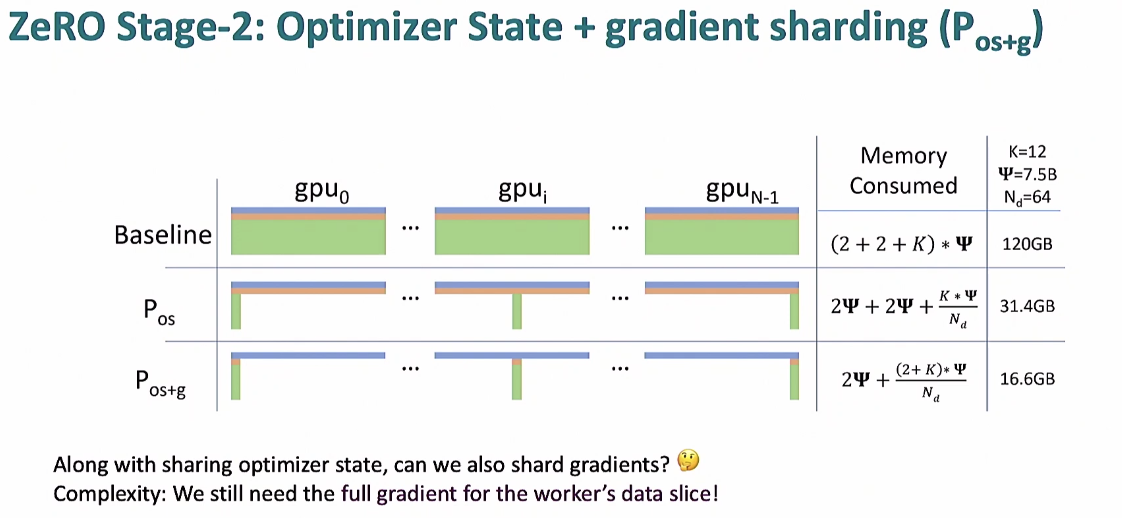
이번엔 optimizer 뿐만 아니라 gradient 까지 sharding

핵심은 backward는 layer 뒤에서부터 계산되므로 이를 활용하는 방식
layer-j를 업데이트 하는 상황
- 모든 rank가 layer-j에서 gradient를 구함
- 그걸 구한 후 해당하는 gradient를 layer-j를 담당하는 worker한테 전달
- layer-j를 담당하는 worker는 optimizer까지 활용해서 파라미터 업데이트 하고, 나머지는 해당하는 gradient 버림
여기도 Coummication overhead는 2bytes per parameter 이므로 추가적인 통신 비용은 없다@!
ZeRO Stage 3 (Full FSDO) : When even the model parameters won't fit
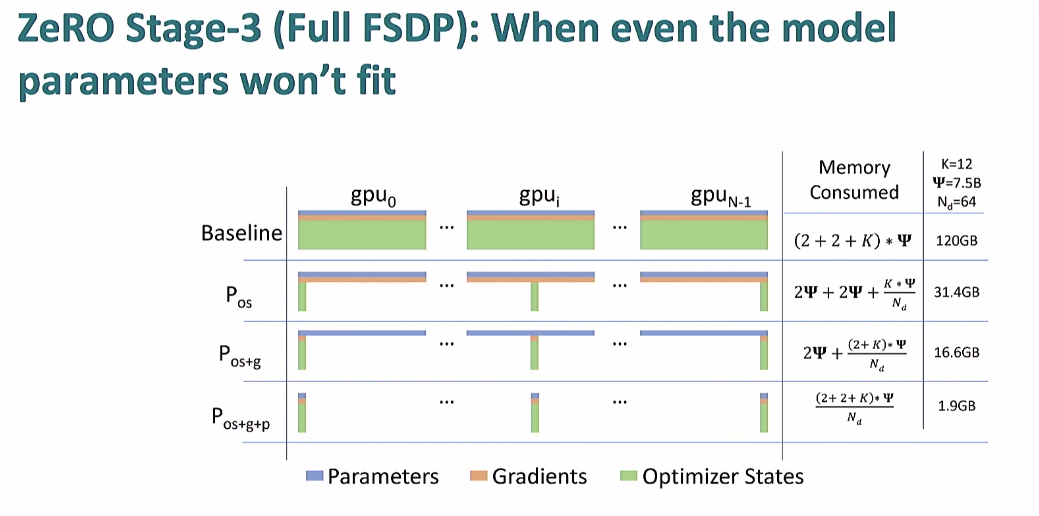
Stage 3의 컨셉은 파라미터까지 분산해서 저장하는 것
주의 : ZeRO Stage 3 부터는 communication overhead가 공짜가 아님
FSDP(Pytorch) = PyTorch의 ZeRO-3(DeepSpeed) 구현 이지만 완전히 같지는 않음
주의 2 : FSDP는 샤딩 정책을 어떻게 하냐에 따라 비효율적이 될수도 있다. model-specific하기 때문에 이 부분을 주의할 것
Communication overhead recap

모델이 GPU에 올라가는 경우 - Zero 2 선택
만약 모델이 GPU 메모리를 초과하는 경우 - ZeRO-3
GPU memory calculation

실제 모델을 올릴 때 Mixed Precision Training을 쓰게 되면, 위와 같이 메모리를 차지하게 된다. 최적화로 adam을 쓰는 경우
- 모델 파라미터 2프사이
- 그레디언트 2프사이
- 마스터 그레디언트 4프사이
- 모멘텀, 분산 8프사이
으로 기본으로 16프사이(모델 파라미터 수) 만큼 가지게 되고,
추가적으로 model activations가 붙게 된다.
model activations는 역전파 할 때 필요한 중간 계산 값
activation memory∝batch size×sequence length×hidden size×num layers
Training Optimizations Recap

3. Parameter-Efficient Finetuning
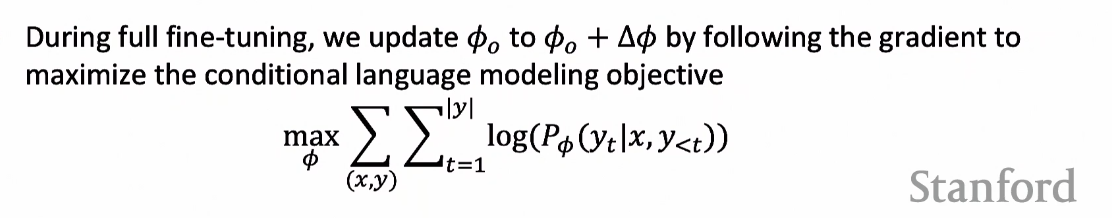
Full fine-tuning의 경우 llm의 목적은 확률을 최대화하는 파라미터 세타를 업데이트 하는 것

한편 Parameter-efficient fine-tuning의 경우 목적은 확률을 최대화하는 모델 파라미터보다 훨씬 작은 세타를 최대화 하는 것
훨씬 작은 파라미터만 업데이트 목표를 가지게 되면, gradient와 optimizer 관련해서 저장할 것들이 줄어든다.
