해당 글은 wikidocs의 '딥 러닝을 이용한 자연어 처리'를 학습하고 내용을 재구성하여 다음과 같은 순서로 작성되었습니다.
순서
- 문장에서 불필요한 부분들 제거
- 모델이 학습할 수 있게 text를 숫자로 표현하는 방법
- 숫자로 표현된 단어들을 input으로 가지고 목적에 맞는 output을 내는 다양한 모델들
단어의 다양한 표현 방법 (피처 벡터화 - 수치화)
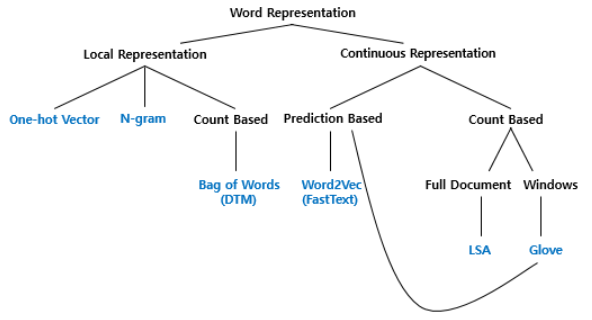
국소 표현 (Local Representation) 또는 (Discrete Representation)
- 해당 단어 자체만 보고 매핑
- One-hot Vector, bag of words(BoW) 등이 있음.
1. One-hot Vector
One-Hot Encoding
원소가 1과 0인 벡터로 바꾸어 표현하는 방법.
단어 집합(vocabulary) : 텍스트의 모든 단어를 중복을 허용하지 않고 모아 놓은 것
케라스를 이용한 원-핫 인코딩 (to_categorical)
- 정수 인코딩 ( vocabulary에 있는 단어들을 숫자로 변환)
- 벡터로 만듦
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text = '나랑 점심 먹으러 가자 점심 메뉴는 피자 ㅇㅋ?'
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text)
tokenizer.word_index
sub_text = "점심 먹으러 갈래 메뉴는 햄버거 최고야"
encoded = tokenizer.texts_to_sequences([sub_text])[0]
print(encoded)
#원 핫 인코딩 수행
one_hot = to_categorical(encoded)
print(one_hot)이 방법의 한계는 벡터를 저장하기 위한 공간이 너무 크다는 점.
그리고 유사도를 표현하지 못한다는 점.
그리고 빈도를 포함하지 못한다는 점 등이 있다.
2. Bag of Words (BoW)
Bag of Words(BoW)
문맥이나 순서를 무시하고 빈도값을 부여하는 방식.
-
장점 : 쉽고 빠른 구축, 예상보다 문서의 특징을 잘 나타냄
-
단점 : 문맥 의미 반영은 힘듦, 희소 행렬 문제
-
희소 행렬 문제 : 문서별로 단어 수를 집계할 때 문서가 많으면 단어의 수가 너무 많아서 한 문서에서 쓰이는 단어가 얼마 없어 대부분 0값이 됨. 이렇게 되면 많은 양의 저장 공간과 높은 계산 복잡도가 요구됨.
대부분의 값이 0인 행렬을 희소 행렬이라 함.
이런 희소 행렬 해결하기 위한 방법은 2가지가 있음
- COO (Coordinate)
- CSR (Compressed)
-
서로 다른 문서들의 BoW들을 결합한 것을 DTM(Document-Term Matrix) 문서 단어 행렬이라고 함. 행렬의 행과 열을 바꾼 것을 TDM이라고 함.
BOW 피처 벡터화 유형
1. 단순 카운트 기반의 벡터화 (CountVectorizer)
- 오직 띄어쓰기만들 기준으로 단어를 자르는 수준. 한국어의 경우 띄어쓰기가 없이도 의미 전달이 되므로 제대로 만들어지지 않음. 할거면 띄어쓰기 하고 해야함.
