
본 글의 내용은 Operating Systems: Three Easy Pieces의 The Abstraction - The Process 챕터를 정리한 것입니다.
☑️ 개요
-
프로세스의 정의는 매우 간단하게 '실행중인 프로그램'이라고 할 수 있다.
-
프로그램은 보조 기억 장치에서 실행될 때까지 대기한다.
-
이러한 프로그램(바이트 코드)을 가져와 실행하는 것이 OS의 역할이다.
-
그리고 이 프로세스라는 가상화 덕분에, 소수의 CPU로 수백 개의 프로세스를 동시에 실행할 수 있다.
☑️ CPU 가상화
-
OS는 한 프로세스를 실행했다가 중지하고 다른 프로세스를 실행하는 방식으로 많은 CPU가 존재하는 것과 같은 착각을 불러일으켜 준다.
-
이러한 기술을 time sharing이라고 부르며, 이렇게 다수의 프로세스를 실행하려면 결국에는 성능이 그것의 자원이 된다.
✅ Time Sharing과 Space Sharing
Time sharing은 OS에서 리소스를 공유하는 데에 사용하는 가장 기본적인 기술이다.
그것은 한 객체가 리소스를 잠시 사용했다가 다른 엔티티가 그것을 이어받아 사용하는 방식으로, 리소스를 여러 객체가 공유할 수 있도록 해준다.
Time sharing과 대응되는 개념은 Space sharing이다. 리소스가 사용하고자 하는 객체들을 위해 나눠지는 것이다. 그 예시로, 하드 디스크를 얘기할 수 있다. 하드 디스크는 블록 단위로 나뉘고, 파일이 블록에 할당되어 공간을 차지하게 된다. -
즉, 보다 많은 프로세스에 공유되면 공유될 수록 CPU는 느려질 수 밖에 없다.
-
결국 CPU 가상화를 잘 구현하려면 저수준 메커니즘(low-level mechanism)과 고수준 지능(high-level intelligence)이 동시에 요구된다. Context Switching을 그 예시로 들 수 있는데, 대표적인 time sharing 메커니즘이며 거의 모든 OS가 사용하고 있다.
-
이런 메커니즘 위에 고수준 지능은 정책이라는 이름으로 존재한다. 정책이란 OS가 결정을 내리기 위한 알고리즘으로, 스케줄링을 대표적인 예시로 들 수 있다. 스케줄링 정책은 과거의 정보, 실행되는 프로그램의 유형, 성능 지표 등을 통해 결정을 내린다.
✅ 정책과 메커니즘의 분리
OS를 설계할 때 정책과 메커니즘을 분리하는 것은 일반적이다.
메커니즘은 시스템을 어떻게 작동시킬 것인가에 집중하는 것이고,
정책은 시스템이 어느 것을 작동시킬 것인가에 집중하는 것이다.
이 둘을 분리해서 설계하는 것은 모듈화라고 할 수 있고,
메커니즘과 정책을 독립적으로 수정할 수 있게 된다.
☑️ 추상화: 프로세스
-
실행 중인 프로그램을 OS가 추상화한 것을 프로세스라고 부른다.
-
어떤 시점이든, 프로세스가 액세스하거나 영향을 미치는 시스템의 여러 부분을 목록화하는 것으로 프로세스는 요약 가능하다.
-
그렇기 때문에 프로세스를 구성하는 요소를 이해하기 위해서는,
프로그램이 실행 중일 때 읽거나 업데이트할 수 있는 기계의 상태(machine state)를 이해해야 한다. -
기계의 부품 중 프로세스에게 가장 중요한 것은 메모리라고 할 수 있을 것이다.
메모리에는 프로세스의 리소스 뿐만 아니라 명령어도 저장된다.
그렇기 때문에 프로세스가 주소를 지정할 수 있는 메모리(주소 공간)는 프로세스의 일부이다. -
또한 프로세스와 관련된 기계 상태를 갖는 HW에는 레지스터도 있다.
수많은 명령어(instruction)가 레지스터를 읽고 갱신하므로, 프로세스의 실행에 중요할 수 밖에 없다.
