
본 글은 Operating Systems - Three Easy Pieces의 Scheduling: Intro 챕터를 정리한 글입니다.
☑️ 개요
-
CPU 가상화에는 low-level mechanism 뿐만 아니라 high-level intelligence가 요구된다.
-
이 high-level intelligence는 정책이라는 이름으로 불리운다. 그리고 스케줄링은 정책의 대표적인 예시이다. 실행 중인 프로세스를 중단하고 다른 프로세스를 실행하려고 한다면, 정책이 정한 올바른 기준에 의해 다음 프로세스가 선정되어야 한다.
-
스케줄링 정책을 구성하기 전에 어떤 가정이 필요할까?
-
어떤 측정 기준(metric)으로 스케줄링을 해야될까?
-
초기 컴퓨터 시스템에는 어떤 접근 방식이 사용됐을까?
☑️ Wordload(프로세스)에 대한 몇가지 가정
-
Job이라고도 불리는 프로세스에 대한 몇가지 가정을 해보자.
- 각각의 Job은 동일한 시간동안 동작한다.
- 모든 Job이 동일한 시간에 전달된다.
- 각각의 Job은 시작되기만 하면 완료될 때까지 실행된다.
- 모든 Job은 CPU만 사용한다. (입출력을 수행하지 않는다)
- 모든 Job의 실행 시간(run-time)은 파악되어 있다.
-
위 가정들은 조금만 생각해봐도 굉장히 비현실적이라는 것을 알 수 있다.
(어떤 가정은 그냥 말이 안 된다.) -
모든 Job의 실행 시간을 안다는 것은 스케줄러가 전지전능하다는 말과 다름이 없다.
☑️ 스케줄링의 기준: Metric
-
앞서 확인한 가정은 잠깐 제쳐두고, 정책에 필요한 것에 대해 생각해보자. 스케줄링 정책에는 Scheduling metric이라는 지표가 필요하다.
-
Metric이란, 무언가를 측정하는 데 사용하는 지표이며, 여러가지가 존재한다.
-
간단하게 처리 시간(turnaround time)이라는 지표를 예시로 들 수 있다.
처리 시간 = 작업이 완료된 시간 - 작업이 시스템에 전달된 시간
Time_Turnaround = Time_Completion - Time_Arrival-
우리는 지금 모든 Job이 동시에 전달된다고 가정하고 있다.
-
그러므로 위 식에서
Time_Arrival은 0이 되며, 이는Time_Turnaround=Time_Completion임을 의미한다. -
또 다른 주요 metric으로는 공정성(fairness)가 있다.
스케줄링에서 처리 시간과 공정성은 서로 상극인 경우가 잦다.
예) 성능을 위해 특정 Job을 배제시킨다면, 그것은 공정성이 줄어든 것이다.
☑️ FIFO: First In, First Out. 선입선출
-
이제 다양한 스케줄링 정책에 대해 알아보자.
FIFO는FCFS(선착순)라고도 불리는 가장 기본적인 스케줄링이다. -
간단하고 구현하기 쉽다는 장점을 가진다.
-
예시로 Job의 처리 시간이 같은 경우와 다른 경우를 보자.
- 처리 시간이 같은 경우
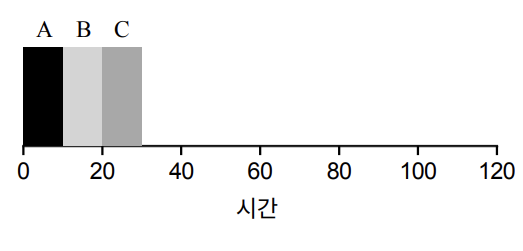
작업이 A, B, C 순서로 전달됐다면, 각각의 처리 시간인 10이 순서대로 경과된다.
즉, 평균 처리 시간은 (10 + 20 + 30) / 3 = 20이다.
- 처리 시간이 다른 경우
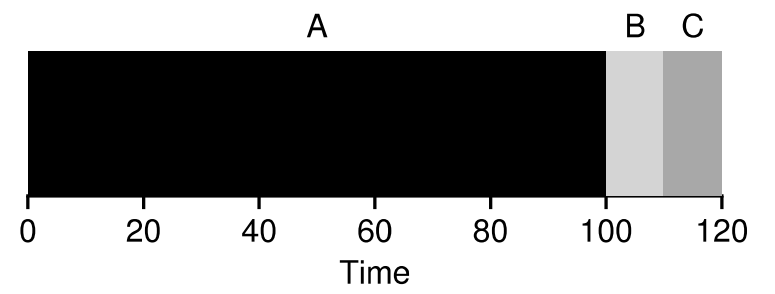
FIFO스케줄링의 문제점은 여기서 발생한다.
