해당 글은 아래 강의를 듣고 정리한 글입니다.
https://www.youtube.com/watch?v=l1RJcDjzK8M
1. Background knowledge
GPU 간 통신 방식
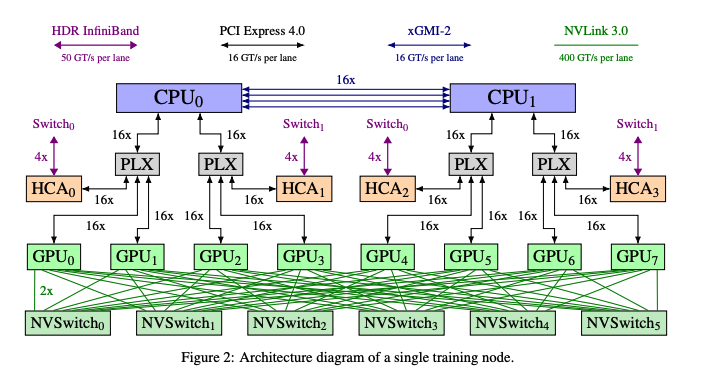
위 그림에서 하고 싶은 말은 노드 내부 GPU 통신은 400 GT/s per lane인 반면, GPU 외부 통신은 50 GT/s per lane.
즉, 외부 노드 간 통신 보다 노드 내부 통신을 쓰는게 유리하다는
inter node <<< intra node
참고
GT/s = 초당 전송 이벤트 수
bit/s = GT/s×(bits per transfer)×(encoding efficiency)
encoding efficiency를 곱하는 이유는 오버헤드 제거
bits per transfer 값 보고 싶으면 기술 별로 다르기 때문에 검색해야함.
Collective communication
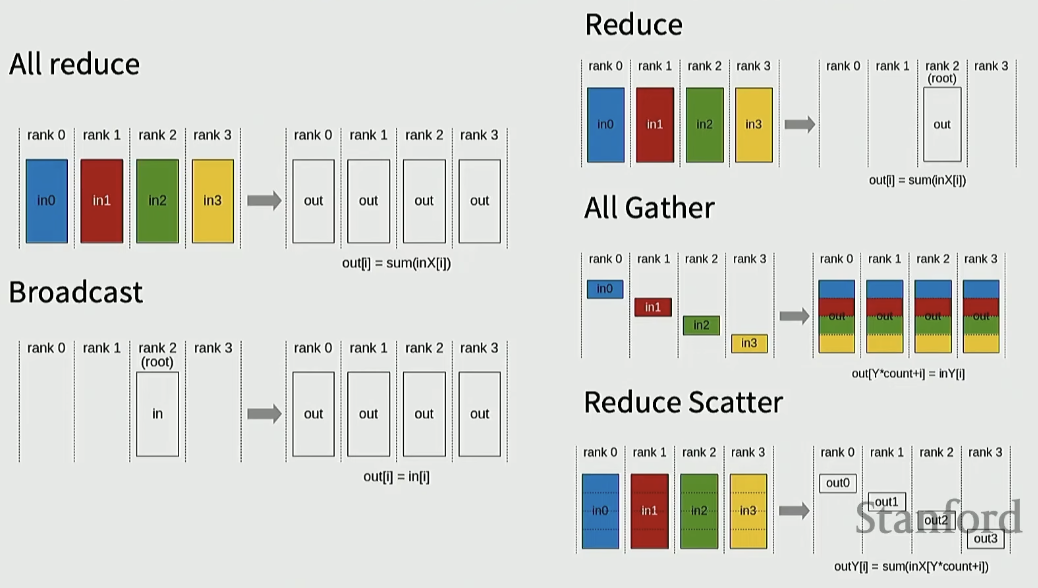
- All Reduce
- 각 rank의 데이터를 reduction(sum, max 등)한 뒤 결과를 모든 rank가 동일하게 가지도록 만드는 연산
- 대략적으로 O(2 * N -(rank 수))
- Broadcast
- 하나의 rank에서 다른 rank로 복사하는 것
- O(N)
- Reduce
- 서로 다른 rank에 있는 정보 하나로 합치는 것
- All Gather
- 서로 다른 rank에 있는 부분들을 모으는 것
- Reduce Scatter
- reduction을 수행하면서 결과를 분할해서 각 rank에 나눠주는 연산
All reduce vs reduce-scatter-gather
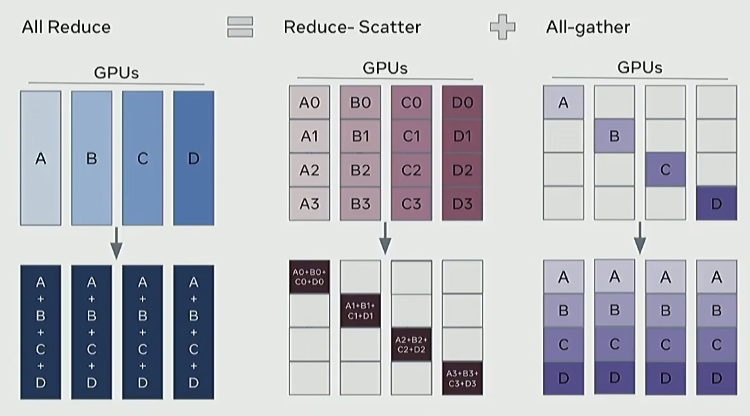
all reduce는 reduce-scatter + all-gather 방식으로 구현할 수 있음
