
본 글의 내용은 Operating Systems: Three Easy Pieces의 Segmentation 챕터를 정리한 것입니다.
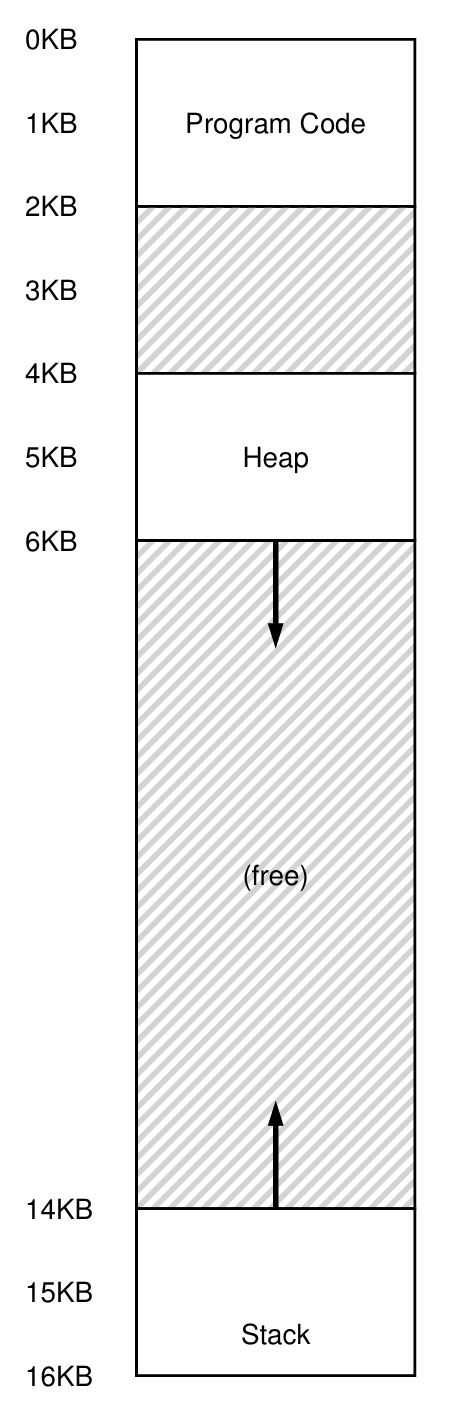
☑️ 스택과 힙 사이의 여유 공간 (Free chunk)
-
주소 공간(Address space)과 Base & Bound를 기반으로 한 메모리 가상화는 좋은 솔루션이었다.
-
하지만 스택과 힙 사이에 빈 공간(Chunk)이 생기는 것이 문제가 된다.
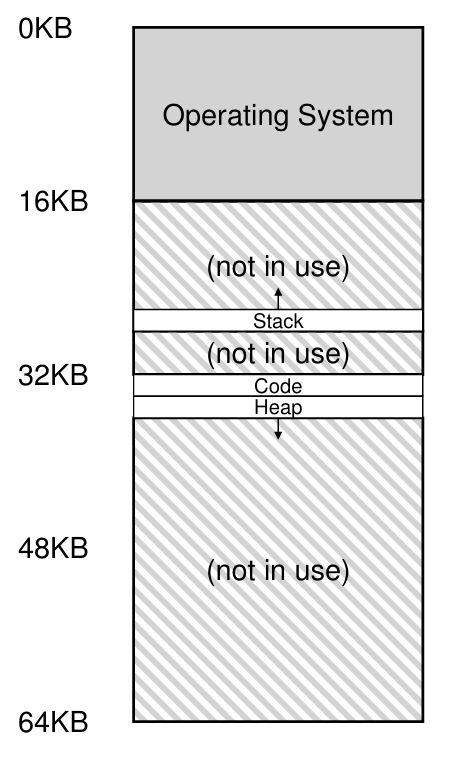
☑️ Segmentation
-
그래서 등장한 Segmentation은, 주소 공간을 논리적인 단위로 여러 세그먼트로 나누자는 것이다.
-
코드, 스택, 힙 영역을 각자 다른 세그먼트로 나누고, 각 세그먼트가 물리 메모리의 서로 다른 부분을 차지한다.
-
이제 스택과 힙 사이에 의무적으로 차지하던 빈 영역은 사라지게 된다.
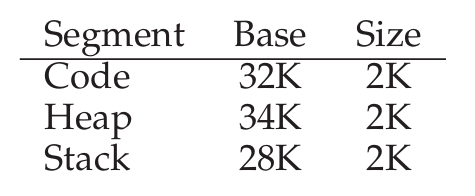
- 대신, 세 쌍의 주소 시작점과 용량 한계(bound)를 저장하게 된다. 즉. MMU의 하드웨어 구조는 3개의 Base 레지스터와 3개의 Bound 레지스터이다.
