해당 글은 아래 논문에서 관심있는 부분을 정리한 내용입니다.
https://arxiv.org/pdf/2308.07107
v5는 2025년 9월에 나옴
4. Retriever
neural retriever의 성능을 좌우하는 건 data와 model이다.
retriever의 현재 어려움은 아래와 같다.
- 사용자 질의는 일반적으로 짧고 모호하기에 정확하게 사용자 의도를 이해하기 어렵다.
- 문서는 보통 길고 많은 noise를 포함하고 있어서 인코딩하고 관련 정보를 추출하는게 어렵다.
- 인간이 직접 관련성 라벨 부여하는 것에 대해 시간과 비용이 많이 소요된다.
- 더군다나 BERT 기반 구조에 의존하는 것이 성능을 제한하는 요인이 될 수 있다.
최근 LLM은 언어 이해, 텍스트 생성, 추론 능력에서 매우 뛰어난 능력을 보여주므로 이를 활용하여 retrieval 모델을 개발하려는 연구가 진행되고 있다.
해당 연구는 두 가지 범주로 나뉜다.
- LLM으로 검색 데이터를 생성하는 것 (4-1)
- LLM을 이용해 모델 아키텍처를 개선하는 것 (4-2)
4-1. Leveraging LLMs to Generate Search Data
두 가지 주요 관점이 있다.
- 검색 데이터 정제
- 사용자 의도를 더 정확히 표현하도록 입력 질의 재구성
- 학습 데이터 증강
- LLM의 생성 능력 활용 dense retrieval 모델의 학습 데이터 확장
4-1-1. Search Data Refinement
질의는 일반적으로 짧은 문장 또는 키워드 형태 + 모호하거나 여러 가지 사용자 의도를 가지고 있다. 또한, 문서는 불필요한 정보나 noise를 많이 가지고 있다.
4-1-2. Training Data Augmentation
인간이 직접 라벨링 하는 건 한계가 있어서 학습 데이터 부족 문제 발생
LLM을 활용하여 pseudo relevance signal을 생성하는 방법으로 이를 해결한다.
데이터 증강이 필요한 이유
주로 retrieval 모델은 지도 학습을 통해 특정 도메인 데이터를 학습한다. (Ex - MARCO)
하지만 이런 방식은 특정 도메인에 지나치게 의존하게 되어 다른 도메인에서의 성능이 제한된다.
retrieval 모델은 다양한 분야에 적용될 수 있기 때문에, 일반화된 검색 모델을 만들기 위해서는 데이터를 만들어야 한다.
LLM을 데이터 증강에 활용하는 방법
많은 문서를 수집하는 것은 쉽지만 실제 어려운 것은 사용자 질의와 관련 문서 라벨을 수집하는 것이다.
LLM을 활용하면 기존 문서 corpus를 기반으로 pseudo query 또는 relevance label을 생성할 수 있다.
이를 통해 query-document pair를 자동으로 생성할 수 있다.
이러한 방식은 데이터 유형에 따라 세 가지 방법으로 나눌 수 있다.
- Pseudo query generation
- Relevance label generation
- Complete example generation
Pseudo query generation
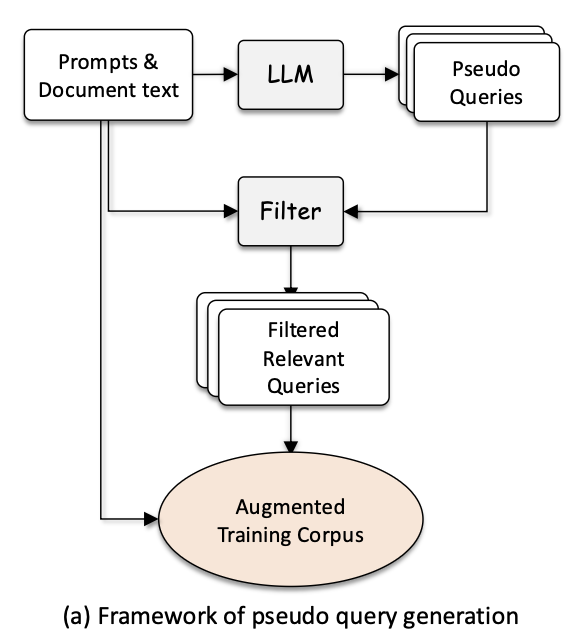
이미 corpus에 많은 문서가 존재할 것이므로 문서에 대응하는 pseudo query를 생성하는 것이다.