이 레지스터 중에서도 특별한 몇몇 레지스터가 기계 상태의 일부가 된다. -
대표적인 예시로 어떤 명령어가 실행 중인지를 알려주는 Program Counter(PC),
함수 파라미터, 지역 변수, 리턴 주소를 관리하기 위해 사용되는 Stack Pointer & Frame Pointer가 있다. -
프로그램은 가끔씩 저장 장치에도 접근하므로, 입출력 정보에 프로세스가 접근한 파일 정보가 기록되기도 한다.
☑️ 프로세스 API
프로세스에게도 기능이 필요하고, OS의 프로세스 interface가 가져야 할 기능은 다음과 같다.
1. 생성
- 셀에 명령어를 입력하거나 아이콘을 더블 클릭하면 프로세스가 만들어지는 등의 생성 방법은 OS에게 필수적이다.
2. 파괴
- 생성을 했으면 제거도 필요하다. 대부분의 프로세스가 완료되면 자동 종료되지만, 그렇지 않은 경우 때문에 강제 종료의 기능도 필요하다고 할 수 있다.
3. 대기
- 가끔은 프로세스가 기다려야될 때도 있다. 그런 경우를 위한 기능이다.
4. 이외 기능 제어
- 생성, 파괴 외에도 다른 제어가 필요할 때가 있다. 예를 들어, 대부분의 OS에는 프로세스를 일시 중단 했다가 재시작하는 기능이 구현되어 있다.
5. 상태
- 프로세스의 실행 시간, 상태 정보 등을 파악할 수 있는 기능도 필요하다.
☑️ 더 자세히 알아보기: 프로세스 생성
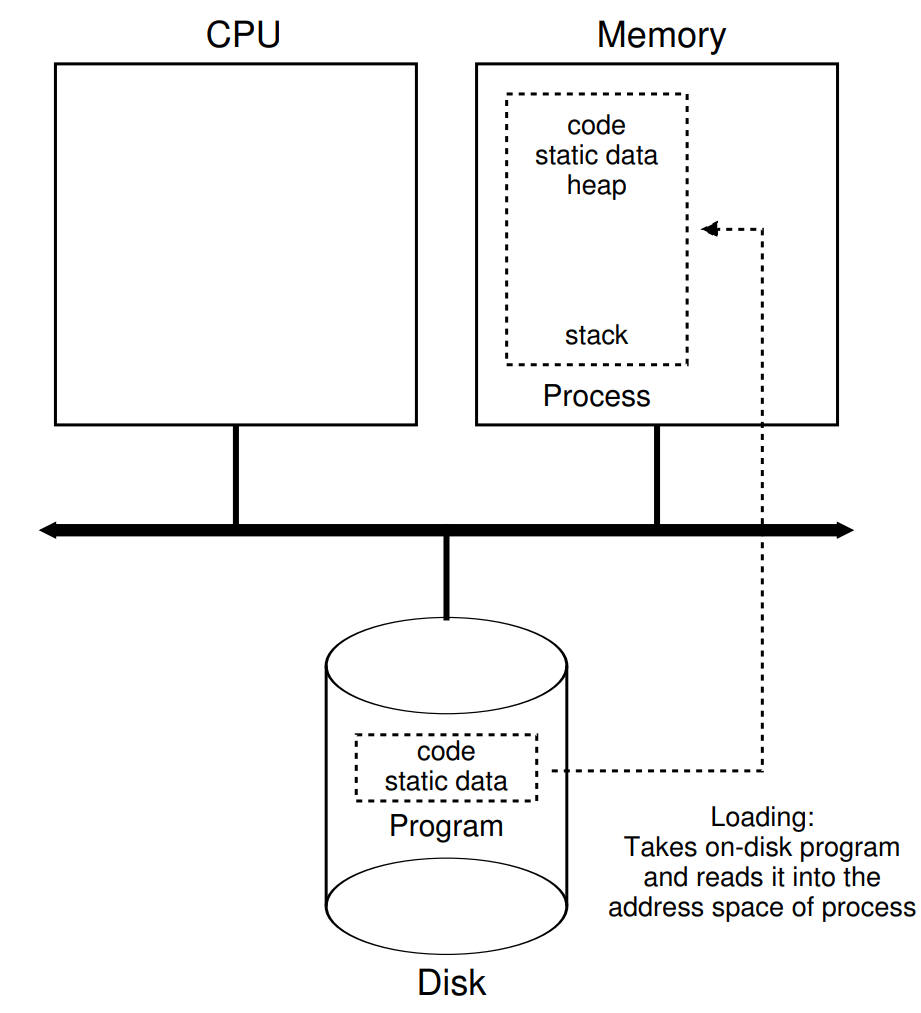
-
그래서 프로그램은 대체 어떻게 프로세스로 변환되는 것인가?
