
본 글의 내용은 Operating Systems: Three Easy Pieces의 Paging: Introduction 챕터를 정리한 것입니다.
☑️ 개요
-
OS는 공간 관리를 위해 두 가지 접근 방식 중 하나를 취한다.
-
첫번째는 Segmentation처럼 공간을 다양한 크기의 조각으로 잘개 쪼개는 것이다.
-
이 방식에는 외부 단편화 라는 문제가 있다.
-
두번째로는 공간을 고정된 크기로 분할하는 것이 있다. 이것을 Paging이라고 부르며, 고정 크기의 단위로 나뉜 공간을 Page라 칭한다.
-
이렇게 물리 메모리를 Page frame이라 불리는 고정 크기의 slot(컨테이너)으로 이루어진 배열로 인지하게 되며, 각 frame은 하나의 가상 메모리 Page를 포함할 수 있다.
☑️ 페이징 예시 및 설명
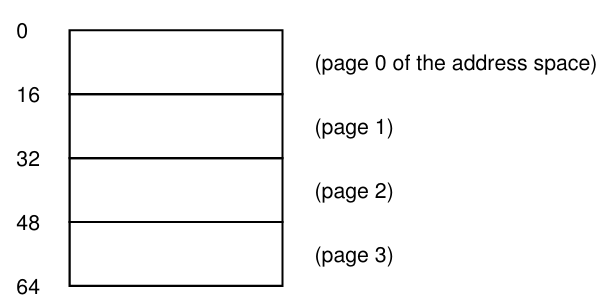
- 위 그림은 16바이트의 페이지 4개가 존재하는 총 64바이트의 주소 공간이라고 할 수 있다. (실제로는 32비트 기반의 4GB의 주소 공간, 그리고 64비트 기반의 주소 공간까지도 존재한다.)
-
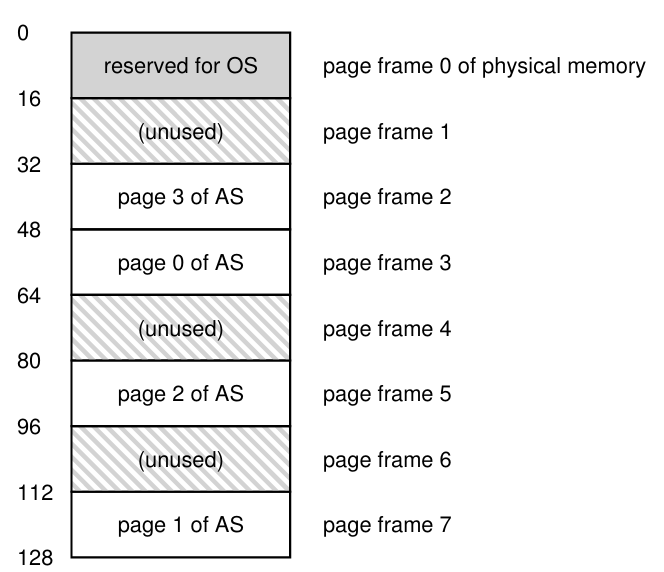
위 그림처럼 물리 메모리는 여러 개의 고정 크기의 slot으로 구성되며, 여기서는 8개의 page frame으로 구성되어 있다.
-
Paging은 이런 구조에서 확실히 여러 장점이 있다. 가장 중요한 장점은 유연성이다. 예시로 힙, 스택이 증가하는 방향과 사용 방법에 대해 고민할 필요가 없다.
-
또 다른 장점은 공간 관리의 단순성이다. OS는 모든 여유 페이지의 목록을 보관하고, 여유 페이지가 4개 필요하다면 목록의 첫 4개를 선택하면 된다.
-
또한 각 가상 페이지가 물리 메모리 어디에 위치하는지 기록하는 Page table이 존재한다. 이것은 프로세스별로 유지되며, 가상 페이지에 대한 address translation을 저장한다.
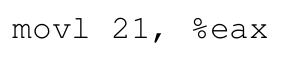
-
다시 예시로 돌아가서 64바이트의 주소 공간에, 16바이트의 페이지 4개가 존재하므로 비트는 2비트가 필요하다. (4=2^2) 그래서 6비트(64=2^6) 중 상위 2비트가 가상 페이지 번호 (VPN)을 의미하게 된다. 그리고 나머지 4비트는 우리가 페이지 내에 목표로 하는 위치(오프셋)다.
-
이때 위 예시로 보이는 어셈블리를 동작시킨다고 해보자.