InPars 방식이 대표적이라고 한다. (GPT-3에 few-shot 활용)
LLM을 이용한 query 생성은 비용이 많이 소모되는 만큼, 생성 비용 대비 데이터 품질이 중요하다.
이를 해결하기 위해 UDAPDR는 LLM으로 소량의 query를 생성한 뒤 이를 이용해 작은 모델이 대량의 query를 생성하도록 하는 방식을 제안했다.
Pseudo label generation
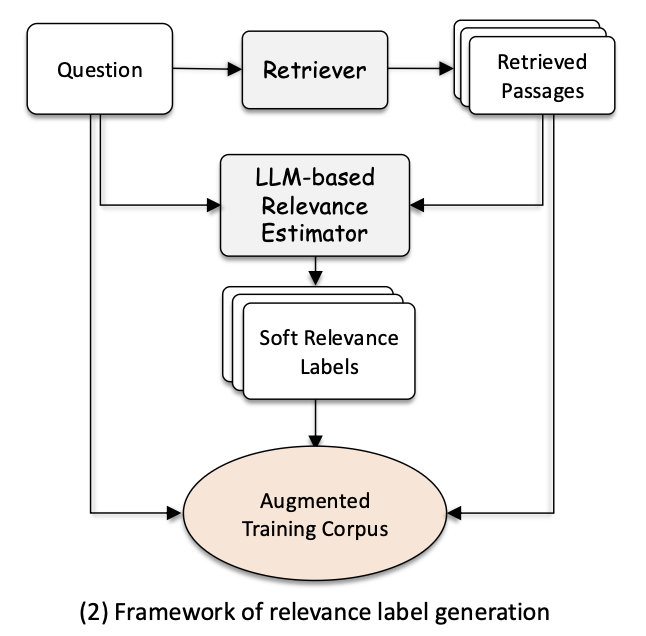
question answering 같은 작업의 경우 질문 자체는 충분히 수집되어 있지만, 질문들에 대한 document의 relevance 라벨은 제한적이다.
해당 방벙은 LLM을 활용하여 relevance label을 생성하는 것이다.
- 각 질문에 대해 관련성이 높은 top passges 검색
- LLM을 활용해 해당 passage로부터 해당 질문이 만들어질 확률 계산
- normalization 후 soft relevance label로 사용하여 retriever 학습
Complete example generation
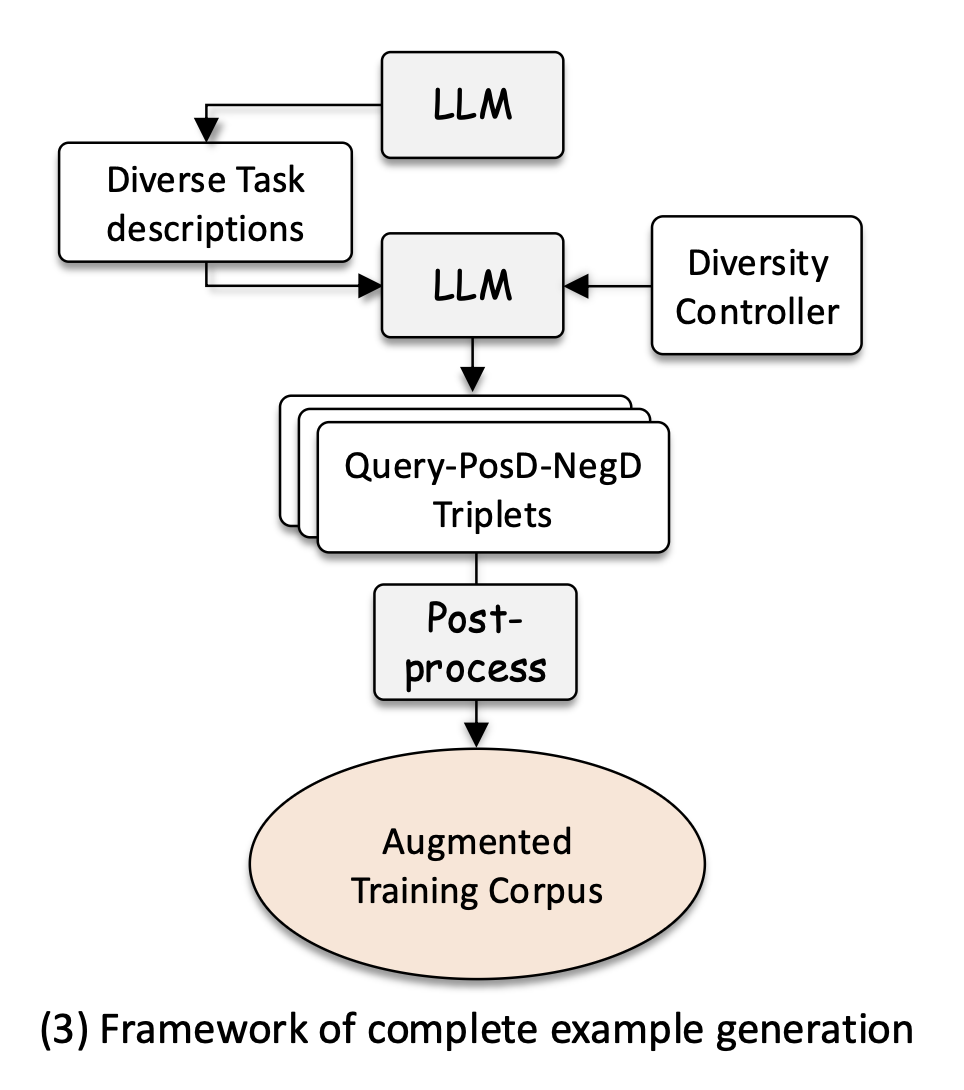
LLM을 활용해서 (query, positive document, negative document) 형태의 생성 데이터를 만드는 방식
첫 번째 단계에서는 LLM에게 여러 가지 retrieval task에 대해 생성 (ex, 의학, 정치, 시사 ...)
두 번째 단계에서는 query와 document 길이, 사용되는 언어, 그리고 query와 document 사이의 의미적 관계 조절
아마 이러한 방식은 기존에 document를 보고 query를 생성하는 방식보다 더 다양한 데이터를 생성할 수 있다는 점이 좋을 것 같다.
