첨부된 이미지는 모두 SW캠프 수업 자료입니다.
🥨 JOIN
- 여러 테이블에서 가져온 레코드를 조합, 하나의 테이블이나 집합으로 결과 표현
- 크게는
INNER JOIN/OUTER JOIN으로 구분- INNER JOIN : a INNER JOIN b
- a, b 에 지정된 조건에 맞는 레코드만을 반환. 양쪽 테이블에 모두 해당하는 값이 있어야 결과에 포함
- 가장 일반적인 형태 !
- OUTER JOIN : a LEFT OUTER JOIN b
- a 테이블을 기준으로 모든 레코드와 그에 JOIN된 다른 테이블 b의 일치하는 값을 반환.
- 왼쪽 기준 > LEFT, 오른쪽 기준 > RIGHT. LEFT가 일반적이며 OUTER는 대부분 생략함.
- INNER JOIN : a INNER JOIN b
✏️ INNER JOIN
SELECT 열_이름들
FROM 첫번째_테이블
INNER JOIN 두번째_테이블 ON 첫번째_테이블.공통_열 = 두번째_테이블.공통_열;SELECT * FROM tableA AS a INNER JOIN tableB AS b ON a.ID = b.a_id;- ON 뒤에는 두 테이블의 관련된 열을 연결하여 공통된 값을 가지는 행만 선택하여 테이블을 결합함.
=> 이를 통해 두 테이블을 결합, 원하는 값을 얻을 수 있게 됨.
- ON 뒤에는 두 테이블의 관련된 열을 연결하여 공통된 값을 가지는 행만 선택하여 테이블을 결합함.
- 작성 순서 상관 X. a와 b의 위치가 뒤바껴도 결과는 동일.
출력 결과 : tableA의 모든 컬럼 + tableB의 모든 컬럼 중 ON 조건을 만족하는 row만 출력.
✏️ LEFT OUTER JOIN

SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id
1) left 이전은 다 가져온다! -> tableA 다 가져옴.
2) tableA 에는 있는데 B 에는 없다면? -> null 로 채워짐.- INNER 와 다르게 a, b 위치가 바뀌면 결과도 달라짐.
출력 결과 : tableA의 모든 컬럼 + tableB의 모든 컬럼 중
A 테이블 데이터 row는 모두 출력, B 테이블 데이터는 ON 조건에 맞는 데이터만 출력
ON 조건에 맞지 않는 B 데이터는 null로 출력
ORDER BY 시에 B 데이터를 기준으로 하게 되면 null 이 최상단에 위치됨에 주의.
🧱 UNION
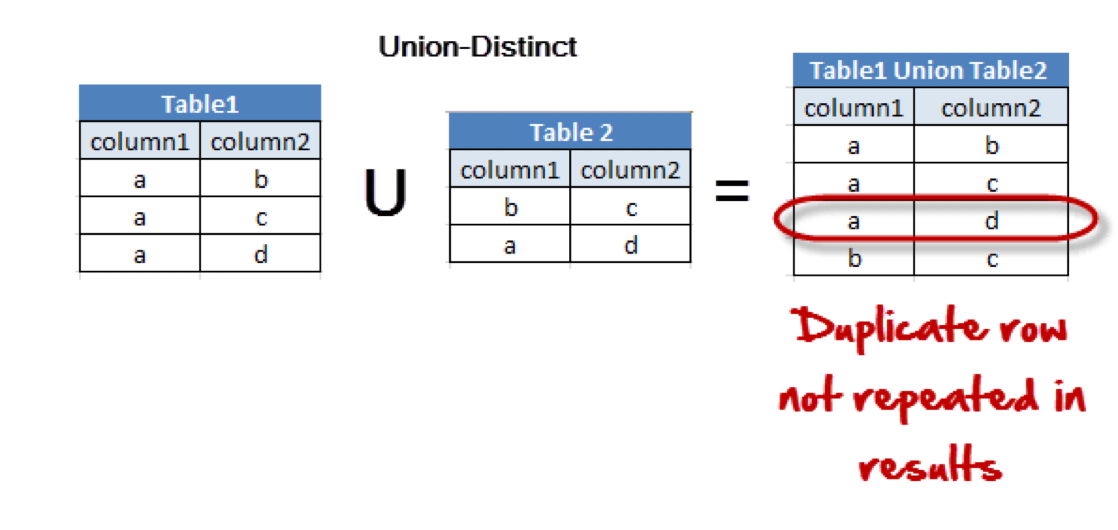
- 여러 테이블에서 가져온 레코드를 조합, 하나의 테이블이나 집합으로 결과 표현
join은 옆으로 붙인다면union은 아래로 !- 각각의 SELECT 문으로 선택된 필드의 개수와 타입은 모두 일치해야 함.
