
본 글의 내용은 Operating Systems: Three Easy Pieces의 Multiprocessor Scheduling (Advanced) 챕터를 정리한 것입니다.
☑️ 개요
-
한 개의 CPU 코어의 성능을 높이는 것에 한계가 오면서 멀티코어 프로세서가 등장하게 되었다.
-
그러나 CPU 코어가 두 개 이상으로 늘어나면 여러 어려움이 발생하는데, 특히 일반적인 프로그램은 단일 CPU만 사용하므로 더 빠르게 실행되지 않는다는 것이다.
-
그래서 스레드를 사용하여 병렬로 실행되도록 프로그램이 다시 작성되어야 한다.
-
프로그램 외적으로도 OS에서 발생하는 문제는 멀티프로세서를 어떻게 스케줄링 해야 하느냐에 대한 문제이다. 기존 스케줄링 방식에 한정되지 않고 여러 CPU에서 동작하도록 확장을 해야한다.
☑️ 배경 지식: 멀티프로세서 아키텍처
-
단일 코어 대신 멀티 프로세서를 사용하게 되면서 하드웨어 캐시 사용 및 프로세서 간의 데이터 공유 방식에 근본적인 차이가 생겼다.
-
하드웨어 캐시에는 자주 사용하는 데이터의 복사본을 저장하는데, 접근했던 데이터의 값을 갱신하는 경우도 있다. 그럴 때는 메모리까지 데이터를 갱신하는 것은 느리므로, 캐시만 새 값으로 갱신한다.
-
이런 상황은 멀티 프로세서에서 문제가 되는데, 만약 CPU 1에서 접근한 데이터가 캐시를 갱신한 뒤에 CPU 2가 해당 데이터에 접근하면 메모리 값은 갱신되지 않았으므로 이전 값을 사용하게 될 수도 있다.
-
이런 문제를 캐시 일관성(cache coherence) 문제라고 하며, 대응하기 위해 하드웨어가 메모리 접근을 모니터링하며 문제를 방지한다.
-
버스 기반 시스템에서는 버스 스누핑(bus snooping)이라는 방식을 사용하는데, 각 캐시가 주 메모리와 연결되는 버스를 관찰한다. 그러다가 CPU가 캐시에 보관하는 데이터를 갱신하면 그것을 인지하여 다른 캐시도 갱신하게 된다.
☑️ 잊지 말아야 할 것: 동기화
-
캐시 일관성 문제를 해결하며 모든 게 해결될까? 이제는 데이터가 공유될 때 생기는 동시성 문제를 해결해야 된다.
-
여러 프로세서에서 공유 데이터 및 구조체에 접근할 때는, 정확성을 위해 상호 배제 primitive(lock)을 사용해야 한다.
예시: 공유 큐

-
공유 큐를 사용하게 된다고 했을 때, 위와 같은 함수가 존재할 수 있다.
-
이때 여러 개의 스레드가 Lock 없이 위 함수를 호출하면, 동일한 헤드를 중복으로 제거할 수도 있다.
-
그래서 Lock을 사용해야 되는 것인데, Lock을 사용하면 성능적인 문제가 생기게 된다. 프로세서 수가 늘어남에 따라 공유 데이터에 대한 접근도 느려진다.
☑️ 캐시 선호도(Cache Affinity)
-
프로세스가 특정 CPU에서 실행되면, 해당 프로세스에 대한 정보가 CPU의 캐시(및 TLB)에 상당히 기록되게 된다.
-
이 프로세스가 다음 차례에 다시 실행될 때, 동일한 CPU에서 실행하는 것이 유리한 경우가 많다. 그래서 멀티프로세서 스케줄링에서는 이러한 점을 고려해야 되며, 가능한 동일한 CPU에 프로세스를 유지하는 것이 선호되기도 한다.
☑️ 단일 큐 스케줄링
-
멀티프로세서 스케줄러를 구현하는 가장 기본적인 접근 방식은 모든 작업을 단일 큐에 넣는 것이다. 이것을 단일 큐 멀티프로세서 스케줄링 혹은 SQMS라 부른다.
-
그러나 이 방식에는 확장성이 부족하다는 문제가 있다. 멀티 프로세서에서 사용되면서 Lock이 삽입되는데, CPU 수가 증가하면서 성능이 크게 저하된다.
-
하나의 Lock에 경합이 늘어나면서 Lock 오버헤드가 작업 수행시간보다 커지게 된다.
-
또한 캐시 선호도를 살릴 수 없게 된다. 아래 예시를 보자.