2. Standard LLM parallelization primitives
Data parallelism
- 각 gpu에 파라미터 복사 후 각 gpu는 서로 다른 batch(data)의 일부를 받음
- Naive data parallel
- ZeRO level 1-3
Model parallelism
- 각 gpu가 모델의 서로 다른 부분을 가지고 있는 것
- tensor parallel
- pipeline parallel
Activation parallelism
- sequence parallel
2-1. Data parallelism
Naive data parellelism
Compute scaling
- 각각의 gpu가 B / Machine 만큼의 데이터 받음
Communication overhead
- 2 x # params every batch
- all reduce 연산이 대략 하나의 rank에서 다른 rank로 2번 보내므로
Memory scaling
- None
- 어차피 모든 gpu는 파라미터랑 optimizer state를 가지고 있음
ZeRO 사용
ZeRO stage 1은 optimzer state만 shard
Zero stage 2는 gradient + optimizer state
Zero stage 3는 param + gradient + optimizer state 까지 shard
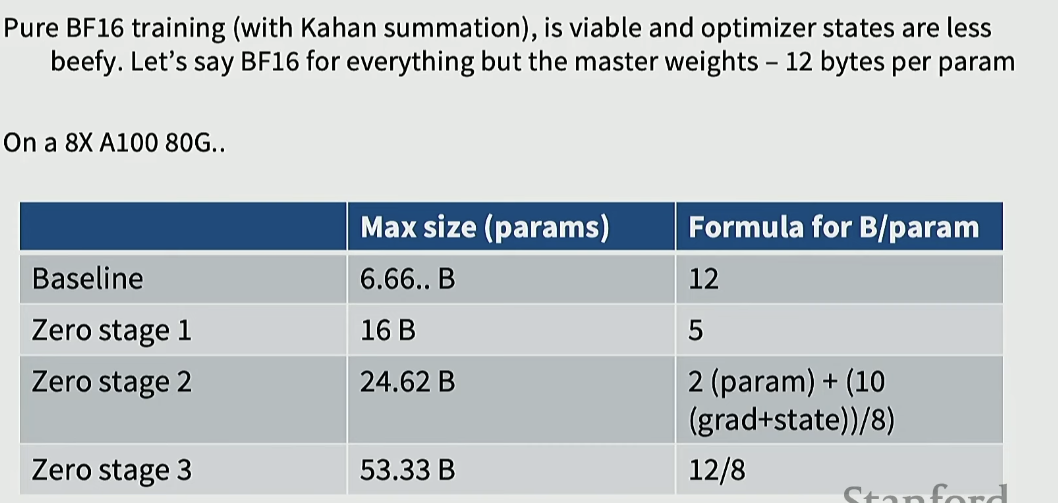
위 그림은 A100 80G x 8에서 몇 크기의 모델을 올릴 수 있는지.
(근데 여기서는 activation memory 계산 안함)
activation memory = 역전파 하기 위해서 필요한 저장값 (액웨 * k..액나)
- activation 미분을 계산하기 위한 activation 들어가기 전 값 + 행렬곱 과정 미분에서 남은 입력 행렬값 (B = WA 에서 W로 미분하면 남는 A값!)
