검색 시스템
1.DPR
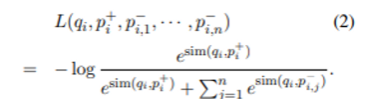
기존 검색 방법인 Sparse embedding을 사용한 검색 방법인 TF- IDF 또는 BM25 처럼 Lexical한 방법이 아닌 Dense embedding을 사용한 Semantic한 방법 성능이 좋다.Dense embedding은 적은 수의 question and
2.BM25
BM는 검색을 위한 ranking function이다. 이는 TF-IDF 와 마찬가지로 lexical한 의미를 기반으로 점수를 매기는 방법이다.가장 대표적인 식은 다음과 같이 계산된다.$$score(D,Q) = \\sum^n\_{i=1}IDF(q_i)\\cdot \\f
3.Learning Dense Representations of Phrases at Scale

아래 링크는 위 논문을 리뷰하며 공부하고 있는 내용입니다.https://acoustic-basin-638.notion.site/Learning-Dense-Representations-of-Phrases-at-Scale-e73e5b2ff6404f45ac270ad
4.Phrase Retrieval Learns Passage Retrieval, Too
아래 링크는 현재 공부하고 있는 논문 공부 링크입니다.https://acoustic-basin-638.notion.site/Densephrases-Too-740193fc663e450f90688988e46ee8ed?pvs=4
5.Constrative Learning의 한계
\*\*Densephrases에서의 Constrative Learning\*\*Constrative Learning은 대조 학습으로 데이터의 벡터 공간에서 positive data는 가깝게, negative data는 멀리 위치시키는 것입니다.Densephrases의
6.[논문 리뷰] Dense Text Retrieval based on Pretrained Language Models: A Survey - 작성중
요약해당 introduction에서는 검색 초기 ~ BERT (PLM) 를 활용한 단계까지의 간단한 소개에 대한 내용이다.Text retrieval의 목적은 Query와 relevant한 Document를 찾아주는 것text를 어떻게 표현할까?bag-of-words중요
7.[논문 리뷰] Large Language Models for Information Retrieval: A Survey
해당 글은 아래 논문에서 관심있는 부분을 정리한 내용입니다. https://arxiv.org/pdf/2308.07107 v5는 2025년 9월에 나옴 4. Retriever neural retriever의 성능을 좌우하는 건 data와 model이다. retriever의 현재 어려움은 아래와 같다. 사용자 질의는 일반적으로 짧고 모호하기에 정확하게 ...