만약 먼저 도착한 작업의 처리 시간이 길다면, 다른 작업들은 작업 완료 시간이 길어진다.
위 예시에는 (100 + 110 + 120) / 3 = 110이라는 긴 평균 처리 시간이 도출된다.
- 처리 시간이 같은 경우
☑️ SJF: Shortest Job First. 최단 작업 우선
-
말 그대로 짧은 작업들을 우선으로 실행하는 정책이다.
-
이전 예시에
SJF를 적용하면, 아래와 같은 결과를 확인할 수 있다.
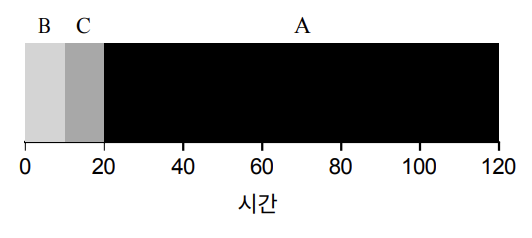
전과 달리 평균 처리 시간이 (10 + 20 + 120) / 3 = 50으로 단축된다.
다만 모든 작업이 동시에 전달된다는 가정하에서만 이상적인 알고리즘이다.
작업이 동시에 도착하지 않는다면 아래와 같은 결과를 확인할 수 있다.
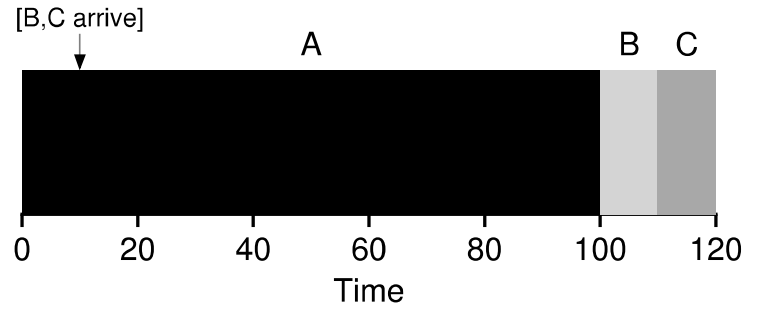
B, C가 더 늦게 전달됐기 때문에, B, C가 더 짧은 작업임에도 불구하고 A가 끝나길 기다릴 수 밖에 없다.
결국 평균 처리 시간은 (100 + (110 - 10) + (120 - 10)) / 3 = 103.33이 된다.
☑️ STCF: Shortest Time-to-Completion First
-
이제 작업이 완료될 때까지 실행되어야 한다는 가정을 없애보겠다.
-
익히 알고 있는 timer interrupt와 context switching을 위해, 스케줄러에게는 작업을 선점(preempt)하는 기능이 있다.
-
앞서 언급된
SJF스케줄링은 특정 작업이 완료될 때까지 다른 작업으로 전환되지 않았다. 즉, 비선점 스케줄러라고 할 수 있다. -
그것이 바로
STCF혹은PSJF(Preemptive SJF)라고 불리는 스케줄러이며, 언제든 새로운 Job이 시스템에 접속할 수 있다. -
남은 시간이 가장 짧은 작업을 우선으로 처리한다.
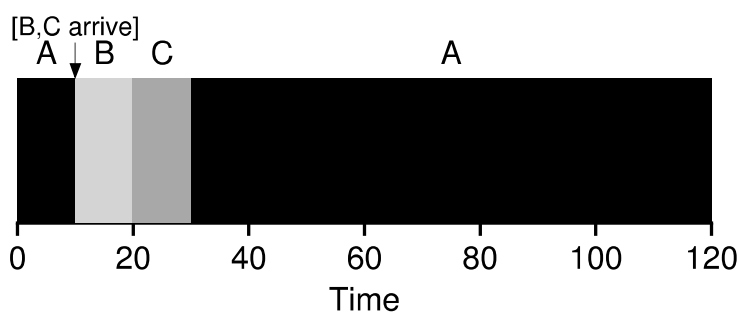
- 위 예시에서는 (120 + (20 - 10) + (30 - 10)) / 3 = 50의 평균 처리 시간을 확인할 수 있다.
☑️ 새로운 Metric: 응답 시간(Response Time)
-
작업 길이를 알고, 유일한 지표가 Turnaround time이라면
STCF는 더할 나위 없는 정책이다. -
하지만 time sharing 메커니즘이 적용되기 시작하며, 사용자는 터미널에 명령어를 입력하며 상호 작용하는 시스템을 바라게 되었다.