21은 이진수로 나타냈을 때010101이고, 이는 아래 그림처럼 나타낼 수 있다.

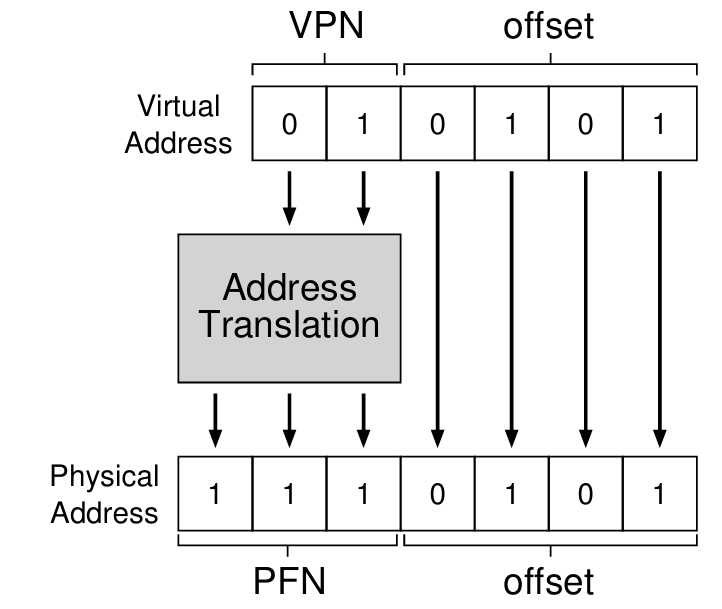
- 즉 가상 주소
010101은01(1) 페이지의0101(5)바이트 라는 의미이다. 이제 가상 페이지 번호(VPN)와 Page table을 통해 물리적인 실제 페이지 번호(PFN 혹은 PPN)를 알아낼 수 있다.
-
오프셋 비트는 우리가 목표로 하는 페이지 내의 바이트만 알려주기 때문에, 가상이나 실제나 동일하게 유지된다.
-
이것들을 기반으로 우리는 몇가지 질문을 던질 수 있다.
-
페이지 테이블은 어디에 저장되나요?
-
페이지 테이블은 어떤 컨텐츠를 가지고 있고, 크기는 어느정도 인가요?
-
페이징 때문에 시스템이 느려지나요?
-
☑️ 페이지 테이블은 어디에 저장되나요?
-
페이지 테이블은 소규모 세그먼트 테이블이나 base&bound 쌍보다 훨씬 더 커질 수 있다.
-
32비트 주소 공간에 VPN 비트가 20비트라고 해보자. 그럼 OS가 관리해야 되는 페이지의 주소 변환이
2^20개, 즉 대략 100만개라는 것을 의미하며, 항목(page table entry, PTE)당 4바이트가 필요하다고 했을 때 무려 4MB가 필요하다. -
또한 페이지 테이블은 프로세스 별로 관리되기 때문에, 프로세스가 100개라면 400MB가 필요하다고 말할 수 있다.
-
그래서 페이지 테이블을 보관하기 위한 별도의 하드웨어를 구성하지 않으며, 각 프로세스를 위한 페이지 테이블은 메모리 어딘가에 보관된다.
-
그리고 OS 가상 메모리에 의해 디스크에 스왑되는데, 스와핑에 대한 내용은 추후에 알아보자.
☑️ 페이지 테이블에 존재하는 정보는?
-
페이지 테이블은 VPN(가상 페이지 번호)를 PFN(물리 프레임 번호)에 맵핑하는 데 사용하는 데이터 구조일 뿐이다.
-
가장 간단한 형태는 선형 페이지 테이블로, 배열에 불과하다. OS는 이 배열에 VPN을 인덱스로 사용해 PTE를 조회하고, PFN을 알아낸다.

-
이 PTE에는 여러 가지 비트 들이 있는데, 그 중 유효(valid) 비트는 해당 페이지가 사용 중인지 여부를 의미한다. 유효하지 않은 페이지에 접근하면 OS가 트랩을 생성하여 프로세스를 종료시킨다.
-
또한 사용하지 않는 페이지를 유효하지 않은 것으로 표시함으로써 물리 프레임을 할당하지 않아 많은 메모리를 절약할 수 있다.
-
또한 읽기, 쓰기, 실행 가능 여부를 나타내는 보호(protection) 비트가 존재하고, 이것에 허용되지 않는 방식으로 접근하면 OS가 트랩을 생성한다.