-
OS는 어떻게 프로그램을 시작하고 실행하는 것인가?
-
프로세스 생성 과정은 실제로 어떨까?
1. 메모리에 로드
-
가장 우선적으로 일어나는 것은 코드와 정적 데이터(초기화된 변수)가 주소 공간인 메모리에 로드된다.
-
OS가 디스크에서 프로그램의 바이트 코드를 읽어 메모리의 어딘가에 배치해야 되는 것이다.
-
과거의 OS는 프로그램 실행 전에 모든 것을 로드하는 등, 로드 과정이 무거웠으나
현재의 OS는 필요할 때만 코드나 데이터를 읽어오며 프로세스가 게으르게 작동된다.
(이것에 대한 깊은 이해는 페이징 및 스와핑 메커니즘을 통해 가능하다.)
2. 런타임 스택(혹은 그냥 스택)을 위한 메모리 할당
-
로컬 변수, 함수 파라미터, 리턴 주소를 관리하기 위해 메모리에 스택을 위한 공간을 할당해야 한다.
-
또한 OS는
main()함수에 사용될argc혹은argv매개변수를 채우기도 한다.
3. 힙을 위한 메모리 할당
-
동적 할당 데이터를 위해 사용되는 힙 공간을 위해 OS가 메모리를 할당하기도 한다.
-
연결 리스트, 해시 테이블 등의 자료구조를 위해서도 힙이 필요하다.
-
힙은 작은 공간을 차지하다가 점점 더 많은 메모리를 할당받을 수 있다.
4. 입출력 초기화 작업
-
UNIX 기반 시스템의 각 프로세스는 기본적으로 세 개의 file descriptor를 갖는다.
(input, output, error를 위한) -
이 file descriptor들 덕분에 파일 입출력이 쉬워질 수 있다.
준비 완료
-
위와 같은 과정들을 거치며, OS는 비로소 프로그램을 실행할 준비를 마쳤다.
-
이제 프로그램의
main()함수를 실행하면 되는 것이고,main()루틴으로 이동하는 것으로
OS는 CPU에게 새롭게 생성된 프로세스의 제어권을 넘긴다. 그리고 프로그램은 실행된다.
☑️ 프로세스 상태
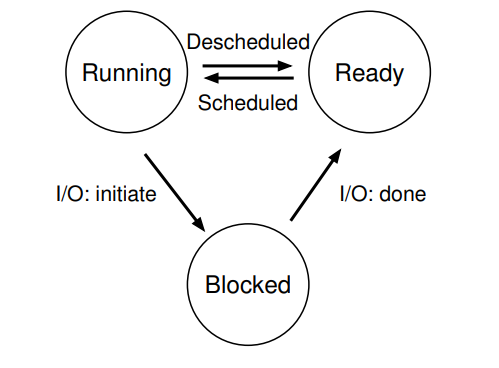
- 프로세스는 다음과 같은 3개의 상태를 가질 수 있다.
실행(Running)
- CPU가 프로세스(명령어)를 실행중인 상태
준비(Ready)
- 실행할 준비가 됐고, 아직 OS에게 실행되지는 않는 상태
차단(Blocked)
- 특정 작업을 수행해서, 다른 이벤트가 발생되기까지 실행 준비 상태가 되지 않은 상태
- 예시로 입출력 요청을 시작하면 프로세스는 차단된다.