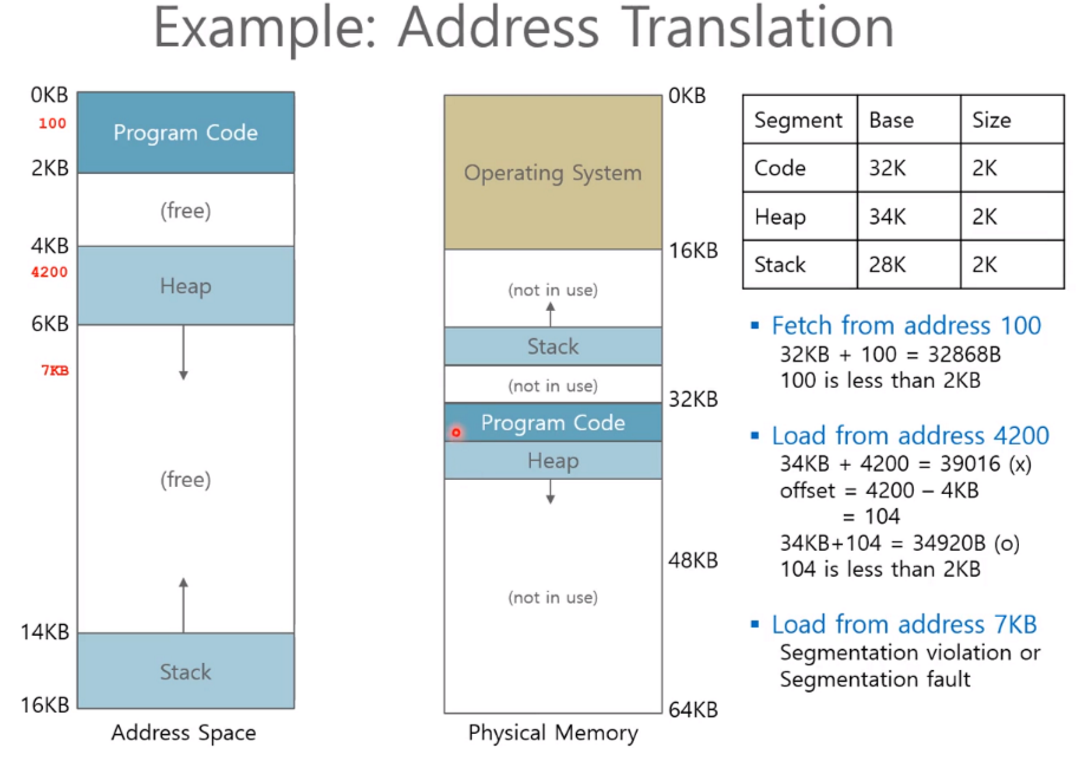
-
예시로 코드 영역에 100의 가상 주소를 갖는 Fetch Instruciton이 존재한다고 해보자, 해당 Instruction은 32KB에서 시작해 100만큼 공간을 차지할 것이다. (코드 영역은 가상 영역에서 0부터 시작하기 때문에)
-
100은 2KB보다 작은 수기 때문에 bound를 벗어나지 않고, 정상적으로 공간을 사용한다.
-
다른 예시로 힙 영역에 4200의 가상 주소를 갖는 Instruction이 존재한다고 해보자, 이때는 곧바로 힙의 물리 시작 주소에 4200을 더해서는 안 된다. 가상 주소가 4KB부터 시작하기 때문이다.
-
즉, 4200 - 4096 ⇒ 104. 물리 시작 주소에 104를 더해야 한다. 즉, 34K + 104 = 34920이 실제 물리메모리 주소이다.
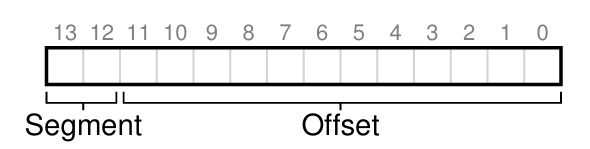
☑️ 어떤 종류의 세그먼트인가?
-
세그먼트의 시작점을 저장할 수 있는 단순한 방법은 가상 주소의 상위 비트에 세그먼트 정보를 저장하는 것이다.
-
예시로, Segment 비트가 00이라면, 하드웨어는 해당 세그먼트가 Code 세그먼트임을 인지한다. 또는 비트가 01이라면 해당 세그먼트가 Heap 세그먼트임을 인지하는 것이다.