즉, 모든 파라미터를 업데이트할 때 activation 들어가는 값이랑 해당 파라미터와 곱해지는 원본 값이 필요
Data Parallel의 한계 - computint scaling
Batch size를 키우면서 처음에는 학습 속도가 선형적으로 증가하지만 그 이후에는 효율 급감
2-2. Model parallel
파라미터를 교환하지 않고, activation을 교환하는 방식
2-2-1. Pipeline Parallel 관련
Layer-wise parallel
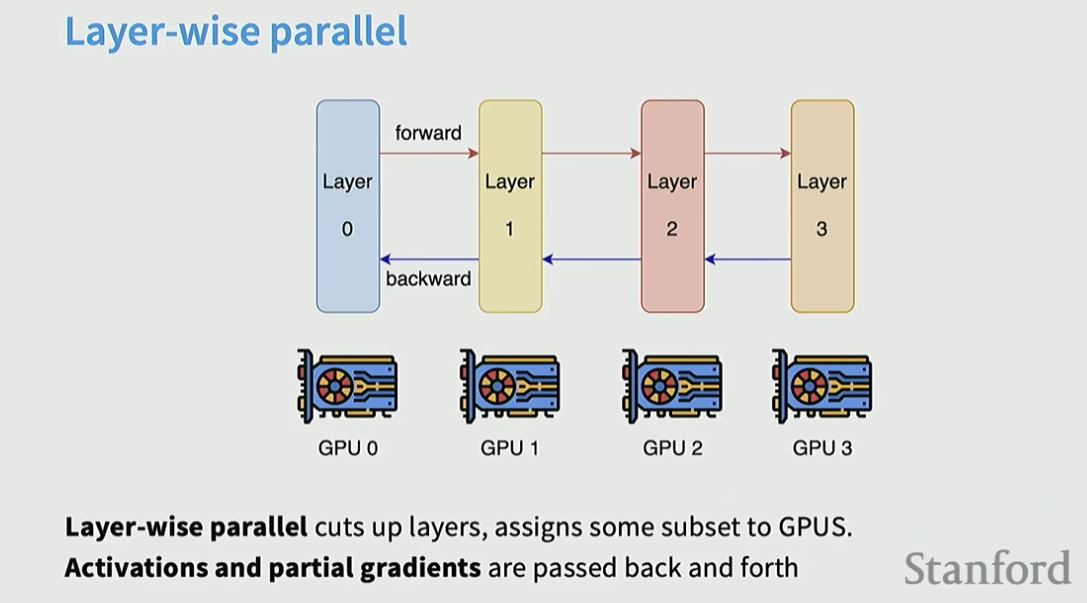
layer-wise parallel은 모델의 각 layer를 다른 gpu에 할당하는 것
그리고 Activation과 gradients들이 gpu간 통신
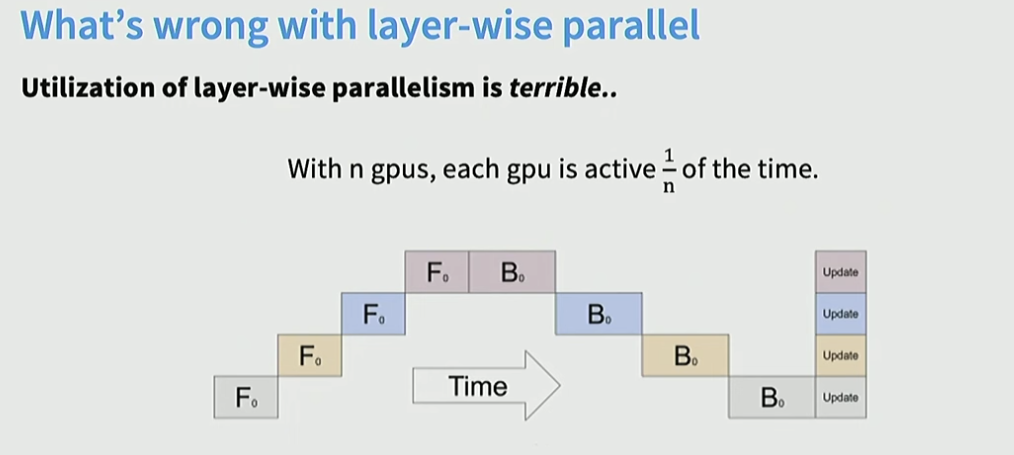
위 방식처럼 하나의 layer를 그대로 쓰게 되면 forward와 backward 모두 기다려야 하기 때문에, gpu를 굉장히 비효율적으로 사용하게 됨