4-2. Leveraging LLMs as Retriever Backbone
LLM을 retriever의 backbone으로 활용하는 방식이고, 기존 작은 규모 모델 기반 방법들보다 상당한 성능 향상을 가져온 방법
4-2-1. Dense Retriever
LLM을 적용하면 두 가지 주요한 영향이 나타나는데,
기존 방법들의 발전을 가속화하여 in-domain 정확도와 out-of-domain 일반화 성능에서 향상한 것
그리고 instruction following이나 in-context learning과 같은 새로운 능력을 얻은 것
이다.
기존 능력 향상
decoder-only 모델을 embedding 모델로 적용한 최초의 연구는 OpenAI가 진행했다.
해당 연구에서는 모델 규모와 임베딩 차원이 증가할수록 retrieval 성능이 지속적으로 향상됨을 보였다.
또한, LLM 기반 retriever는 특정 도메인에서 fine-tuning된 모델이라 하더라도, 해당 도메인을 넘어 일반적인 작업에서도 성능 향상이 관찰된다.
즉, LLM을 backbone으로 활용할 경우 뛰어난 일반화 성능을 보인다.
최초의 오픈소스 llm based embedding 모델 - RepLLaMA
RepLLaMA는 오픈소스 기반(LLaMA 7B)으로 학습된 최초의 embedidng 모델인데, 이 모델은 MSMARCO retrieval과 BEIR benchmark 에서 큰 성능 향상
단점으로는 모델 스케일에 따른 추가적인 비용 발생하지만 RepLLaMA 단독 retrieval이 multi-stage retrieval 정확도 능가
LLM을 직접 fine-tuning 하는 방법 외에도 여러 방법이 있다.
- post pre-training
Llama2Vec(LLaMA-2) 모델에서는 아래 두 가지 task를 사용했다.