-
이전의 가상 주소 4200 예시를 다시 끌고 오면, 해당 Instruction의 offset은 104였고, Heap 세그먼트에 포함되었기 때문에 아래와 같은 주소 비트를 가질 수 있다.
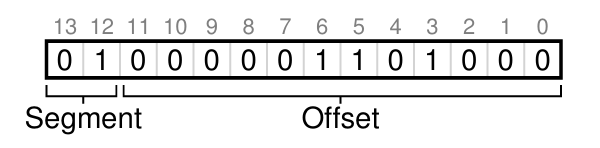
- 이런 방식과 별개로 암시적(implicit)으로 판단하는 방법도 있는데, 주소가 어떻게 형성 되었는 지로 파악하는 방식이다. 예를 들어 주소가 프로그램 카운터를 통해 생성됐다면, 명령어 패치라고 판단해 Code 세그먼트로 인지한다.
☑️ 스택 세그먼트는?
-
스택과 같은 경우는 거꾸로 자라난다.
-
그래서 단순히 Base와 Bound를 저장하는 것 이외에 자라나는 방향을 저장해야 한다.
-
이것은 단순하게 비트 하나를 더 저장하는 것으로 해결할 수 있다. (1이면 정방향, 0이면 역방향)
-
다만 offset 계산은 달라져야 한다.
-
예) 세그먼트 비트가
11 1100 0000 0000일때,
상위 2비트는 스택 세그먼트 타입임을 의미한다.
그리고 offset은 나머지 비트들인데, 3 * 2^10 이므로, 3KB 이다.
스택은 거꾸로 자라나므로, Base 주소에 offset을 그대로 더하면 안 된다.
세그먼트의 최대 크기에서 offset을 뺀 값을 Base 주소에 더해야, 비로소 제대로 된 주소를 얻게 된다.
만약 세그먼트 최대 크기가 4KB 라면, 3KB - 4KB = -1KB이고,
이것을 Base 주소에 더하면 그것이 올바른 주소이다.
☑️ Code 세그먼트 공유하기
-
Segmentation이 점점 발전해오면서, 메모리 효율성에 대한 수요가 점점 늘어나게 되었다.
-
그것을 실현시키기 위해 도입된 것이 Code 세그먼트를 여러 프로세스가 공유하는 것이었다.
-
이것 또한 세그먼트 확장 방향을 비트 값으로 기록했던 것처럼, 세그먼트 공유에 대한 정보를 비트 값으로 저장해놓는다.
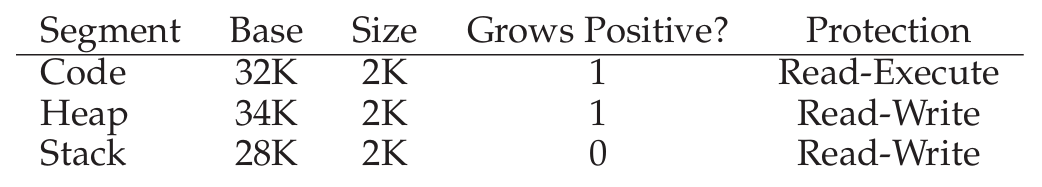
-
읽기/쓰기/실행 가능 여부를 기록해놓고, 읽기 전용이라면 다수의 프로세스에서 별다른 체크없이 코드를 공유한다.
-
물론 OS가 해당 Code 세그먼트를 공유할 수 있게 만들어주는 것이다. 각 프로세스들은 자신만의 메모리 영역을 접근하고 있다고 착각하며 코드를 사용한다.
-
만약 프로세스가 읽기 전용 세그먼트에 쓰기를 시도하거나, 실행 불가 세그먼트에 실행을 시도하는 경우가 발생하면, OS가 해당 프로세스를 강제 종료 시킨다.
☑️ Fine-grained vs. Coarse-grained
-
지금까지의 예시와 같이 코드, 스택, 힙과 같이 몇 개의 세그먼트만 만들어내는 것은 fine-grained segmentation이라 한다.
-
그러나 주소 공간을 여러 개의 작은 세그먼트로 구성할 수도 있으며, 이것을 coarse-grained segmentation이라 한다.
-
많은 세그먼트를 만들어 내려면 메모리에 저장하는 segment table과 같은 하드웨어 지원이 필요하고, 그것은 시스템이 세그먼트를 더욱 유연하게 활용할 수 있게 돕는다.
☑️ Segmentation의 문제
-
스택과 힙 사이의 빈 공간을 제거하자는 아이디어로부터 탄생한 Segmentation이었으나, 또 다른 문제가 있었다.