즉, 각각의 gpu가 1/n 시간 만큼만 활성화
이런 문제를 해결한게 Pipeline Parallel
Pipeline Parallel
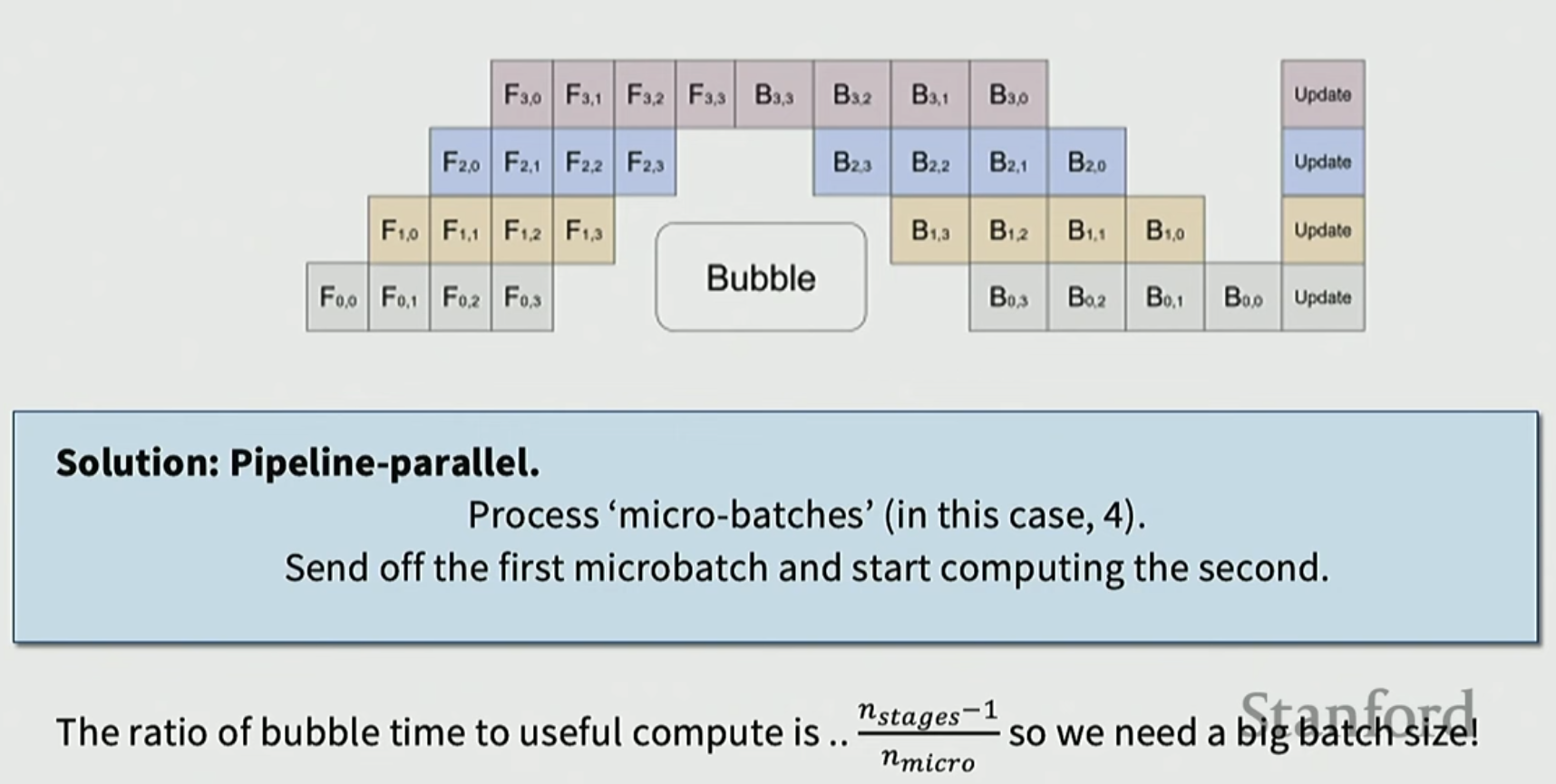
하나의 layer에 들어오는 batch를 micro-batches로 나눠서 순차적으로 돌리는 것
: pipeline으로 나눈 layer group의 개수
: 하나의 batch를 쪼갠 개수 (micro-batch의 개수)
위 예시에서는 3/4이 bubble time이 됨.
bubble time이란 (노는 시간 / 의미 있는 작업 시간)을 의미.
이론상 batch가 무한대로 늘어난다면 bubble time은 0에 가깝게 될 수 있음
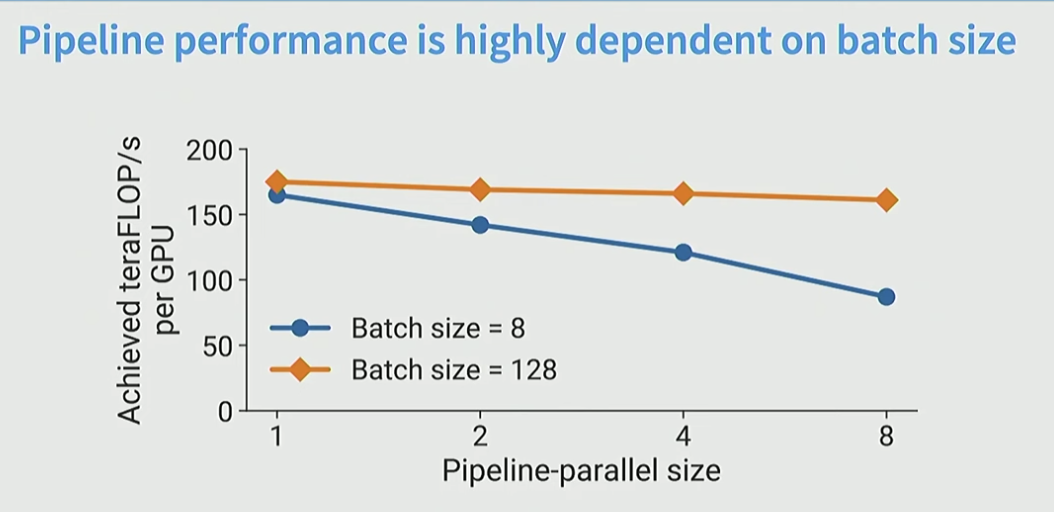
위 자료를 보면 batch size 128일 때가 더 이득을 많이 봄.