- DISTINCT 를 따로 명시하지 않아도 중복되는 레코드를 제거.
- 중복되는 레코드까지 모두 출력하고 싶다면
UNION ALL
- 중복되는 레코드까지 모두 출력하고 싶다면
-- union : 중복을 제회한 두 테이블의 select 를 결합.
-- 컬럼의 개수와 타입이 같아야함에 유의
-- union all : 중복 포함
select 컬럼1, 컬럼2 from table1 union select 컬럼1, 컬럼2 from table2;
-- author 테이블의 name, email / post 테이블의 title, contents 를 union
select name, email from author union select title, contents from post;📔 서브 쿼리
- 다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미.
- 서브쿼리는 반드시 괄호 (()) 로 감싸져 있어야 함.
- 대부분의 서브쿼리는 JOIN 으로 대체 가능 / JOIN을 쓰는 것이 성능이 더 좋음.
- 단, 매우 복잡한 쿼리는 JOIN 으로 대체하는 것이 불가능
1) SELECT 절: select 절 안에 서브쿼리 → select 문 안에 또 다른 select 문.
2) FROM 절: from 절 안에 서브쿼리 → from 안에 또 다른 select 문
3) WHERE 절: where 절 안에 서브쿼리 : where 문 안에 또 다른 select 문
-- 서브 쿼리
-- select 절 안에 서브쿼리 : select 문 안에 또 다른 select 문.
-- author email과 해당 author가 쓴 글의 개수를 출력
select email, (select count(*) from post p where p.author_id = a.id) as count from author a;
-- from 절 안에 서브쿼리 : from 안에 또 다른 select 문
select a.name from (select * from author) as a;
-- where 절 안에 서브쿼리 : where 문 안에 또 다른 select 문
select a.* from author a inner join post p on a.id = p.author_id;
-- 위 쿼리를 where 절로 변환
select * from author where id in (select author_id from post);🖇️ GROUP BY
- 지정된 열의 값이 동일한 행들을 하나의 그룹으로 묶은 결과 집합.
SELECT 컬럼명 FROM 테이블명 GROUP BY 컬럼명- SELECT 구문에서 정의한 alias를 group by 의 컬럼명으로 사용 가능.
SELECT DATE_FORMAT(datetime, '%H') as HOUR, COUNT(*) FROM animal_outs
WHERE DATE_FORMAT(datetime, '%H:%i')
BETWEEN '09:00' AND '19:59' GROUP BY HOUR ORDER BY HOUR;
-- 앞에서 HOUR 로 정의 > GROUP BY 에서 HOUR 로 사용-
사용 목적
- 주로 그룹 데이터의 값을 집계하기 위해 사용.
- GROUP BY 절에 포함되지 않은 열을 SELECT 절에서 집계 함수 없이 단독 사용 불가.
-
집계함수
- COUNT() : 행의 개수를 세어줌
- AVG() : 행 안에 있는 값의 평균을 내어줌
- MIN() : 행 안에 있는 값의 최솟값을 반환해줌
- MAX() : 행 안에 있는 값의 최댓값을 반환해줌
- SUM() : 행 안에 있는 값의 합을 내어줌
-- 집계 함수
SELECT COUNT (*) FROM author; -- (= SELECT COUNT(ID) FROM AUTHOR;) >> 행의 갯수를 세는 거라 ID 갯수와 동일함.
SELECT SUM(price) FROM post;
SELECT AVG(price) FROM post; -- 반올림하면 ROUND(AVG(PRICE), 소수점자리) >> SELECT ROUND(AVG(price),0) FROM post;-
HAVING
- GROUP BY 를 사용해 그룹화된 후의 데이터에 대한 조건을 설정.
- WHERE 은 데이터를 그룹화하기 전 개별 레코드에 대한 조건을 설정한다는 점에서 차이가 있음.