상태 변화

-
준비 -> 실행 상태 = 프로세스가 스케줄링 됨
-
실행 -> 준비 상태 = 프로세스 스케줄 취소
-
차단 -> 준비 상태 = 입출력 요청(예시)으로 일시적으로 차단되었다가, 준비 상태로 복귀함
☑️ 프로세스 데이터 구조 (Data Structures)
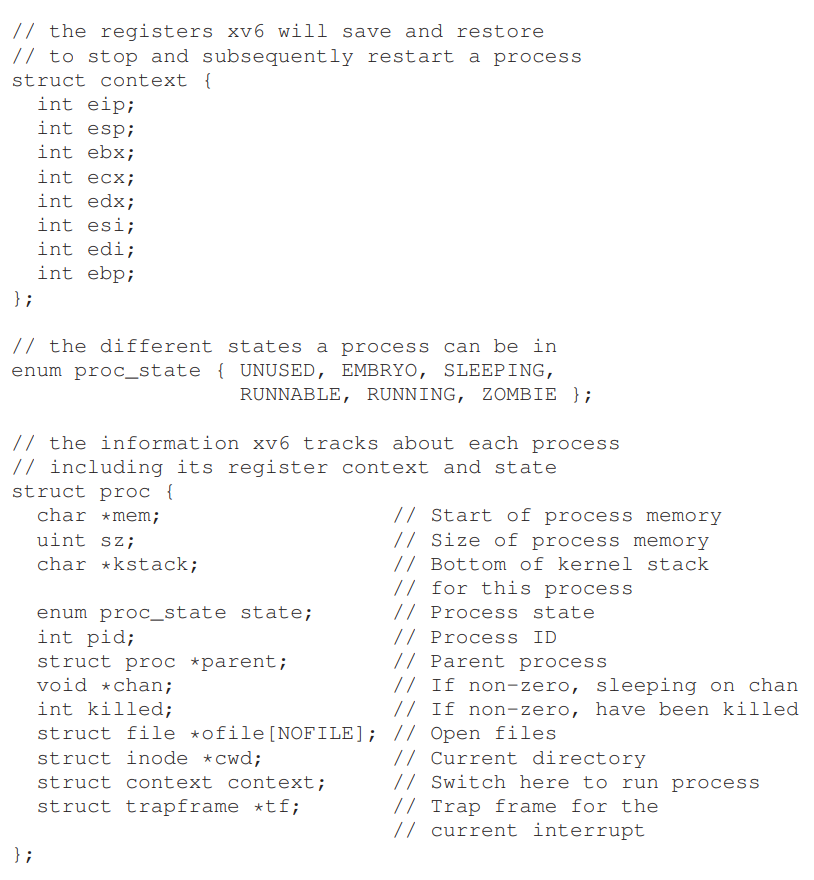
-
프로세스의 상태를 추적하기 위해 OS는 모든 준비 상태의 프로세스 목록, 그리고 실행 상태 프로세스를 추적하기 위한 추가 정보를 보관해야 한다.
-
register context는 정지된 프로세스를 위해 그에 대응되는 레지스터의 정보를 저장한다.
(Context switching에서 중요하게 쓰이는 정보) -
사실 프로세스는 실행/준비/차단 이외에도 몇가지 다른 상태에 있을 수 있다.
-
초기 상태(initial): 생성된 프로세스의 첫 상태
-
최종 상태(final): 프로세스가 종료됐으나 정리되지 않은 상태
- 최종 상태 프로세스가 리턴한 코드를 확인하여 방금 종료된 프로세스가 제대로 실행됐는지를 확인할 수 있다.
-
주로 부모 프로세스가 자식 프로세스에 관련된 데이터 구조를 정리하는 것을 OS에게 요청하기 위해 활용한다.
-
✅ Data Structure - 프로세스 리스트
프로세스 목록은 OS에 존재하는 수많은 자료 구조 중 하나다.
가장 간단한 구조지만, 멀티 프로세싱이 가능한 모든 OS에는 이 구조가 존재한다.
그리고 프로세스에 대한 정보를 저장하는 개별 구조를 PCB(Process Control Block)라고 부른다.
➡️ 정리
-
프로세스란, 간단히 말하면 실행중인 프로그램이다.
-
CPU 가상화에는 메커니즘과 정책이 필요하다.
-
프로그램은 실행 중에 다양한 기계의 상태를 읽고 쓴다. 그 중 메모리와 레지스터는 프로그램과 밀접한 관계가 있다.
-
프로세스는 생성, 파괴, 대기 등의 API를 갖는다.
-
프로세스가 생성될 때는 코드와 정적 데이터가 로드되고, 스택/힙을 위한 메모리를 할당받은 뒤 입출력 초기화 작업을 거쳐 OS에게 활용된 준비를 마친다.
-
프로세스는 초기, 실행, 준비, 차단, 최종 상태를 가질 수 있다.
-
OS가 수많은 프로세스를 관리하기 위해, 프로세스의 정보를 보관하는 데이터 구조가 존재한다.
