transformer의 Encoder 부분의 시간복잡도를 계산해보자.
transformer의 시간복잡도를 계산하기 위해서는 행렬의 시간복잡도를 계산할 수 있어야 한다.
A : n x d, B: d x n 행렬 두 개가 있다고 하자.
두 행렬의 곱 AB의 시간복잡도는 O(n^2 d)이다.
행렬의 곱은 A의 행벡터와 B의 열벡터를 곱하는 것이다.
- A의 행벡터는 n개 있고, B의 열벡터는 n개 있으므로, 최소 n^2의 곱이 일어나고, 각각의 곱마다 원소의 개수인 d만큼 합이 일어난다.
위에서 두 행렬의 시간복잡도를 계산하는 방법을 토대로 transformer의 시간복잡도를 계산해보자.
transformer의 구조를 보면 다음과 같이 단계를 나눠볼 수 있다.
- input을 Q, K, V로 나누기
- Q, K, V attention 연산
- Feed forward 통과
이 각각의 단계에서 시간복잡도를 계산해보자.
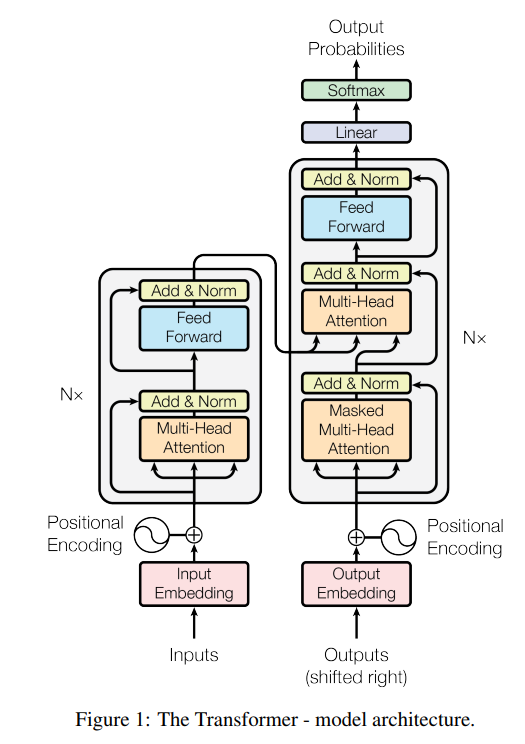
1. input을 Query, Key, Value로 나누기
input 행렬 : n x d
(n: input sequence. d: feature dimension)
head 수 : h
Wq, Wk, Wv : d x d/h
Query : input x Wq -> (n x d) ( d x d/h ) -> n x d/h = O(n x d^2 / h)
Key : input x Wk -> (n x d) ( d x d/h ) -> n x d/h = O(n x d^2 / h)
Value : input x Wv -> (n x d) ( d x d/h ) -> n x d/h = O(n x d^2 / h)
이때 Query Key Value는 모두 h개씩 존재하므로 1단계에서 걸리는 시간복잡도는 O(n x d^2)
2. Q, K, V attention 연산
(softmax는 제외하고 계산)
head를 고려한 경우도 똑같기 때문에 head가 없다고 생각하고 계산
Q : n x d
K : n x d
= (n x d) (d x n) -> n x n = O(n^2 x d)
= (n x n) (n x d) -> n x d = O(n^2 x d)
(물론, 여기서 를 거치긴 하지만 생략했다.)
2 단계에서 걸리는 시간복잡도는 O(n^2 x d)
3. Feed forward
논문에서 제시한 feed forward의 구조는 다음과 같다.
그리고 이때 W의 shape은 (d x 4d), (4d x d)이다.
즉, xW = (n x d) (d x 4d) -> (n x 4d) = O(n x d^2)
또한 W2 연산에서도 동일하게 O(n x d^2) 만큼 소요된다.
이때 relu 이므로 추가 연산은 없다.
즉, 3 단계에서 걸리는 시간복잡도는 O(n x d^2) 이다.
정리
이번 포스트에서는 Transformer의 시간복잡도를 계산해보았다. 총 시간복잡도는 O(n x d^2 + d^2 x n) 인데, 보통 sequence scaling 관점에서 O(n^2 x d)라고 표현한다.