- EBAE (Embedding Based Auto-Encoding)
- EBAR (Embedding Based Auto-Regression)
이것 또한, LLaMA-2 모델에 비해 성능이 크게 향상
- bidirectional attention + latent attention layer 도입
NV-Embed는 LLM 아키텍쳐를 위 방식으로 수정해서 MTEB 성능 향상에 기여했다.
이런 성능 향상이 있었지만, 아직 effciency와 adaptability에서 해결할 부분이 있다.
generalization vs adaptability
- generatlization의 경우 train과 다른 데이터셋으로 테스트 한 경우
- adaptability는 아예 다른 task로 테스트 하는 경우 (web retrieval vs code retrieval)
새로운 능력
LLM 기반 임베딩 모델은 instruction following이 생겨서 사용자의 요구에 따른 임베딩이 가능하다.
ChatRetriever가 그 예시고, LLM 기반 대화형 임베딩 모델로 작동한다.
또한, in-context learning과 context 길이에 따른 능력이 향상되었다.
instruction following을 활용해서 검색을 하게 되면, task를 바꿔서 검색을 할 수 있다.
task 1 : question → information document
입력 : Represent this query for retrieving relevant documents: how to lose weight
출력: How to lose weight fast
task 2 : duplicate question retrieval
입력 : Represent this question for retrieving semantically similar questions: how to lose weight
출력 : how can I lose weight
4-2-2. Generative Retriever
5. Reranker
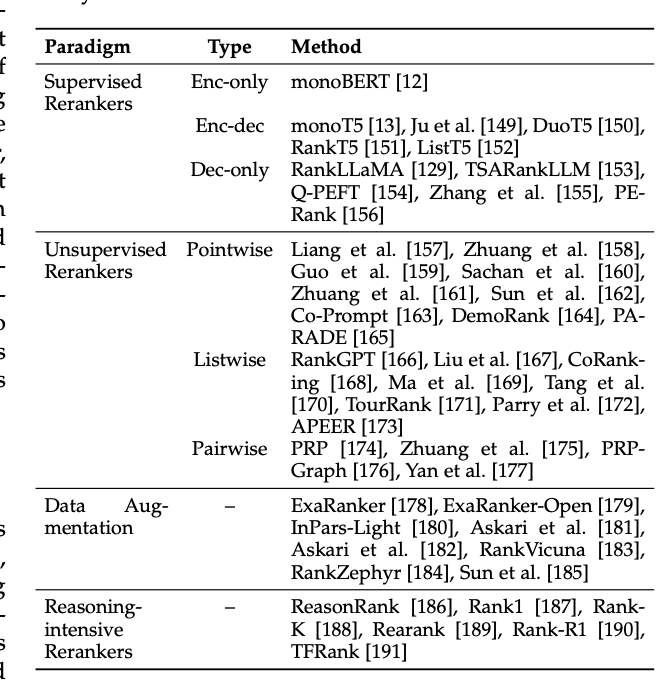
LLM을 사용하는 방식에 따라, 기존의 LLM 기반 reranking 방법들은 네 가지 방식으로 나뉜다.
각각 5-n
- supervised
- unsupervised
- 학습 데이터 증강
- 추론이 필요한 reasoning-intensive reranker
5-1. Utilizing LLMs as Supervised Rerankers
LLM을 지도학습을 통해 fine-tuning 하여 Reranker로 활용하는 방식
백본에 따라 encoder-only, encoder-decoder, decoder-only로 나눔
5-1-1. Encoder-only
- input 을 이와 같이 구성. [CLS] query [SEP] document [SEP]
- CLS representation에 linear layer 넣어 relevance score 계산
- cross entropy loss로 최적화
5-1-2. Encoder-Decoder
output은 true나 false와 같은 단일 토큰을 생성하도록 fine-tuning 하는 방법
추론 시에는 true와 false의 logit에 softmax 적용 후 true 토큰 확률로 관련성 점수 사용
5-1-3. Decoder-only
RankLLaMA : LLaMA를 fine-tuning 한 리랭킹 모델
- query: {query} document: {document} [EOS]
- 마지막 토큰의 표현(last token representation)을 관련성 계산에 사용
5-2. Utilizing LLMs as Unsupervised Rerankers
LLM을 fine-tuning 하는 것에는 한계가 있다보니, prompt를 사용해 성능을 향상시키는 방법이다.