- 실행할 작업이 A, B, C, D, E 5개가 존재하고, 프로세서가 4개라고 해보자.
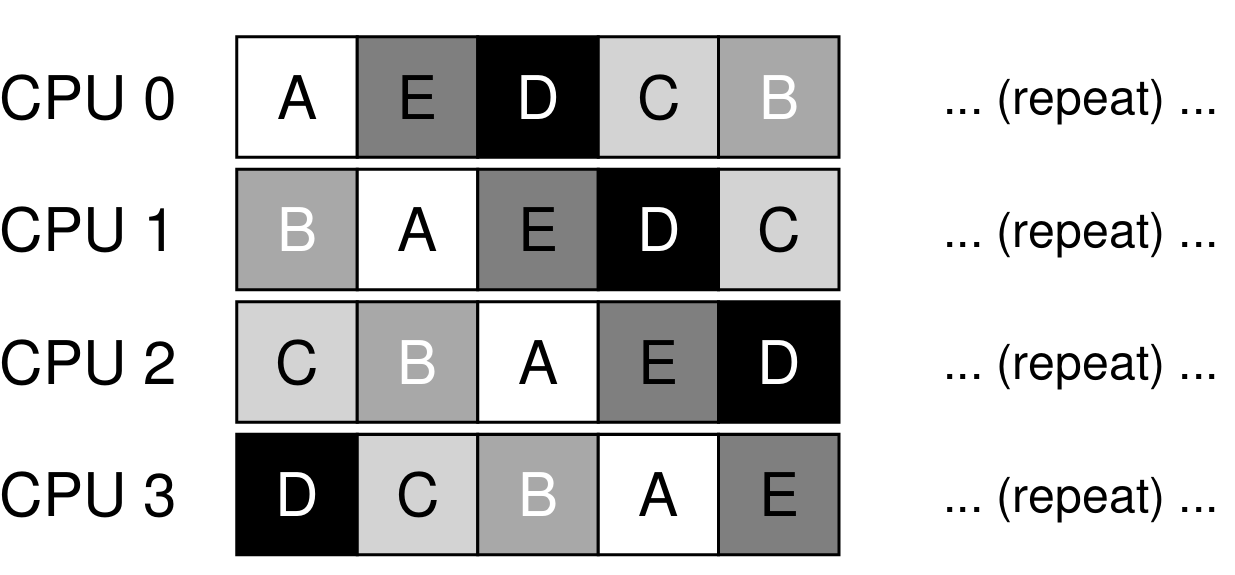
-
각 프로세서는 단순히 단일 큐에서 다음에 실행할 작업을 선택하기 때문에, 각 작업은 프로세스를 떠돌아다니며 실행되게 된다.
-
이 문제를 처리하기 위해 SQMS 스케줄러에 선호도 메커니즘을 포함시킨다. 작업이 가능한 한 동일한 프로세서에서 실행되도록 하는 것인데, 아래와 같은 형태로 적용된다.
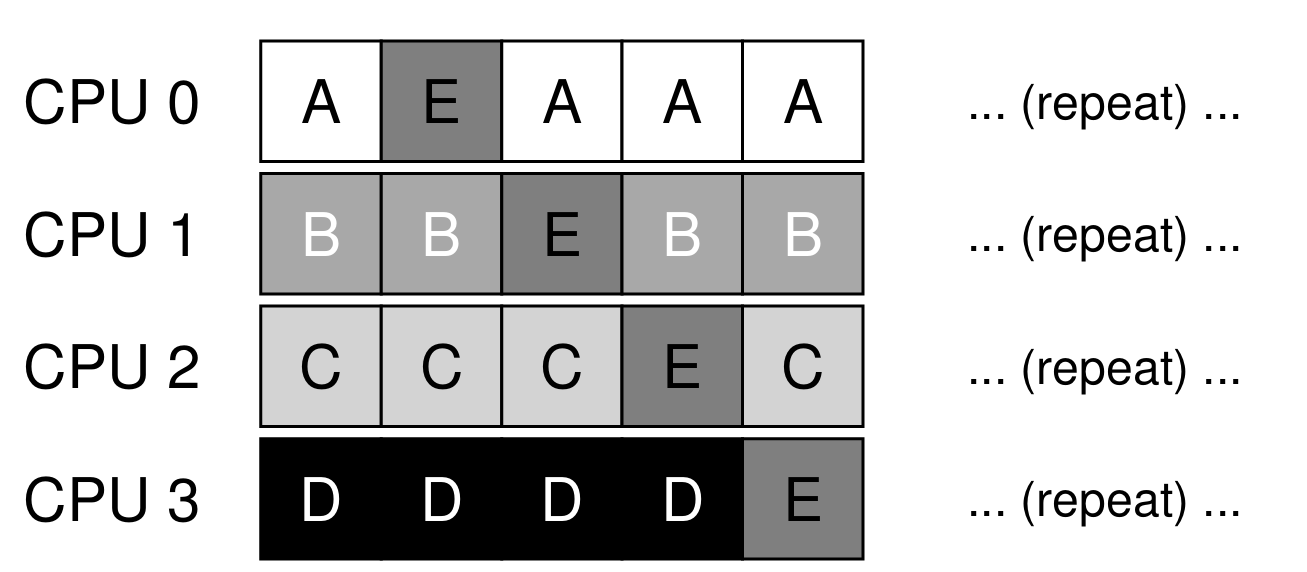
-
부하 균형을 맞추기 위해 일부 작업을 이동시키는 방식인데, 이것을 구현하는 게 복잡한 것이 또 다른 문제이다.
-
결론적으로 SQMS 접근 방식은 구현은 간단하지만, 동기화 오버헤드가 있어 확장성이 떨어지고 캐시 선호도를 보존하기가 어렵다.
☑️ 다중 큐 스케줄링
-
SQMS의 문제를 해결하기 위해 프로세서당 하나씩 큐를 만들어 여러 개의 큐를 사용하는데, 이런 접근 방식을 다중 큐 멀티 프로세서 스케줄링 (MQMS)라 부른다.
-
작업이 시스템에 들어오면 몇 가지 기준에 따라 정확히 하나의 스케줄링 큐에 배치된다.
-
그런 다음 독립적으로 스케줄링 되기 때문에, SQMS에서 발생하는 공유 및 동기화 문제를 회피할 수 있다.