-
그로 인해 요구되기 시작한 지표가 응답 시간(response time)이다.
응답 시간 = 첫 실행 시점 - 작업이 전달된 시점-
STCF에서 봤던 예시를 다시 확인해보면 A는 (0 - 0) = 0, B는 (10 - 10) = 0, C는 (20 - 10) = 10의 응답 시간을 보인다. -
결론부터 말하자면
STCF는 응답 시간이 좋은 정책은 아니다. -
고로 응답 시간이 우수한 정책에 대해 고민할 필요가 있으며, 그로 인해 등장한 것이
Round-Robin이다.
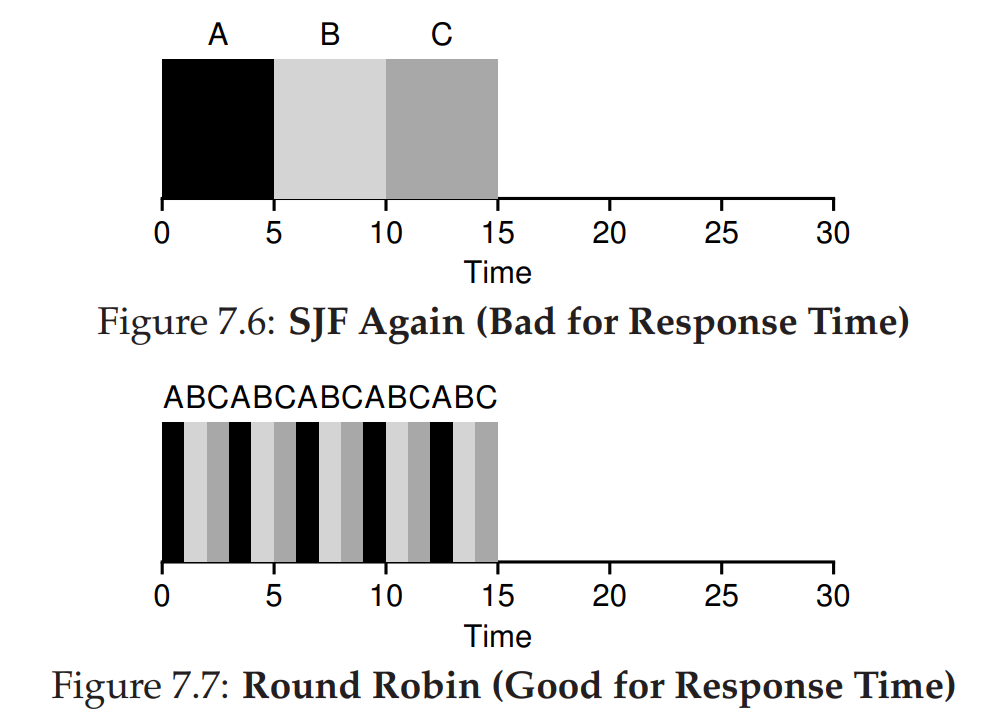
☑️ Round Robin (Time-slicing)
-
RR정책은, 작업을 일정 시간(scheduling quantum)동안 실행하고, 대기열의 다음 작업으로 전환한다. -
이런 이유로
RR은 time-slicing이라고도 불린다. -
Time slice의 길이는 interrupt 주기의 배수여야 하기 때문에,
interrupt가 10ms마다 일어난다면, 타임 슬라이스는 10, 20 등의 10의 배수다. -
결국
RR에서 가장 중요한 것은 time slice의 길이이다.
time slice가 짧다면 응답 시간은 향상되지만, context switching의 오버헤드가 발목을 잡게 된다. -
즉, 시스템 설계자는 시스템이 여전히 반응형으로 남으면서, 오버헤드를 감당할 수 있을 정도의 time slice 길이를 설정해야 한다.
✅ Context Switching의 비용
Context switching은 단순히 레지스터의 정보를 저장하고 복원하는 것에 그치지 않는다.
프로그램이 실행되면 CPU 캐시, TLB, branch predictor, on-chip HW 등에 많은 양의 상태 값이 쌓인다.
다른 작업으로 switching할 때 새로운 상태 값이 유입되기 때문에, 큰 비용이 발생할 수도 있다. -
하지만 처리 시간을 생각했을 때는 RR은 최악의 정책이기도 하다.
일반적으로 공정성(프로세스를 CPU에게 균등하게 분배하기)은 처리 시간과 반비례하기 때문이다. -
결국 두 metric을 동시에 충족시킬 수는 없으며, 두 가지 metric을 절충하는 것은 흔한 일이다.
