🔍 배운 것
흐름제어 / 트랜잭션 / DB동시성
쿼리의 실행 흐름을 제어하는 흐름제어
- IF / IFNULL / CASE / 저장 프로시저
하나의 작업 단위로 구성되는 트랜잭션
- 두 쿼리가 반드시 같이 성공하거나 같이 실패하는 경우 사용하는 집합
- commit > 확정 / rollback > 둘 중 하나라도 실패한다면 모두 실패 처리
- 트랜잭션이 신뢰성과 일관성을 유지하기 위해 지켜야하는 ACID 속성
트랜잭션이 동시에 실행 됐을 때, 발생하는 문제 DB 동시성
- DB 동시성 문제를 해결하기 위한 DB 격리 수준 존재.
- 격리 수준을 높이면 정확도는 높일🔺 수 있으나 성능 저하🔻.
JOIN / GROUP BY / INDEX
여러 테이블에서 가져온 레코드 조합을 하나의 테이블이나 집합으로 표현하는 JOIN
INNER JOIN: a INNER JOIN b.SELECT 열_이름들 FROM 첫번째_테이블 INNER JOIN 두번째_테이블 ON 첫번째_테이블.공통_열 = 두번째_테이블.공통_열;SELECT * FROM tableA AS a INNER JOIN tableB AS b ON a.ID = b.a_id;
ON 뒤에는 두 테이블의 연관된 열을 연결, 공통된 값으로 테이블을 결합함.
a와 b 테이블 위치가 바뀌어도 결과는 동일.OUTER JOIN: a LEFT OUTER JOIN b
SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id
tableA 의 모든 컬럼 + tableB 의 모든 컬럼 중
LEFT에 위치한 A테이블 데이터 row는 모두 출력, B는 ON 조건에 맞는 데이터만 출력.
INNER 와 다르게 a, b 위치가 바뀌면 결과도 달라짐 !
JOIN은 결과를 옆으로 붙인다면? UNION은 하단으로!UNION
SELECT 컬럼1, 컬럼2 FROM table1 UNION SELECT 컬럼1, 컬럼2 FROM table2;
각각의 SELECT 문으로 선택된 필드의 개수와 타입은 모두 일치해야 한다.
중복되는 레코드는 디폴트로 제거, 모두 출력하고 싶다면 UNION ALL
지정된 열의 값이 동일한 행들을 하나의 그룹으로 묶은 결과 집합 GROUP BY
주로 그룹 데이터의 값을 집계하기 위해서 사용.
SELECT DATE_FORMAT(datetime, '%H') as HOUR, COUNT(*) FROM animal_outs
WHERE DATE_FORMAT(datetime, '%H:%i')
BETWEEN '09:00' AND '19:59' GROUP BY HOUR ORDER BY HOUR;
-- 앞에서 HOUR 로 정의 > GROUP BY 에서 HOUR 로 사용 COUNT, AVG, MIN, MAX, SUM
그룹화 한 후의 데이터에 대한 조건 설정은 HAVING 사용.
JOIN + ON / GROUP BY + HAVING
색인과 목차처럼 데이터 검색 속도를 향상시켜주는 INDEX
- 인덱스가 없다면 하나하나 확인해야하는 데이터를 분류된 값으로 조회해 작업 단축.
- PK, FK, UNIQUE 제약 조건 추가 시 해당 컬럼에 대해 Index 자동 생성됨.
- 자주 추가/수정되는 작업보다는 자주 조회되는 데이터에 활용.
Data modeling / 정규화 / DB DUMP
구축할 DB 구조를 약속된 표기법에 따라 표현하고 설계하는 Data Modeling
- 개념적, 논리적, 물리적 모델링 3단계 !
- 데이터베이스 구현을 위해 꼭 필요한 단계.
복습 또 복습 . . 실습 시간을 가졌는데 5시간 동안 완성하지 못했다. 복복습 가보자고.
b의 값에 의해 a가 결정됨을 의미하는 함수적 종속성 정규화
데이터베이스의 구조와 데이터를 SQL 형식으로 추출하여 복원하는 DB DUMP
사용자 관리 / VIEW / PROCEDURE
사용자 생성, 조회, 권한 부여 사용자 관리
실제 데이터를 저장하지 않고 참조할 수 있는 VIEW
CREATE VIEW author_for_view AS SELECT 컬럼1, 컬럼2, ... FROM 테이블명;
데이터베이스에 저장하여 실행할 수 있는 SQL문 집합 저장 프로시저
- SQL문을 미리 컴파일하여 저장, 여러번 사용할 수 있어 서버의 부하를 줄이고 성능을 향상시킴.