5-2-1. Pointwise methods
5-3. Utilizing LLMs for Training Data Augmentation
5-4. Reasoning-intensive Rerankers
5-5. Limitations
3. Query Rewriter
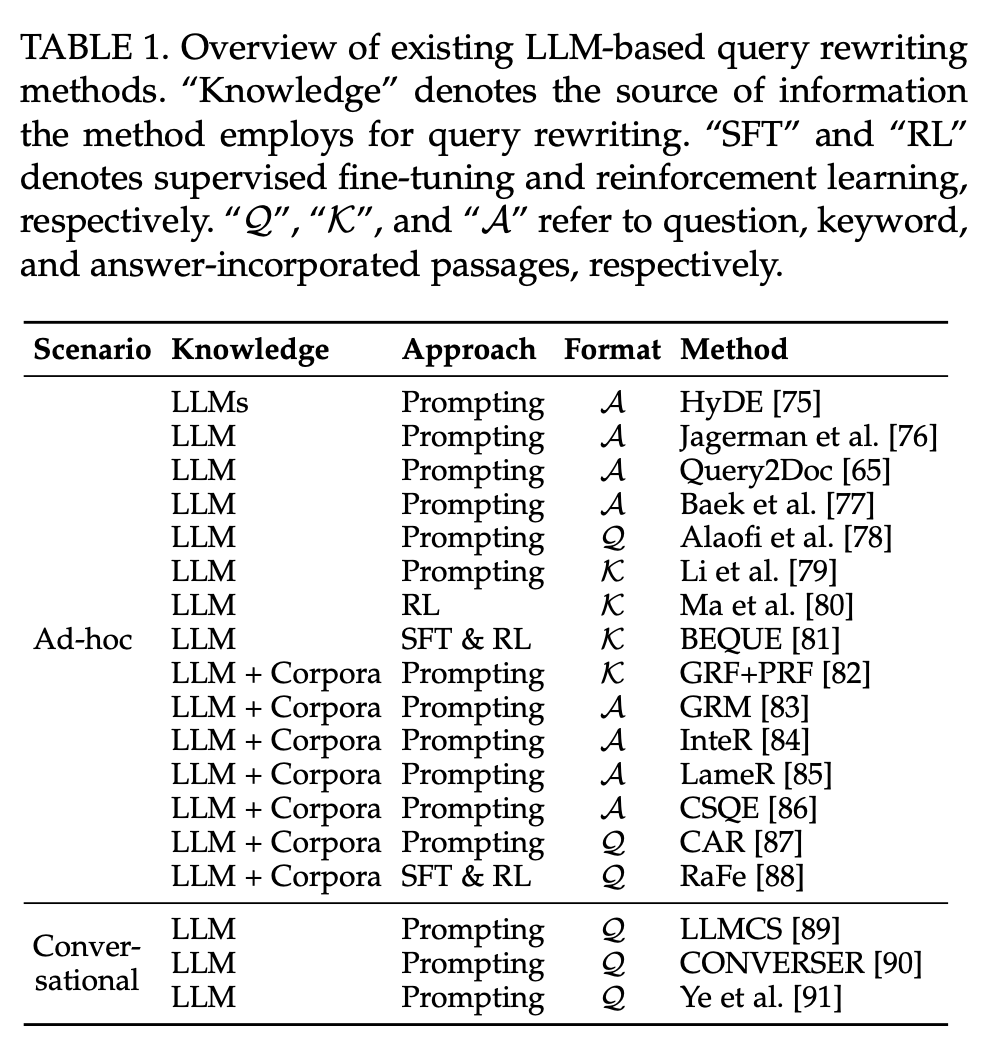
검색은 크게 ad-hoc retrieval과 conversational search로 나눌 수 있다.
ad-hoc retrieval은 우리가 google에서 하는 일반적인 검색을 말한다.
ad-hoc retrieval에서의 query rewriting
query rewriter 목표 = query와 document의 semantic gap 줄이기
기본적으로 query의 경우는 키워드 형식으로 짧고 모호하다. 반면, document는 길고 자세하다.
query의 예를 들면, apple이라는 쿼리가 들어오면 말하는지, 회사를 말하는지 알기 어렵다.