- 순서만 카운트 하여 빈도 수를 기반으로 판단할 경우, 기본 단어가 굉장히 중요한 단어가 될 가능성이 있음. 예를 들어 증권 문서의 경우 시가, 종가 등의 단어는 항상 등장함.
2.TF-IDF (Term Frequency Inverse Document Frequency) 벡터화
-
서로 다른 BoW들을 결합한 것을 DTM(Document-Term Matrix) 문서 단어 행렬이라고 함. 행렬의 행과 열을 바꾼 것을 TDM이라고 함.
-
이게 DTM에서의 기본 단어가 중요한 단어가 되는 문제 해결.
-
많은 문서에서 빈번하게 나타나는 단어가 있으면 중요하지 않게 구별함.
tf(d,t) - 문서 d에서 특정 단어 t의 등장 횟수
df(t) - 단어 t가 등장한 문서의 수
idf(d,t) - df(t)와 반비례함. log를 취하는 이유는 df(t)가 작고 n이 커질 때 값이 너무 커지는 현상 방지.
IDF - N/DF (N : 전체문서)
TF-IDF(중요도) = TF*log(N/DF) (이때 로그는 자연 로그를 써도 됨)
-
4개의 문서에서 단어가 4번 나왔을 경우 log(4/4) =0 → 중요도 0
4개의 문서에서 단어가 1번만 나왔을 경우 log(4/1)> log(4/2) → 2번 나온 단어보다 중요도 높음.
-
분산 표현 (Distributed Representation) 또는 (Continuous Representation)
- 주변 단어를 참고하여 단어를 매핑 (단어의 뉘앙스 표현 가능)
- Word2vec, LSA, Glove 등이 있음.
Word Embedding (수치화 된 단어를 밀집 벡터로 표현)
밀집 표현 (Dense Representation)
: 차원이 10000인 [0,1,0,0,00,0,0,0,0,0,0 ... ,0] 벡터를 차원이 3짜리인 벡터로 바꾸어 다음과 같은 표현이 가능함. [0.2,0.4,-0.5].
이를 밀집 표현이라고 함.
희소 표현 (one hot) 고차원 → 분산 표현 (embedding) 저차원
단어의 의미를 여러 차원에다가 분산하여 표현. 이때 비슷한 문맥에서 학습한 단어는 비슷하게 분포함.
예를 들어, 춘식이는 귀엽다. 예쁘다. 사랑스럽다. 라는 세 문장이 있으면 귀엽다와 예쁘다, 사랑스럽다는 비슷한 벡터에 분산시킴.
1.Word2Vec
이 학습 방법의 방식에는 2가지가 있다.
1. CBOW (Continuous Bag of Words)
주변에 있는 단어(context word)들을 입력으로 중간에 있는 단어(center word) 예측
ex) The cat ??? on the table /답 sat
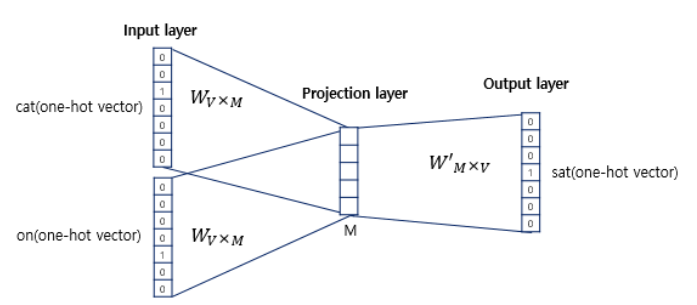
이 그림은 CBOW의 학습 인공신경망인데, 주변 단어가 input이 되고 중간 단어가 output이 됨. 이 그림 같은 경우는 window =1 이다.
(이때 윈도우 크기를 설정하여 주변 단어를 몇개를 볼 것인가를 정할 수 있음.)
Projection layer로 투사하는 것 까지가 임베딩임.
이때 투사 값은 2개의 input_layer의 결과값의 평균임.
사실 이 알고리즘은 은닉층이 1개라 딥러닝이 아님.