-
존재(present) 비트는 페이지가 메모리에 있는지 디스크에 있는지 (스왑되었는지) 나타낸다. 스왑을 통해 거의 사용하지 않는 페이지가 디스크로 이동하여 메모리가 확보된다. 어떤 경우에는 유효 비트없이 존재 비트로만 판단하는 경우가 있다.
-
더티 비트는 페이지가 메모리에 올라간 이후 수정된 적이 있는지를 기록한다.
-
참조 (reference, 혹은 accessed) 비트는 어떤 페이지가 접근되어 왔는지를 기록하며, 메모리에 유지시킬 근거로 사용된다.
-
이외에도 유저 모드에서 접근 가능한 지 여부를 저장하는 유저/슈퍼바이저 비트, 캐싱 방식을 결정하는 몇몇 비트 등이 포함된다.
☑️ 페이징은 느리다
- 앞서 설명한 대로 페이지 테이블은 꽤 커질 수 있고, 너무 크면 속도가 느려질 수 있다.
-
다시 아까의 어셈블리를 통해 페이징의 과정을 시뮬레이션 해볼 수 있다.
-
우선 가상 주소(
21)을 물리 주소로 변환하기 위해 페이지 테이블에서 PTE를 가져온 뒤, PFN을 알아내야 한다. -
원하는 PTE의 위치를 찾기 위해 아래의 작업을 수행하게 된다.

-
가상 주소에 마스크를 AND 연산하여 VPN 비트만을 남기고, SHIFT한다. 즉,
010101에서010000으로 바뀌고, 시프트 연산을 통해01이 된다. -
이제 페이지 테이블의 베이스 주소에 (이 값 *
PTE의 크기)를 더하면 우리가 찾는 PTE의 시작 주소가 되고, PFN을 얻어낼 수 있다. (복잡하게 생각할 필요 없이 PTE 배열에 인덱스로 접근하는 것이다.)
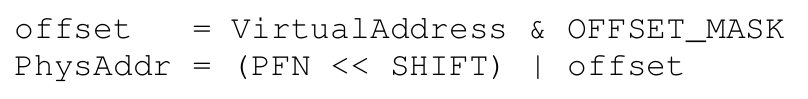
-
이제 가상 주소에서 얻어낼 수 있는 offset을 마스킹을 통해 얻어내고, 앞서 획득한 PFN과 OR 연산으로 합치면 실제 물리 주소를 획득하게 된다.
-
결론적으로 주소 번역을 위해 메모리 참조가 반복적으로 발생하였다. 이것은 비용이 많이 드는 작업이며, 프로세스 속도가 더욱 느려질 수 있다. 또한 페이지 테이블은 메모리를 차지하므로, 속도와 공간 제약이라는 두가지 문제를 극복해야 한다.
☑️ 메모리 참조 추적해보기
- 코드를 통해 페이징으로 인해 어느 정도의 메모리 참조가 발생하는지 확인해보자.

- 위 C 코드는 아래와 같은 어셈블리로 변환된다.

- 각 명령을 간단하게 설명하자면 아래와 같다.
%edi에%eax에 4(int 크기)를 곱한 수를 더한 자리에 0을 할당한다.%eax를 증가시킨다. (%eax는 코드에서i의 역할)%eax가0x03e8(1000)과 같은지 확인한다.- 다르면 다시 1024줄로 돌아간다.
- 이 과정에서 발생한 메모리 참조를 그래프로 표현하면 아래와 같다.