- 복잡한 조건문, 반복문 등 저장 프로시저는 절차적 프로그래밍 언어로써 사용.
💡 느낀 점
분명 강의를 들을 때는 다 이해했는데, 수업 실습 시간에 쿼리도 작성해보았는데!
막상 새하얀 백지에 '~~~한 쿼리문을 작성해보세요' 하면 아무것도 떠오르지 않았다.
막힌 부분에서 필기 노트를 찾아보자니, 어디에 뭐 썼더라..? 언제 뭐 배웠더라..?
그럴 때 ! 복습 블로그를 썼던 게 아주 많은 도움이 됐다.
내가 지금 필요한 정보들은 내 블로그에 담겨있다보니, 내 블로그에서 검색하면 내가 찾던 정보들이 모두 정리되어 있는 것이다. 복습 차원에서 매일매일 써 온 글들이 나에게 다시 큰 자산이 되어 기뻤다.
하지만 복습을 진행했음에도 부족한 부분도 있었다.
배운 개념 복습에 더해 직접 혼자 다시 실습해보기도 했는데 (궁금하다면 여기🍀)
금일(5월 23일) 진행한 수업에서 약 4-5시간 정도 1단계부터 3단계까지 설계하고, 직접 프로시저와 쿼리문을 작성해보는 실습시간을 가졌는데 끝내 완성하지 못한 채 숙제로 가지고 돌아왔다.
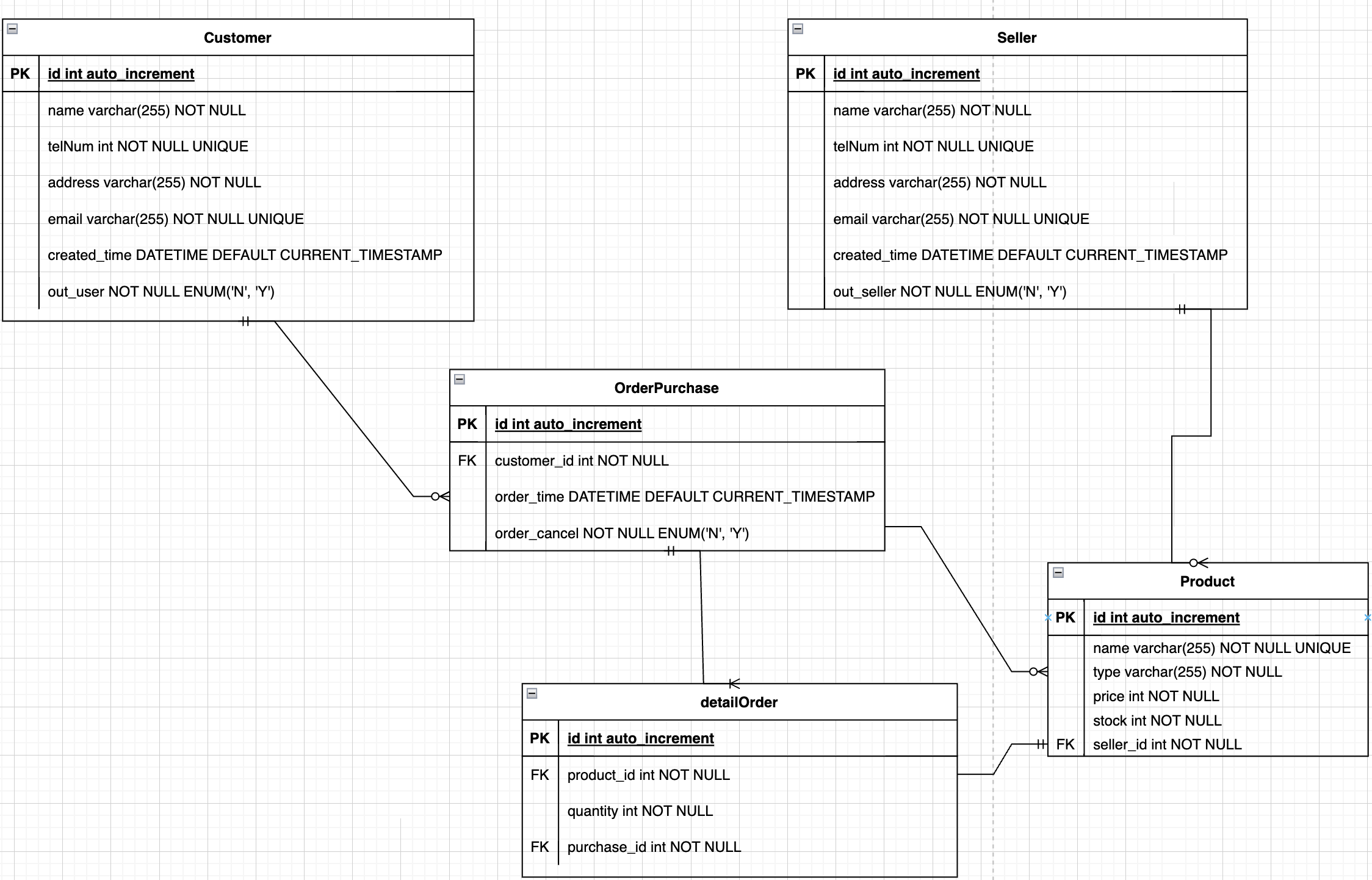
내가 배운 것 그 이상을 만들어내려고 했던 것도 있었고, 제대로 설계하지 못한 부분도 있었다.
너무 너무 아쉬웠다. 강사님의 디테일한 조언을 받고 나니 더 아쉬웠다 !
다 이해했는데, 시간이 조금만 더 있으면 완성할 수 있을 것 같은데..🥲(5시간이나 주셨지만)
전공자는 3시간이 걸린다면 비전공자 노베이스인 나는 시간이 곱절은 더 걸리는 것 같다.
이 아쉬운 마음을 꼭 꼭 눌러 담아 공부에 대한 열정으로 바꾸어 보려 한다.
복습을 진행해도 부족한 부분이 있다면, 더 공부해보면 된다 !