- 무조건 ! GROUP BY와 함께 쓰임.
💡 ON : JOIN 조건 / WHERE : 조건(독립) / HAVING : GROUP BY 통계에 대한 조건
-
쿼리의 진행 순서
SELECT > JOIN > ON > WHERE > GROUP > HAVING > ORDER > LIMIT
-
다중열 GROUP BY
-- 다중열 group by
SELECT author_id, title, count(title) FROM post GROUP BY author_id, title;
-- author_id 로 묶었던 그룹을 title로 한 번 더 묶어줌 >> 앞에서 title도 뽑아내기 OK📋 INDEX
-
색인과 목차처럼 데이터 검색 속도를 향상시키는데 사용.
-
일반적으로 인덱스는 B-tree의 자료구조를 가지고, 이는 이진 트리를 확장한 형태로, 한 노드가 두 개 이상의 자식을 가질 수 있는 자료구조.
- 이진트리는 최대 2개의 자식 노드를 가지는 구조. 모두 2개의 자식노드만을 가진 이진트리를 완전이진트리라 부른다.
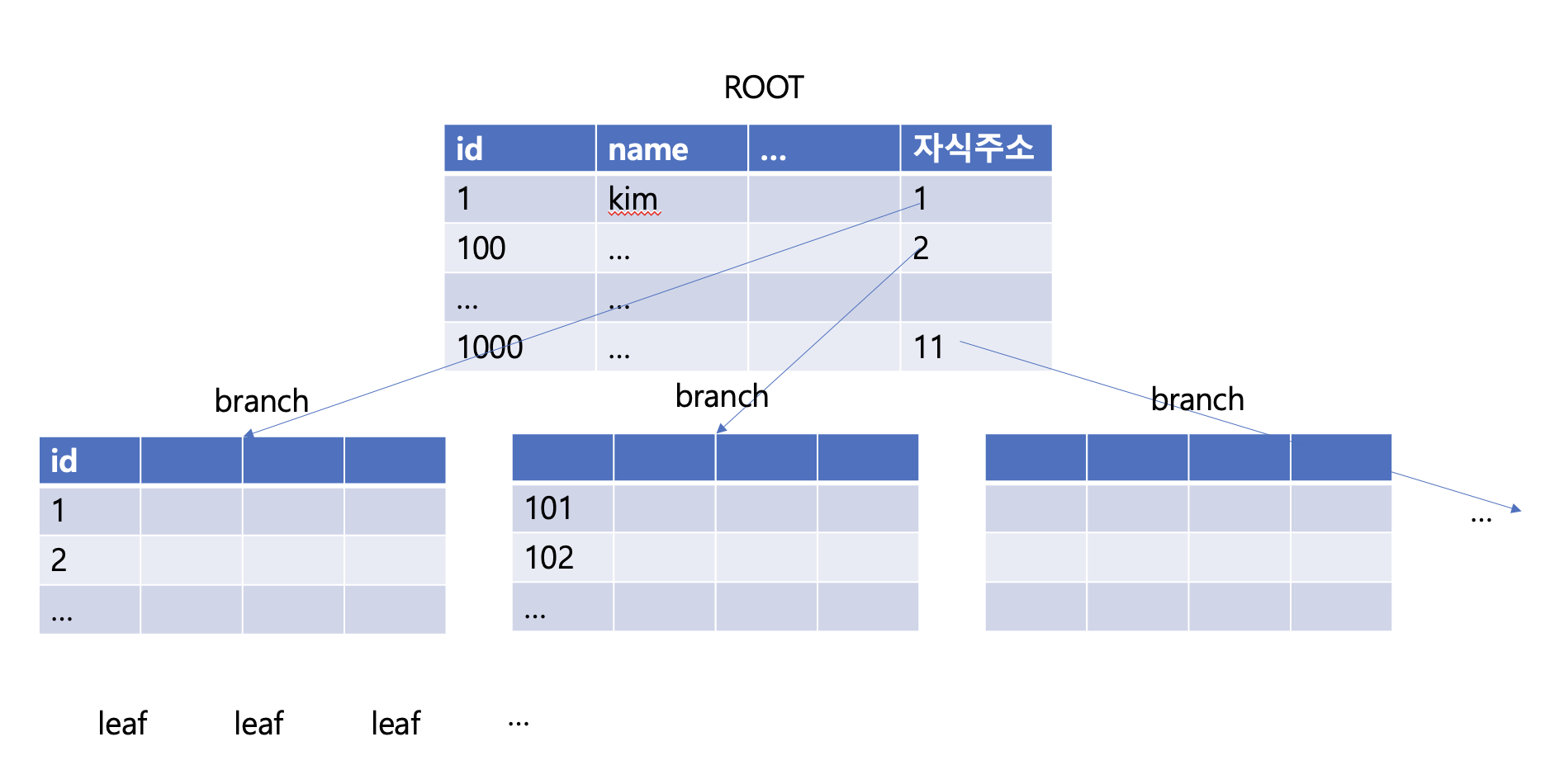
▶id = 897번째의 데이터를 조회한다면 root에서 8번, 그 다음 branch에서 9번, 그 다음 leaf에서 7번, 24번만에 검색 완료!