이러한 특성으로 인해 query와 document간 representation mismatch가 발생하기 쉽고, 이게 semantic gap을 만든다.
이를 해결하기 위해 query rewriting은 query를 document 표현에 맞게 재구성해야 한다.
전통적인 Query Rewriting
- lexical knowledge bases
- pseudo-relevance feedback (PRF)
knowledge base 방법으로는 동의어 사전이 있다.
car -> automobile, vehicle
PRF 방법은 현재 쿼리 검색 결과를 이용해서 업데이트 하는 방식이다.
이렇게 나온 결과를 그냥 query 옆에 붙인다.
Query: car insurance -> car insurance auto vehicle coverage policy
그런데 knowledge base 방법은 지식이 제한되어 있고, PRF 방식은 초기 retrieval에 의존하는 문제가 있다.
반면 LLM은 언어 능력을 바탕으로 query를 재구성하기 쉽다.
conversantional search에서의 query rewriter
query rewriter의 목표 = 대화 맥락과 과거 대화를 반영해 query를 정제하는 것
이때 coreference resolution이 중요
coreference resolution이란?
현재 발화 속 지시 대상이 무엇을 가리키는지 풀어내는 것
ex) 1턴: “갤럭시 S25이랑 아이폰 16 비교해줘”
2턴: “카메라는?”
3턴: “그럼 이건?”
전통적인 대화형 검색에서의 query rewriting이 잘 안되는 이유
-> 대화형 검색 자체가 너무 다양하고, long-tailed 패턴이 많기 때문
그래서 LLM 활용하기 시작
3-2. Formats of Rewritten Queries
Query rewriting의 결과물로 나오는 Rewritten 된 Query 형식은 총 세 가지로 구분할 수 있다.
Questions, Keywords, Answer-incorporated Passages
Questions
기존과 비슷한 형태인 질문 형태로 바꾸는 것이다.
여기엔 rephrasing, expanding, simplifying 등이 있다.
아마도 내가 수행했던 검색어 교정도 여기에 포함될 것 같다.
Keywords
더 높은 차원을 추상화해서 검색어를 만드는 것이다.
이건 retriever가 sparse retriever일 경우 효과적으로 쓰일 수 있겠다.
Answer-incorporated Passages
Query Rewriting의 목적은 semantic gap을 줄이는 것이고 이는 query와 document 간의 표현 방식에서 기인한다고 했다.
이 문제를 직접적으로 해결하려고 하는 방식으로, Query에 대한 Answer을 만들어서 하나의 Query로 다시 재구성하는 것이다.
왜냐하면 Answer의 표현 방식은 document에 가깝기 때문에 semantic gap이 줄어들 수 있다.
3-3. Approaches
LLM을 활용한 Query rewriting은 세 가지 방식으로 나눌 수 있다.
Prompting, SFT, RL
Prompting 같은 경우는 flexibility와 interpretability가 있다.
- 프롬프트만 바꾸면 언제든 유연하게 대응할 수 있으므로 flexibility가 있다.
- 프롬프트를 통해 명시적으로 지시하므로 결과에 대한 해석 여지가 있다.
SFT는 prompt 생성에 맞게 모델을 학습하는 것인데, 학습 데이터를 확보하는게 문제다.
학습 데이터는 이런 형태인데 아직 고품질의 데이터는 없는 것 같다.
(대화 맥락, standalone query), (원래 query, 바람직한 rewrite)
그래서 RL을 통해 이 문제를 해결하려고 한다.