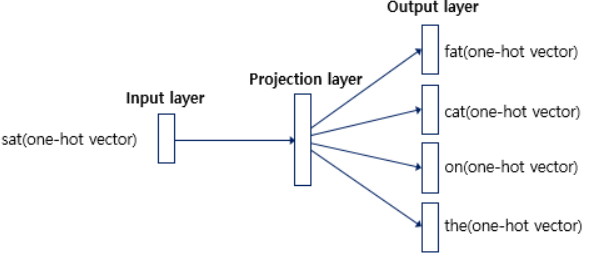
2.Skip-Gram
중간에 있는 단어들을 입력으로 주변 단어들을 예측.
2. GloVe (Global Vectors for Word Representation)
LSA는 통계 기반이라 한번도 나오지 못한 예측을 하기 어렵고, Word2Vec은 윈도우 크기 단어들만 고려해서 전체적인 통계 정보를 반영하고 학습한게 아님.
3. FastText
Word2Vec가 단어를 최소 단위로 봤다면 FastText는 subword를 학습함.
n을 설정하여 subword의 글자수를 정함.
예를 들어 apple의 경우 n이 3일 때, <ap, app, ppl, ple, le> 로 쪼갤 수 있음 이때 <,>는 모든 단어의 양 끝을 표현한 것.
이 sub단어와 원래 단어에 <>를 붙인< apple> 까지 6개의 단어 조각으로 학습하고 임베딩하여 벡터들의 총 합이 단어 apple의 임베딩 값이 됨.
이 알고리즘의 의의
모르는 단어에 대한 대응이 가능 → birth, day를 알면 birthday 유추 가능
단어 집합 내 빈도 수가 적었던 단어에 대한 대응 → birthday를 알면 birth를 학습한 것 birthmonth(?)를 학습할 때 birth를 학습한 것으로 볼 수 있어서 상대적으로 적은 birth에 대해 대응이 가능하다.
오타에 강함. → apple과 appla의 차이는 subword가 비슷해서 크게 안남.
영어 뿐만 아니라 한국어에도 적용을 해볼 수 있는데, 이땐
음절 단위(모르는 단어에 대한 대응 기대 가능) 또는 자모 단위(오타에 대한 대응 기대 가능) 로 시도가 가능하다.
둘 다 사실 FastText에 대한 장점 3가지를 기대해볼 수 있다.
4. 엘모(ELMo, Embeddings from Language Model)
2018년에 제안된 방법론.
사전 훈련된 언어 모델을 사용함.
문맥을 반영한 워드 임베딩
아까까지 생각했던 문제, 같은 단언데 어디에 붙느냐에 따라서 의미가 완전히 달라지는 경우 ex)Bank Account, River Bank(강둑)에 대한 대응은 기존 알고리즘은 입력을 단어 그 자체로 하기 때문에 두 경우에서 차이가 없음.
어떤 사전 훈련된 모델? → biLM
biLM (Bidirectional Language Model)
벡터의 유사도(Vector Similarity) - 단어 유사도
-
유클리드 거리
-
Cosine Similarity - 두 피처 벡터 간 cos(angle)값. 내적으로 구함.
이 방법은 방향이 동일(즉 문서의 단어 빈도가 배수 차이남)일 경우, 사실상 같은 내용을 두 번 반복한다거나, 동일한 문서로 취급할 수 있음. 그러나 유클리드 거리를 이용하여 유사도를 계산하게 되면 상당히 거리가 있는 문서가 됨.
-
Jaccard Similarity
근데 주로 Cosine Similarity를 이용함.
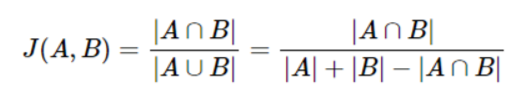
임베딩 벡터의 시각화
구글의 임베딩 프로젝터라는 시각화 도구를 이용하여 할 수 있다.