☑️ 입출력을 포함하는 작업
-
이제 하나의 가정을 더 없애보자.
4번째 가정은모든 프로세스가 입출력을 사용하지 않는다였다.
입출력이 없는 프로그램은 존재 의미가 없다. -
특정 작업이 입출력 요청을 하면, 그 작업은 입출력이 완료되기까지 대기해야 한다.
그리고 스케줄러는 CPU가 다른 작업을 실행할 수 있도록 조율해야 한다. -
그럼 입출력이 완료되면 해당 요청을 했던 작업을 즉시 다시 실행해야 할까?
-
예시를 통해 확인해보겠다.
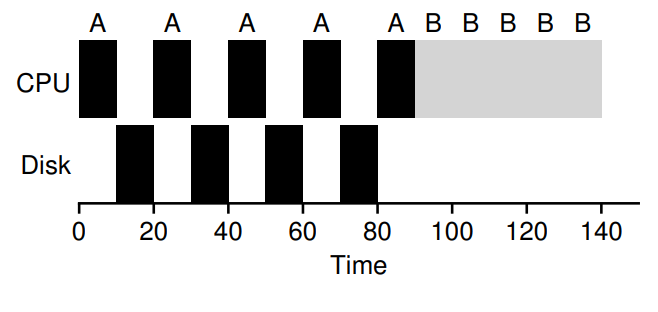
A는 10ms마다 입출력 요청을 생성하고 있다.
만약 A와 입출력 작업이 다 끝나고 나서야 B가 실행된다면, 적합한 형태는 아니다.
그렇다면 A와 입출력 요청을 독립적인 작업으로 취급해보자.
STCF를 적용했다고 가정했을 때, 아래처럼 동작하며 더 효율적이다.
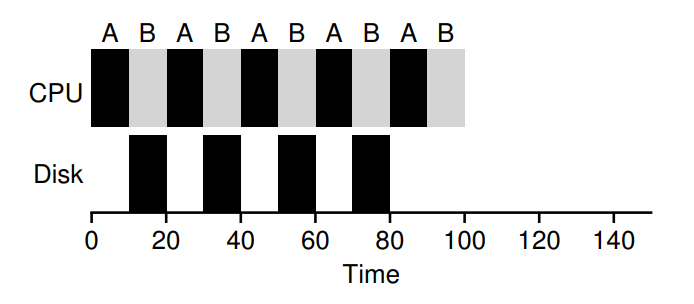
☑️ 미래에 대한 예측
-
마지막 가정인
모든 작업의 길이를 알고 있다에 대해 고민해보자. -
사실 OS는 각 작업의 실행 시간을 거의 모른다.
-
그래서 결론적으로 최근의 과거를 활용해 미래를 예측하는 스케줄러가 등장하게 되었다.
이것을Multi-level Feedback Queue라고 부른다. 이것은 따로 알아보도록 하자.
➡️ 정리
-
CPU 가상화에는 high-level intelligence가 필요하며, 이것은 정책이라고 불리운다.
-
스케줄링은 정책의 대표적인 예시이다.
-
스케줄링은 어떠한 기준(metric)을 두고 작업을 switching 해야 하고, 그 기준에는 처리 시간(turnaround time)과 응답 시간(response time)이 있다.
-
FIFO는 가장 간단한 스케줄링으로, 먼저 전달된 작업부터 처리한다. 그러나 오래 걸리는 작업이 먼저 전달되면 뒤늦게 전달된 작업들이 밀리게 되는 단점이 있다. -
SJF는 짧은 작업부터 처리하는 스케줄링이다. 그러나 짧은 작업이 긴 작업보다 늦게 전달되면 다시 밀리게 되는 단점이 있다. -
STCF(PSJF)는SJF에 선점 기능이 추가된 정책이다.SJF에 비해 처리 시간은 개선되었으나 평균 응답 시간이 좋지 못하다. -
Round Robin은 응답 시간을 개선하기 위해 등장한 정책이다. time slicing이라고도 불리며, time slice의 길이가 짧아질 수록 응답 시간은 향상된다. 그러나 context switching의 오버헤드가 증가하기 때문에 시스템 설계자의 전략적인 접근이 필요하다. -
SJF나STCF는 작업의 실행 시간을 알고 있다는 가정이 있어야 사용 가능하다. 하지만 OS는 작업의 실행 시간을 대부분 알지 못하고, 이로 인해 과거를 통해 미래를 예측하는Multi-level Feedback Queue가 등장하였다.
