정의 :
해시 테이블 또는 해시맵은 키를 값에 매핑 할 수 있는 구조인, 연관 배열 추상자료형을 구현하는 자료구조이다.
- 대표적인 파이썬의 dictionary는 해시테이블을 이용한 자료구조이다.
- 추가로 Java의 Map 인터페이스의 구현체 ex) HashMap, HashTable..

특징 :
- 해시함수란 임의 크기 데이터를 고정 크기 값으로 매핑하는데 사용할 수 있는 함수를 말한다.
- 해시 테이블을 인덱싱 하기 위해 위 그림 처럼 해시함수를 사용하는 것을 해싱이라 한다.
- 해싱은 최적의 검색이 필요한 분야에 사용되며, 심볼테이블 등의 자료구조를 구현하기에 적합하다.
- 해시함수는 checksum(TCP에서 송,수신간의 정합성을 확인하기위해 header값에 적재된 값), 랜덤함수, 암호(비대칭키 매칭과정에서도 sha-256 알고리즘이 사용됨)등과도 관련이 깊다.
좋은 해시 함수란?
- 해시함수 값의 충돌이 적을 수록 좋은 해시함수이다.
- 쉽고 빠른 연산
- 해시 테이블에 전체에 해시 값이 균일하게 분포
- 해시테이블의 사용효율이 높을 것
- 사용할 키의 모든 정보를 이용하여 해싱
해시의 충돌문제 :
생각 보다 해시의 충돌은 더 많이 일어난다.
그예로, 생일을 들자면, 비둘기집 원리(n<m일때 충돌은 일어나지 않는다)에 따르면 365명이 모였을 때 해시가 충돌될 경우는 366명이 모였을때 2명의 동일 생일자가 나올 것이라 얼핏 생각할 수도 있는데 사실, 23명만 모여도 50%가, 57명이 모이면 99%를 넘어선다는 증명을 확인할 수 있다. 즉 아무로 좋은 해시함수라도 충돌이 생각보다 쉽게 발생한다는 점인데, 이를 어떻게 해결하는가에 대해 고민해 보아야한다.
크게 2가지 방법이 있다.
1. 개별 체이닝
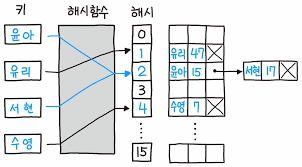
개별 체이닝은 중복된 해시값이 생길시 연결 리스트를 통해 체이닝으로 이어가는 방법이다.
최근 구글에서는 해시함수를 딥러닝으로 학습시켜, 충돌을 최소화하는 모델을 만들었다고 한다.
2. 오픈 어드레싱
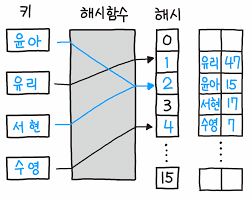
오픈 어드레싱 방식은 충돌 발생 시 선형 탐색을 통해 빈공간을 찾아나서는 방식이다.
사실상 무한정 저장할 수 있는 체이닝 방식과 달리 오픈 어드레싱 방식은 슬롯의 수만큼만 저장할 수 있다. 이러한 특성 때문에 해시값과 일치하는 주소에 저장된다는 보장은 없다.
또 선형 탐색으로 같은 해시값의 빈공간을 찾아 적재하기에, 데이터가 뭉치는 경향이 있다. 이러한 현상을 클러스터링(clustering)이라고 하는데 이러한 클러스터가 인접 클러스터랑 서로 합쳐지게되면 선형 탐색시 더 효율성을 떨어뜨릴 수 있다.
Tip :
오픈 어드레싱 방식은 슬롯의 수만큼만 저장할 수 있다고 했는데 일정 비율 이상 데이터가 차면, 더 큰 크기의 또다른 버킷을 생성하여 다시 리해싱하는 작업이 일어난다.
이는 동적 배열에서 공간이 가득찰 경우 더블링으로 새롭게 복사해서 옮겨가는 과정과 유사하다.
언어별 해시 테이블 충돌 대처 방법
C++ : 개별 체이닝
Java : 개별 체이닝
Python : 오픈 어드레싱
Ruby : 오픈 어드레싱
그렇다면 왜 파이썬은 오픈 어드레싱을 쓰는 것일까?
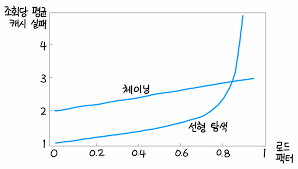
파이썬에서는 "매번 체이닝시 malloc으로 메모리를 할당하는 오버헤드가 높아 오픈 어드레싱을 사용한다고 한다."
위 그림에서 보듯이, 일반적으로 오픈 어드레싱 방식이 더 효율성이 좋다. 반면 로드팩터가 80%이상인 경우 기하급수적으로 실패율이 올라가는데 이는 앞서 언급한 선형탐색과 클러스터링 문제 때문이다. 그래서 이를 해결하기 위해 로드팩터를 작게 잡아(버킷의 크기를 키운다) 성능 저하 문제를 해결한다고 한다.
참고자료
'파이썬 알고리즘 인터뷰 - 박상길'