Pipeline Parallel을 쓰는 이유

- Pipeline은 DDP에 비해 메모리가 절약된다.
- DDP의 경우 모델 분산을 하지 않는다
- 뿐만 아니라, ZeRO-3를 생각한다 하더라도 Activation 메모리는 각각의 GPU에 저장하게 되는데 Pipeline은 각 gpu마다 자신의 layer에 해당하는 activation을 저장한다.
- Pipeline은 communication의 비용에서 이득을 본다. pipeline은 오직 activations 관련만 교환하는 반면 DDP나 ZeRO에서는 전체 파라미터를 교환
그리고 gpu간 통신만 하면 되는 반면 DDP는 all-reduce라 전체 gpu 통신
참고로 Activation 메모리는 O(B x S x H)이고 transformer의 경우 attention 때문에 더 필요하다. 각각 Batch size, Seqlen, hidden dim.
Pipeline Parallel이 통신 속도에서 이득을 보는 만큼 gpu 간 통신이 빠른 TPU에서는 Data Parallel을 쓰는게 더 이득
Zero bubble pipelining
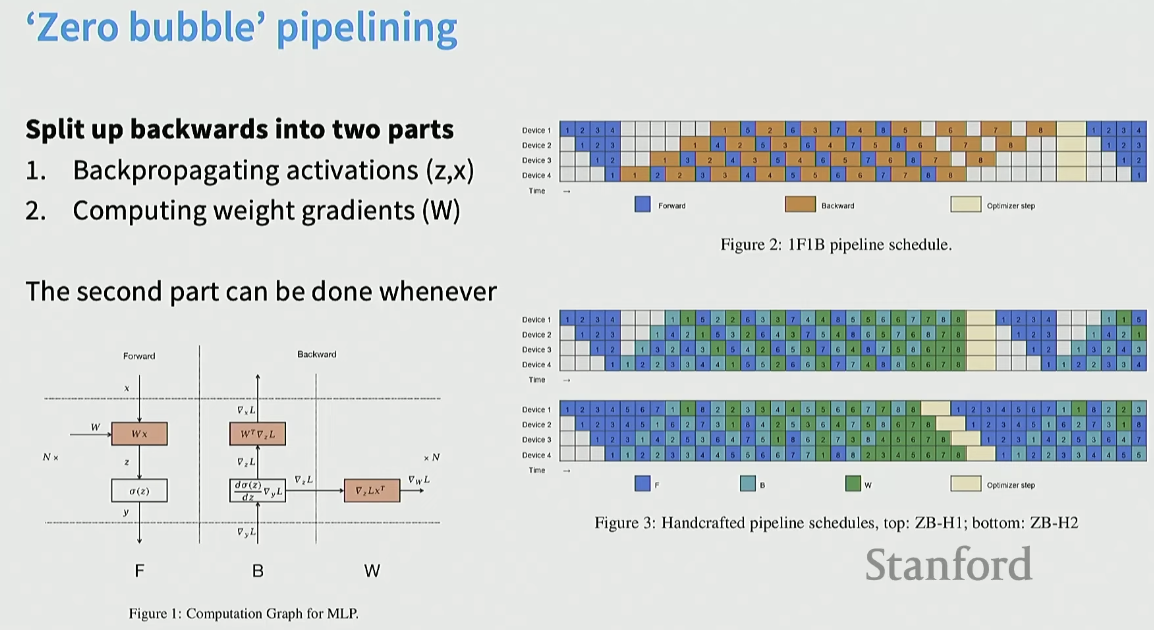
역전파 과정을 생각해보면 두 가지 스텝으로 나눌 수 있다.
- 내 이전 layer로 돌려줄 역전파 계산
- 현재 layer에 대한 weight gradients 계산
그런데 이때, Weight gardient는 당장 하지 않아도 되고, 미룰 수 있다! 즉, 독립적이다.
이를 이용한 아이디어가 오른쪽에 보이는 1F1B과 ZB-H으로 볼 수 있는데 1F1B는 Forward 사이에 Backward를 끼워 넣은 것을 ZB-H는 backpropation사이에 weight gradient 계산을 끼워넣은 것을 볼 수 있다.
그림을 보면 gpu가 노는 시간이 굉장히 많이 줄어든 것을 볼 수 있다.
그런데 교수님이 이건 구현하기 굉장히 복잡해서 팀에서 알고 있는 사람이 거의 없다고 하신다.
2-3-1. Tensor Parallel 관련

모델의 대부분의 연산은 matrix multiplication
Tensor parallel의 기본 컨셉은 이런 행렬곱을 Tensor(행렬)을 분해해서 연산하여 합치는 것
Pipeline parallel은 모델의 depth 측면에서 분할, Tensor Parallel은 모델의 width 측면에서 분할했다고 이해할 수 있다.