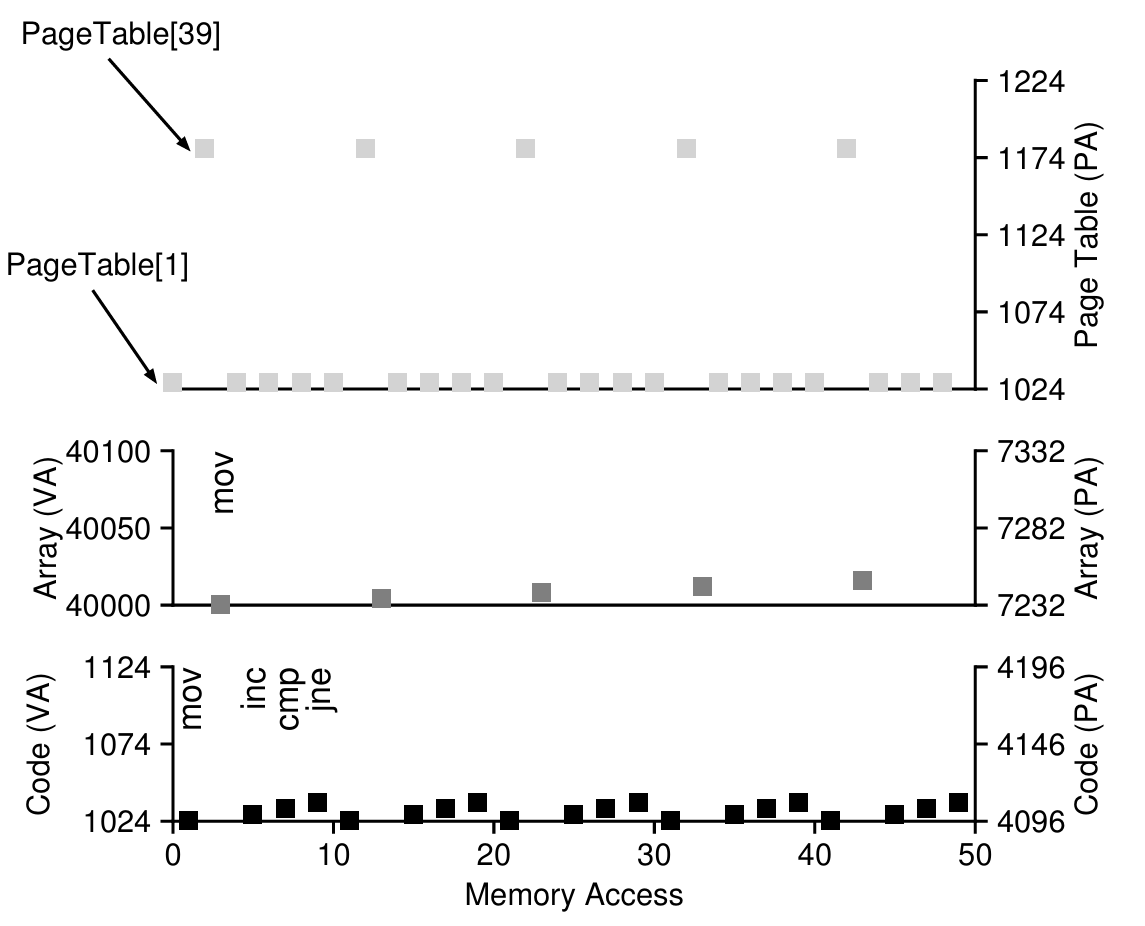
(그래프가 더럽게 복잡하지만 x축이 시간이다. x좌표가 미묘하게 다름을 인지하자)
-
위 과정은 다음과 같은 메모리 참조 양상을 보인다. 각 명령어는 실제 물리 프레임을 찾기 위한 페이지 테이블에 대한 참조, 그리고 명령어의 실제 주소를 찾은 뒤 처리를 위해 CPU로 fetch 하기 위한 실제 주소에 대한 참조다.
-
그래서 명령어마다 2번의 메모리 참조가 발생하며, 본 예시에서는 한 iteration에 4개의 명령어가 존재하기 때문에 8번의 메모리 참조가 발생한다.
-
그리고 배열의 값을 바꾸는 작업 또한 [배열의 실제 프레임을 찾기 위한 페이지 테이블 참조 & 값 바꾸기] 의 과정으로 2번의 메모리 참조가 발생하여, 8+2=10. 총 10번의 메모리 참조가 발생하게 된다.
✅ 요약
-
페이징은 메모리를 고정된 크기로 분할하는 것이다.
-
각 페이지의 주소 변환을 돕는 것이 페이지 테이블이다. 가상 주소의 VPN 비트로 실제 페이지 번호인 PFN을 얻어낸다.
-
페이지 테이블에는 PFN을 저장하는 PTE가 있으며, PTE에는 PFN 이외에도 다수의 비트를 기록한다.
-
페이징은 세그멘테이션과 비교했을 때 1. 외부 단편화가 일어나지 않고, 2. 가상 주소 공간을 유연하게 사용할 수 있다.
-
다만 페이지 테이블에 접근하기 위한 추가 메모리 접근이 발생하고, 이것이 심해지면 시스템 속도가 느려지게 된다.
-
또한 페이지 테이블 때문에 메모리가 낭비될 수도 있는데, 이것을 방지하기 위해 더 나은 페이징 시스템이 고안되었다. 그것이 TLB와 Multi level page table이다.
