AutoML의 필요성
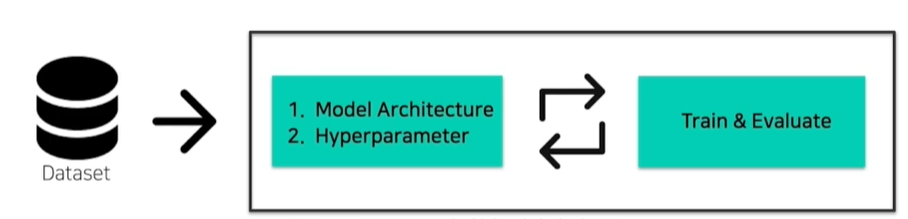
머신러닝 프로세스는 보통 어느 정도 데이터 전처리가 끝난 후 다음과 같이 model과 hyperparameter를 찾는 과정을 거치게 된다.
실험 전 자원과 데이터를 보고 가장 좋은 model 구조와 hyperparameter를 바로 알아낼 수 있다면 좋겠지만, 머신러닝 특성 상 올바른 논리를 가졌더라도 다른 모델 구조에서, 다른 hyperparameter에서 더 잘 작동하는 경우가 많다.
그래서 일반적으로 실험 전 사전 논리로 어느 정도 model 후보와 hyperparameter 후보를 선정한 후, 여러 번의 실험을 거쳐 해당 task에서 잘 작동하는 옵션을 선택한다.
실험 전 사전 논리로 후보 군(search space)을 만드는 것이 사람이 해야할 일이고, 그 이후 search space에서의 탐색은 컴퓨터가 할 일이라고 생각한다.
이런 역할을 해줄 수 있는 것이 바로 AutoML이다.
AutoML
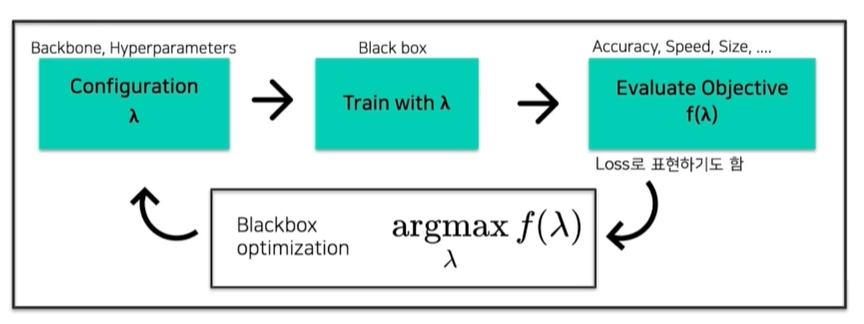
AutoML의 목적은 search space에서 현재 나의 목적함수 f를 최소화하는 조합 를 찾는 것이다.
AutoML을 잘 활용하기 위해서는 목적함수를 잘 정의해야 한다.
예를 들어, 서비스에 올라갈 모델을 만들기 위해서는 inference 속도가 중요하고 모델의 size 역시 중요한데, 이를 이용해서 목적함수 f를 정의할 수도 있을 것이다. 이 역시 AutoML의 흥미로운 점이다.
AutoML의 탐색 전략
Random Space에서 올바른 조합을 찾기 위해서는 세 가지 방법이 존재한다.
- Grid Search
- 정말 모든 조합 다 해보기
- Random Search
- 무작위로 조합 선택해서 해보기
- Bayesian Optimization
- 이전 정보를 기반으로 더 나은 탐색 공간 탐험하기
\
1. Grid Search
만약 자신의 뛰어난 직관 혹은 논리로 search space를 충분히 줄였고, 나에게 주어진 시간도 충분하다면 당연히 1번이 가장 좋은 선택일 것이다.
하지만 대부분의 경우 search space는 굉장히 크고 정해진 시간이 있다.
그리고 어떻게 보면 단순 반복문인데 AutoML이라고 할 수 있을까 싶다.
\
2. Random Search
그렇다면 두 번째 방법으로는 Random Search가 있는데, 이는 무작위로 조합을 선택하는 방법으로 과거의 정보를 활용하지 못한다.
만약 batch_size가 올라갈수록 성능이 떨어지는 경향이 있는데, 다음 search 후보로 batch_size가 더 큰 것을 선택하는 것을 보는 것은 아쉬울 것이다.
그렇다면 남은 세 번째 방법은 어떨까?
3. Bayesian Optimization
머신러닝에 관심이 있는 사람이라면 Bayesian이라는 용어에 익숙할 것이다.
베이지안의 가장 큰 매력은 과거 정보를 기반으로 확신의 정도를 업데이트 하는 것이다.
즉, Bayesian Optimization 탐험 방식은 과거 정보를 이용한다는 점에서 Random Search에서의 아쉬운 점을 해결해준다.
그렇다면 과연 해당 방식이 어떻게 과거 정보를 이용할까?
Bayesian Optimization (Gaussian Process Regression)
해당 글에서는 Gaussian Process Regression을 이용한 Bayesian Optimization에 대해서 다룬다.
Gaussian Process (공부중)
참고자료
1. AutoML Overview
2. https://www.youtube.com/watch?v=9vIPzpzfw-o
3. https://distill.pub/2019/visual-exploration-gaussian-processes/