-
첫번째로 context switching이다. OS는 늘어난 세그먼트 레지스터를 올바르게 저장하고 복원할 필요가 있었다.
-
두번째로 더욱 중요한 메모리 관리이다. 세그먼트의 크기는 각기 다를 수가 있었기 때문에, 외부 단편화가 발생하였던 것이다. (세그먼트 사이에 빈 공간이 생겼다)
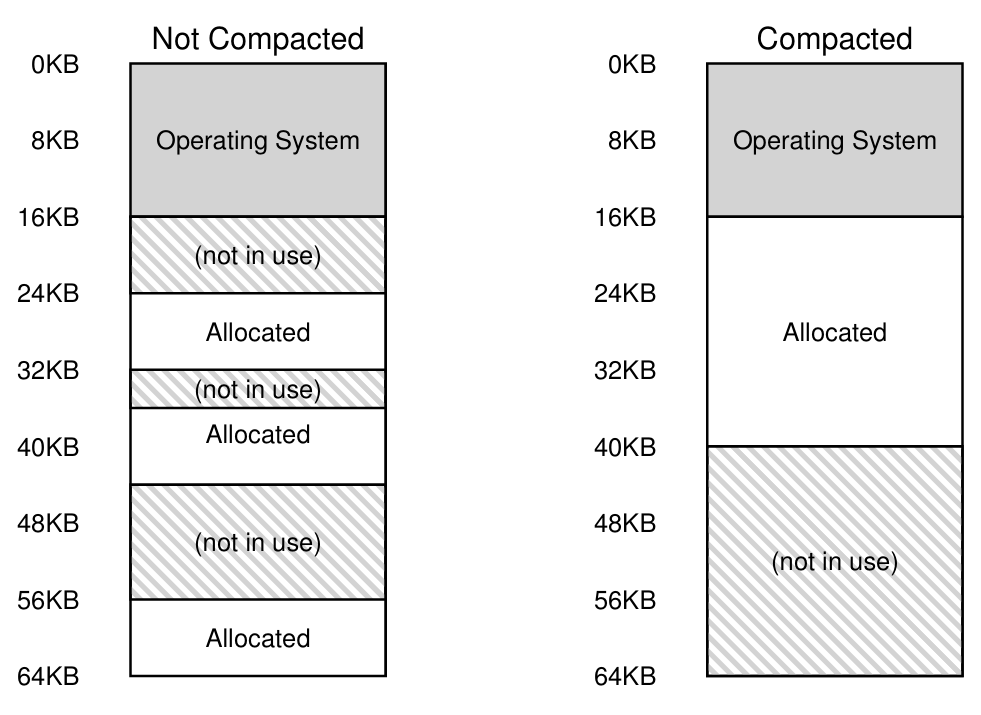
-
이것을 위한 해결 책으로 compaction이 제시되었다. 세그먼트들을 연속적인 메모리 공간으로 복사하는 것이었다. 이때 세그먼트 값을 저장하는 레지스터 들에게도 새로운 세그먼트의 위치를 갱신해주었다.
-
하지만 또 compaction에게 또 다른 문제가 있었으니, 그것은 compaction의 하드웨어적 비용이 크다는 것이었다. 세그먼트를 연속된 메모리 영역으로 복사하는 것은 메모리 intensive하며, 세그먼트 레지스터 값을 갱신하는 것은 상당한 프로세서의 시간을 낭비했다.
-
그래서 외부 단편화를 해결하기 위해 free-list를 효율적으로 관리하려는 다양한 알고리즘이 제시되었다.
-
그러나 여전히 외부 단편화는 존재하고 있고, 그것이 최소화 되기 위한 노력은 아직도 이어지고 있다.
✅ 요약
-
Segmentation은 메모리 가상화에 효율성을 부여해주었다.
-
또한 세그먼트의 타입을 저장한다던지, 자라나는 방향을 저장한다던지 하는 방법이 비트 값 몇개로 해결되었기 때문에 쉽고 빠른, 오버헤드가 적은 방식으로 여겨졌다.
-
하지만 세그먼트의 크기가 다양하기에 외부 단편화라는 문제가 발생하였으며, compaction 혹은 다양한 알고리즘으로 해결하려는 시도가 있다.
-
또 다른 문제로는 유연하지 못하다는 것인데, 거의 사용되지 않는 영역이라도 일단은 메모리에 존재해야 한다는 단점이 있다.
-
그래서 위와 같은 문제 때문에 새로운 접근이 필요해졌고, Paging이 등장하였다.