Tensor Parallel
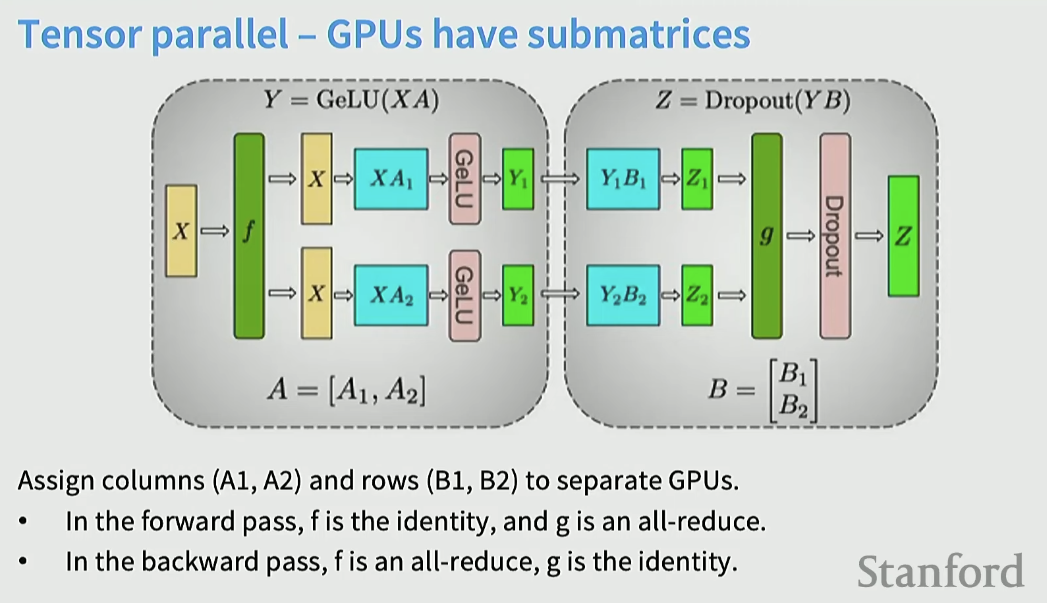
forward pass에서는 f 에서 identity로 동일한 행렬 X를 만들고, 나중에 g를 통해 all reduce를 한다. 마찬가지로 backward pass에서는 정확히 반대 연산을 한다.
row split을 하는 B가 결과를 내는 방식이 gpu0과 gpu1의 연산 결과를 합치는 것이므로, 역전파를 할 때는 먼저 all-reduce를 해서 activation을 모아야 한다.
Tensor Parallel을 써야할 때
같은 머신에 있는 gpu끼리만 사용한다.
왜냐하면 굉장히 빠른 gpu간 통신 속도가 있을 때 효율적인데, 그 이유는 통신이 layer 마다 발생하기 때문이다.
- 위에서 보았듯 각 gpu에서의 연산을 all-reduce할 때가 있듯 synchronization barrier가 생긴다.
- 또한, forward, backward시 항상 activation을 통신해야 한다.
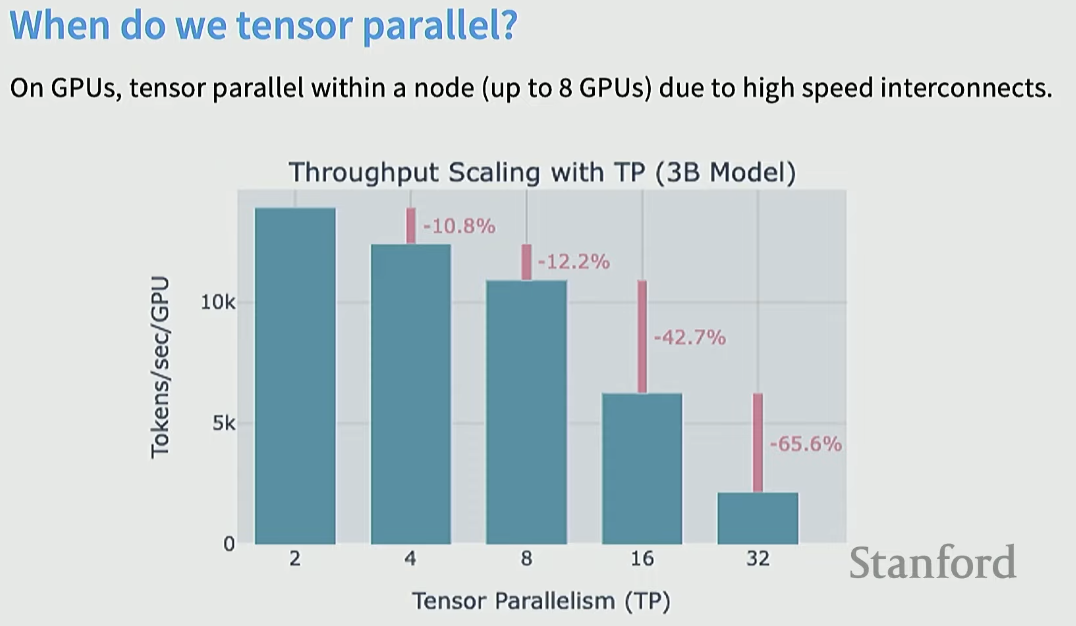
그리고 gpu간 통신이 많기 때문에 수에 따라서 하나의 gpu 효율이 급격하게 떨어진다.