만약 인덱스가 없다면? 897번 동안 하나 하나 확인하게 됨. -
인덱스 생성 : PK, FK, UNIQUE 제약 조건 추가 시 해당 컬럼에 대해 index 자동 생성됨.
-
단일 컬럼 index :
CREATE INDEX index_name ON 테이블명(컬럼명); -
복합(다중 컬럼) 인덱스 생성 :
CREATE INDEX index_name ON 테이블명(컬럼1, 컬럼2);- 컬럼1을 기준으로 정렬하여 index로 저장하고, 컬럼1이 중복된다면 컬럼2를 기준으로 정렬하여 index로 저장. ORDER BY 와 똑같이!
-- 인덱스 없이 조회 -> 0.178s
SELECT * FROM author WHERE email = 'test99999@naver.com';
-- 인덱스 생성
CREATE index email_index on author(email);
-- 후 다시 조회하면 -> 0.002s 시간이 감소함!- 인덱스를 추가하면 저장 공간 사용 발생으로 데이터 삽입, 업데이트, 삭제 등 작업이 느려짐에 유의해야 함.
- 자주 추가되고 수정되는 작업보다는 자주 조회되는 데이터에 활용하면 좋다.
📌 today
오늘은 정말 정말 방대한 양의 개념을 배우고 실습하였다 !
중간 점검으로 강사님께서 응용이 어렵다는 나에게
응용은 연습하면 된다 ! 수업이 이해가 됐다면 당장은 그걸로 OK !
이런 말씀을 해주셨다.. 수업 중 여기 저기서 여러 방안들을 던지고,
가끔 나오는 질문들을 보면 (내 기준에서는) 엄청난 수준들이라 나만 뒤쳐진 것 같고, 여러가지 걱정들이 쌓여갔었는데 강사님이 말 한 마디로 큰 힘을 실어주셨다 !🍀 (과대해석이어도 원영적 사고로 받아들이기)
-- 실습 : 두 건 이상의 글을 쓴 사람의 id와 횟수 구하기.
-- 나이는 25세 이상인 사람만 통계에 사용, 가장 나이 많은 사람 한 명의 통계만 출력하시오.
SELECT a.id, COUNT(a.id) as count FROM post p INNER JOIN author a
ON a.id = p.author_id WHERE a.age >= 25 GROUP BY a.id HAVING count >=2 ORDER BY max(a.age) DESC LIMIT 1;
-- 한 그룹에는 다 같은 나이가 잡힐 거니까 max를 쓸 필요가 없다 >> a.age 를 DESC 로 정렬하면 당연히 max 가 최상단일테니까..특히나 오늘은 여기서 다들 MAX 가 빠져도 되는데 왜 써야하는가? 에 대한 작은 토론이 열렸었는데, 나 혼자만.. 왜 MAX 가 빠져도 똑같다는거지..? 하고 이해가 안 가는데 진짜 도저히! 질문하기 너무너무 창피한 수준의 의문이어서 세미 개발자 / 개발자 연습생 친구에게 물어보니 보자마자 "DESC 이니까 당연히 큰 값이 맨 위지" 라고 답변해줬다..
나도 한 번에 캐치할 수 있는 사람이 되고 싶다..
얼만큼 노력하면 되니..? 어디까지 왔니 개발자 아영아...... 기다릴게....