-
만약 A, B, C, D 4가지 작업이 있었다면 위 그림과 같이 두 프로세서에 나뉘어져 처리된다. (스케줄링으로 라운드 로빈을 사용하는 예시)
-
그러나 여기서 또 문제가 발생하는데, 부하 불균형(load imbalance)이 발생할 수 있다. 아래 예시를 보자.

- CPU 0에 작업 A만 배치됨으로써 A가 B, D보다 거의 두 배 많게 프로세서를 사용하게 된다. 여기서 만약 A가 종료되면 아래와 같은 상황이 된다.

-
A가 사라지면서 CPU 0은 완전히 유휴 상태가 되어버렸다.
-
결론적으로 이것을 해결하기 위해 마이그레이션을 활용한다. 한 CPU에서 다른 CPU로 작업을 이전시켜 부하 균형을 달성한다.
-
마이그레이션에도 어려움이 있는데, 아래 예제를 보자.

- 만약 CPU 0의 큐에 A만 단독에 있다면, B와 D는 CPU 1에서 번갈아 가며 처리될 것이다.

-
부하 균형을 맞추기 위해 작업은 지속적으로 마이그레이션된다. 그럼 이런 마이그레이션은 어떤 기준으로 처리해야 할까?
-
기본적인 접근 방식은 작업 훔치기(work stealing)가 있다. 작업이 부족한 큐에서 다른 큐를 확인하고, 자신보다 많은 작업을 보유하고 있으면 하나 이상의 작업을 훔친다.
-
그러나 이 방식 또한 너무 자주 다른 큐를 확인하면 오버헤드가 높아지기 때문에, 적절한 임계값을 찾아야 할 필요가 있다.
☑️ Linux 멀티프로세서 스케줄러
-
리눅스 스케줄러는 아직 일반적인 솔루션이 정해지지 않았는데, O(1) 스케줄러, CFS, BFS 등 세가지 다른 스케줄러가 존재한다.
-
여기서 O(1)과 CFS는 MQMS를 사용하는 반면, BFS는 SQMS를 사용한다. 즉, 두 가지 접근 방식 모두 OS에서 활용 가능한 것이다.
✅ 요약
-
캐시 일관성, 동시성, 캐시 선호도 등의 문제로 인해 멀티프로세서에 적합한 스케줄링이 필요해졌다.
-
단일 큐 스케줄링 (SQMS)는 구현이 단순하나, 동시성을 처리하기 위해 사용한 Lock이 전반적인 성능을 저하시켜 확장성이 낮고, 캐시 선호도에 대응하기 어렵다는 문제가 있다.
-
다중 큐 스케줄링 (MQMS)는 동시성과 캐시 선호도 문제를 해결할 수 있지만, 부하 불균형을 해결하기 위해 마이그레이션이 필요하며, 적합한 마이그레이션 전략이 필요하다.
-
이 마이그레이션의 예시로 작업 훔치기(work stealing)가 있는데, 다른 큐를 너무 자주 확인하면 오버헤드가 심해지기 때문에 적절한 임계값이 필요하다.