Prompting
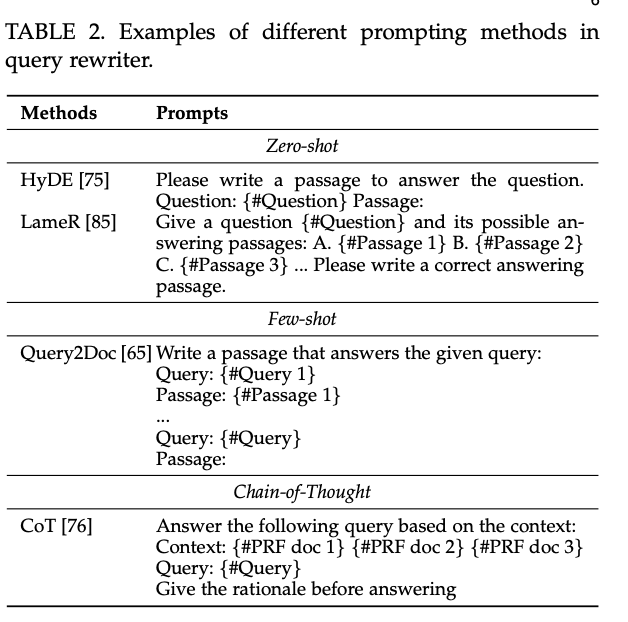
실험 결과 Query2Doc이 기타 다른 방식들보다 효과적이라고 한다.
Query2Doc
- MSMARCO나 NQ에서 가져온 몇 개의 query-document pair를 보여준 뒤, LLM에게 질의 query에 답하는 문서 생성
- 해당 문서를 query에 포함시켜서 검색
- Query = original query + pseudo document
SFT
SFT에서 가장 중요한 건 학습 데이터인 (query, rewrite query)를 얻는 것이다.
이를 위해 사용자 feedback 데이터를 활용한다.
E-commerce 같은 경우는 구매라는 명확한 목적이 있어서 데이터를 만들기 쉬운 반면, 반면 ad-hoc에서는 클릭, 체류시간 같은 implicit feedback에 noise가 있어서 데이터를 만들기 쉽지 않다.
RL
Query rewriter는 검색 시스템의 중간 단계라서 이 모듈을 최적화할 독립적인 loss function이 없어서 rewrite가 잘 됐는지 판단하기 어렵다.
강화학습은 이런 상황에서 학습 시킬 때 downstream 구성 요소로부터의 피드백을 활용한다.
rewrite → retrieval → ranking 이 흐름이므로 ranking score가 높아지면 rewrite의 quality가 올라가는 것
이런 관점에서 RL은 query rewriter의 목표를 downstream task의 목표와 일치시키는 방법이다.
3-4. Limitations
- Concept Drift
LLM을 활용하다보니 LLM이 관련 없는 정보를 추가해 Query의 방향을 바꾸는 것
따라서 original query를 보존한 채로 의미를 확장시키는게 핵심
- Expansion과 검색 성능의 상관관계
최근 연구들에 따르면 검색 성능과 expansion benefits의 상당한 음의 상관관계를 가짐
구체적으로 expansion이 성능이 좋은 모델에서는 오히려 악영향
따라서 전략적으로 성능이 약한 모델에서만 expansion 활용하거나 query와 document 간 간극이 큰 곳에서 활용
7. Search Agent
LRM (Larage Reasoning Model)의 등장으로 LRM 기반 지능형 에이전트를 개발하려는 관심이 증가하고 있다.
이러한 패러다임 전환은 인간과 유사한 추론 및 정보 검색 과정을 재현하는 것을 목표로 한다.
해당 분야의 초기 연구는 static pipeline-based architectures에 초점을 두었지만, 실제 환경에서 발생하는 동적이고 복잡한 상호작용에 적응하는 능력이 제한적이었다.
최근에는 LRM의 발전을 통해 자율 검색 에이전트 개발이 가능해졌다.
7-1. Architecture of Search Agent
접근 방식은 크게 두 가지 패러다임으로 분류할 수 있다.
- 단일 에이전트 프레임워크
- 하나의 LLM이 작업의 모든 측면(추론, 상호작용, 답변 생성)을 처리하는 방식
- 멀티 에이전트 프레임워크
- 역할을 여러 LLM에 분산하여 협업해서 목표 달성하는 것
7-1-1. Single-Agent Frameworks
ReAct 스타일 매커니즘으로 동작하는 Search-R1, ReSearch가 하나의 예시다.
LLM 정책(policy)들이 다음과 같은 행동(think, search, answer)을 자동으로 선택한다.
이를 통해 반복적으로 상호작용하며 복잡한 multi-hop 질문을 해결할 수 있다.
이러한 에이전트 시스템의 성능을 최적화하기 위해 주로 RL (GRPO)를 자주 사용한다.