내 짝꿍도 전공자지만 처음엔 자신도 어려웠다며, DB에만 3일을 부딪혀보니까 좀 좋아졌다고 위로해주었다.
지금은 진짜 모르는 거 물어보면 답변해주는 나에겐 척척박사 짝꿍이라 위로가 진짜 위로로 와닿았다!
DB 뿐만 아니라, 앞으로 남은 산들이 높고 높지만 ⛰️
일주일도 남지 않은 데이터베이스 팀 프로젝트가 가장 코 앞의 산이라 가장 높게 느껴진달까..
팀원들과 함께 올라 정복할 수 있도록 최선을 다 해야겠다는 걸 다시 한 번 다짐하는 한 주였다.
🏊🏻♀️ 발전 방향
2주차만에 드디어 ! 스터디에 참여하게 되었다 👏🏻
아직 조금 부족한 실력 때문에, 다른 스터디원들에게 폐를 끼칠까 함부로 스터디에 참여하지 않았다.
점심시간에 솔직하게 터놓았는데 기초부터 시작하려는 분들이 계셔서 함께 시작하게 되었다..!
우리 기수분들은 정말,, 모두 다 친절하고 아낌없이 주는 나무들인데
찐 나무 중 나무🌲인 분들과 함께 자료구조, 알고리즘 문제부터 수업 복습까지 함께 공부하게 되었다 !
못 하는 걸 못 한다고 말할 수 있는 용기를 주는 팀원들과 함께하게 되었으니,
모른다고 말 할 게 없는 그 순간까지 더 잘 나아갈 수 있을 것 같다.
진짜 진짜 스터디 팀원들 너무 든든하다. 최고의 강사님과 최고의 팀원들을 만난 것 같다🥹
우선 현재까지의 커리큘럼 중 이해도가 가장 부족한 부분은 모델링 부분인 것 같다.
선을 그리고 그리다 보니 이 선이 저 선 같고, 저 선이 이 선 같고..
한 번 더 정리해본 뒤 월요일 스터디원들과 함께 더블 체크를 진행해 볼 예정이다.
프로시저나 쿼리 작성 시 오탈자나 작은 실수들로 큰 에러를 낳는 경우도 빈번하다.
침착하게 작성하고 살펴보는 버릇을 길러보려 한다!
지치지 않도록 중간 중간 취미 활동과 운동도 꼭 잘 챙겨주자 !