Tensor parallel vs pipeline parallel
Tensor parallel이 pipeline parallel에 비해 좋은 점
- gpu의 bubble이 없음
- pipeline parallel에 비해서 훨씬 덜 복잡함. 단지 행렬곱이 어디서 일어나는지 보면 됨
- batch size 적어도 잘 돌아감 (pipeline parallel의 효율을 위해서는 batch size를 최대화 했어야 함)
좋지 않은 점
- 훨씬 더 큰 communication 비용
- tensor parallel은 항상 layer마다 all-reduce를 해야함.
tensor parallel은 low-latency, high-bandwith일 때만 사용
보통은 같이 사용!
3. Activation Memory + Sequence parallel
해당 파트는 Activation memory의 shard와 관련이 있다.
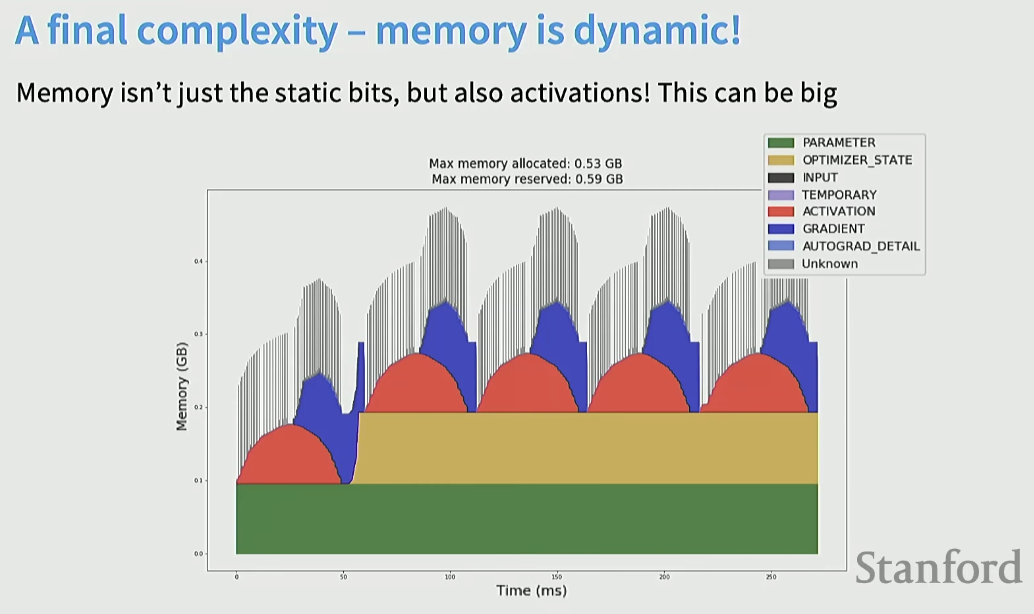
Activation을 보면 forward 과정에서 쌓이면서 오르고 backward 과정에서 내려옴
Activation memory per layer

activation memory를 layer 당 계산한 것인데, attention과 관련된 항이 오른쪽 항, MLP와 관련된 항이 왼쪽 항이다.

여기서 만약 Tensor parallel을 하게 되면 위에서 보았듯 행렬 연산을 나눌 수 있다. 따라서 각각 t (tensor parallel size)로 나뉘어 지는데 이때 10에 해당하는 건 나눠지지 않는다.
이걸 나누기 위해서 쓰는게 sequence parallel이다.
