어느 기업 구인공고를 보다가 UTF-8이 무엇이냐라는 질문이 있었다.
막상 면접에서 이걸 물어봤다면 내가 답할 수 있었을까.
UNICODE
UTF-8을 알기 위해서는 먼저 유니코드를 알아야한다.
유니코드는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다.
이것을 규율하는 단체는 유니코드 콘소시엄(Unicode Consortium)이라고 한다.
전 세계의 모든 문자를 담는 ISO/IEC 10646 코드표를 사용함으로써, 각 언어와 문자 체계에 따른 충돌 문제를 해결하였다. 따라서 유니코드를 사용하면 한글과 신자체·간체자, 아랍 문자 등을 통일된 환경에서 깨뜨리지 않고 사용할 수 있다.
UTF-8
UTF-8은 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로, 켄 톰프슨과 롭 파이크(이분은 GO언어를 만드신분)가 만들었다.
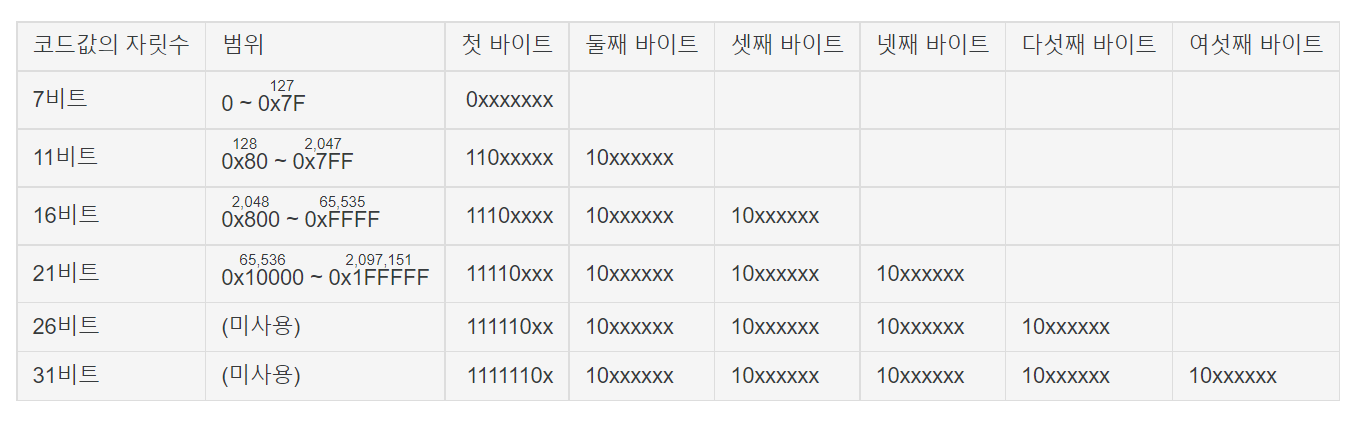
풀네임은 Unicode Transformation Format - 8bit 8의미는 8비트 1바이트를 기준으로 인코딩한다는 의미이다.
코드 페이지는 65001로, UTF-8로 표현 가능한 길이는 최대 6바이트지만 다른 인코딩과의 호환을 위해 4바이트까지만 사용한다.
그래서 한 글자가 1~4바이트 중 하나로 인코딩될 수 있으며, 1바이트 영역은 아스키 코드와 하위 호환성을 가진다. 아스키 코드의 0~127까지는 UTF-8로 완전히 동일하게 기록된다.
유니코드는 U+10FFFF까지만(10진법으로는 1,114,111) 이용하는데, UTF-8은 아래에 나와 있듯이 가변 바이트 길이를 선언하기 위해 꽤 많은 비트를 잡아먹고도 2,097,151까지 인코딩할 수 있기 때문에 4바이트만으로도 충분하고도 남는다.
장점
유니코드가 널리 쓰이기 전부터 형성된 인터넷 문서들은 대부분 아스키 코드를 기본으로 해서 작성되었고, 특히 기존의 HTML 태그나 자바스크립트 등 아스키로 구축된 사이트를 별다른 변환 처리 없이 그대로 쓸 수 있는 엄청난 장점이 있었다. 더군다나 UTF-8은 엔디안에 상관없이 똑같이 읽을 수 있으므로 크로스플랫폼 호환성도 뛰어났다.
ASCII 호환성, C로 작성된 Unix 프로그램 호환성, BOM이 필요없다든가, 엔디안을 따지지 않아도 된다든가, 파싱에 예외모드 확장 문자 처리 등등이 필요 없고, 그 덕에 실체 처리속도도 더 빠르다든가 하는 엔지니어링 측면에서의 수많은 장점도 존재한다.
가장 큰 장점은 단일인코딩 UTF-16은 하위 인코딩 문제가 매우 심각했는데, 인코딩에 여러 하위 방식이 존재해 읽을 때마다 그냥 UTF-16이라고만 하면 절대 디코딩을 할 수 없었다고 한다.
출처
https://swconsulting.tistory.com/48 [Software Consulting Service]
https://ko.wikipedia.org/wiki/UTF-8
https://namu.wiki/w/UTF-8