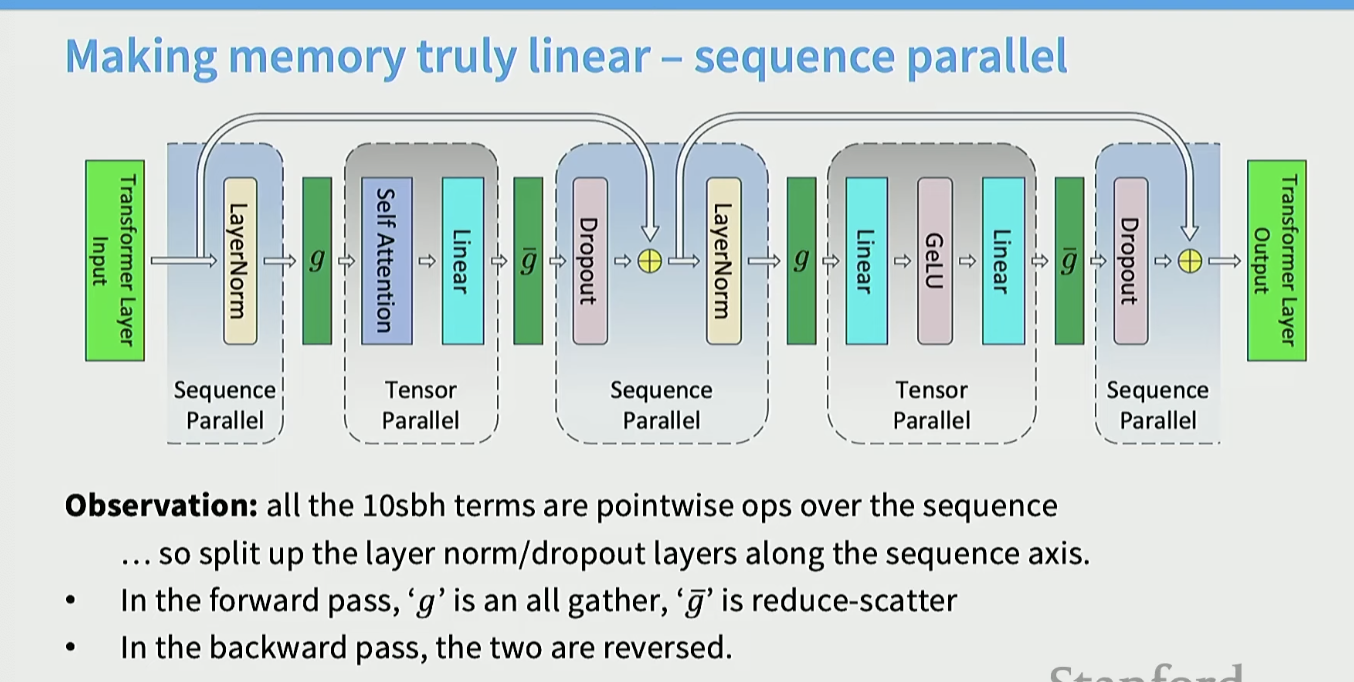
layer normalization과 dropout의 경우에는 sequence 별로 독립적으로 계산할 수 있다.
Tensor Parallel
얘는 input tensor나 output tensor의 hidden layer가 나뉘어진다.
GPU 1: H = 0~2048
GPU 2: H = 2048~4096
Seqence Parallel
얘는 token끼리 나누는 방식이라 hidden이 모두 보존된다.
GPU 1: tokens 0~1024
GPU 2: tokens 1025~2048
즉 tensor parallel과 sequence parallel은 서로 다른 축으로 분할하는 방식이라고 볼 수 있다.
Activation memory 최적화
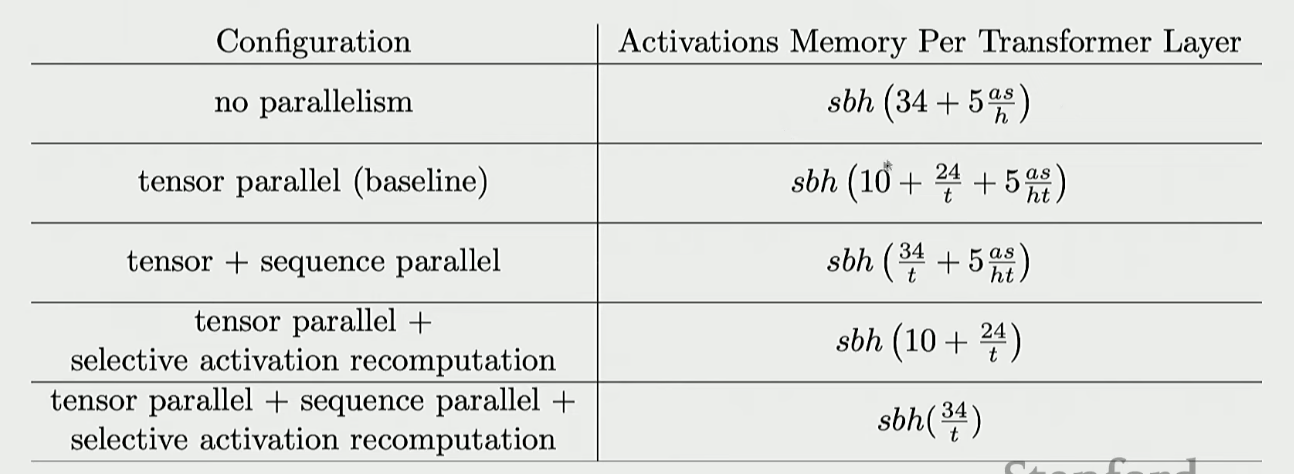
우리가 배운대로 tensor + sequence parallel 까지 하면 기존에서 tensor parallel 크기만큼 줄어드는 걸 확인할 수 있다.
나머지 밑에 두 개는 flash attention으로 할 수 있다고 한다.
다른 parallelism strategies
- contenxt parallel / Ring attention
- Expert parallel
