지난 시간에는...
지난 글에서는 웹사이트 한 페이지에서 정보를 추출하고 저장하는 기본적인 웹 크롤링 실습을 해봤다. 하지만 실제 데이터 수집은 한 페이지만으로는 부족하다.
이번 글에서는 여러 페이지에 걸친 데이터를 자동으로 수집하는 방법, 즉 Pagination(페이지네이션) 처리 방법을 다뤄보도록 하겠다.
개념
웹사이트는 보통 한 페이지에 모든 데이터를 다 보여주지 않는다. 뉴스 기사, 블로그 글, 제품 목록, 채용공고 등은 여러 페이지에 나눠서 제공된다.
단어에서 유추할 수 있듯 페이지를 넘기며 데이터를 반복해서 수집하는 작업을 Pagination이라고 한다.
✅ 예시 구조
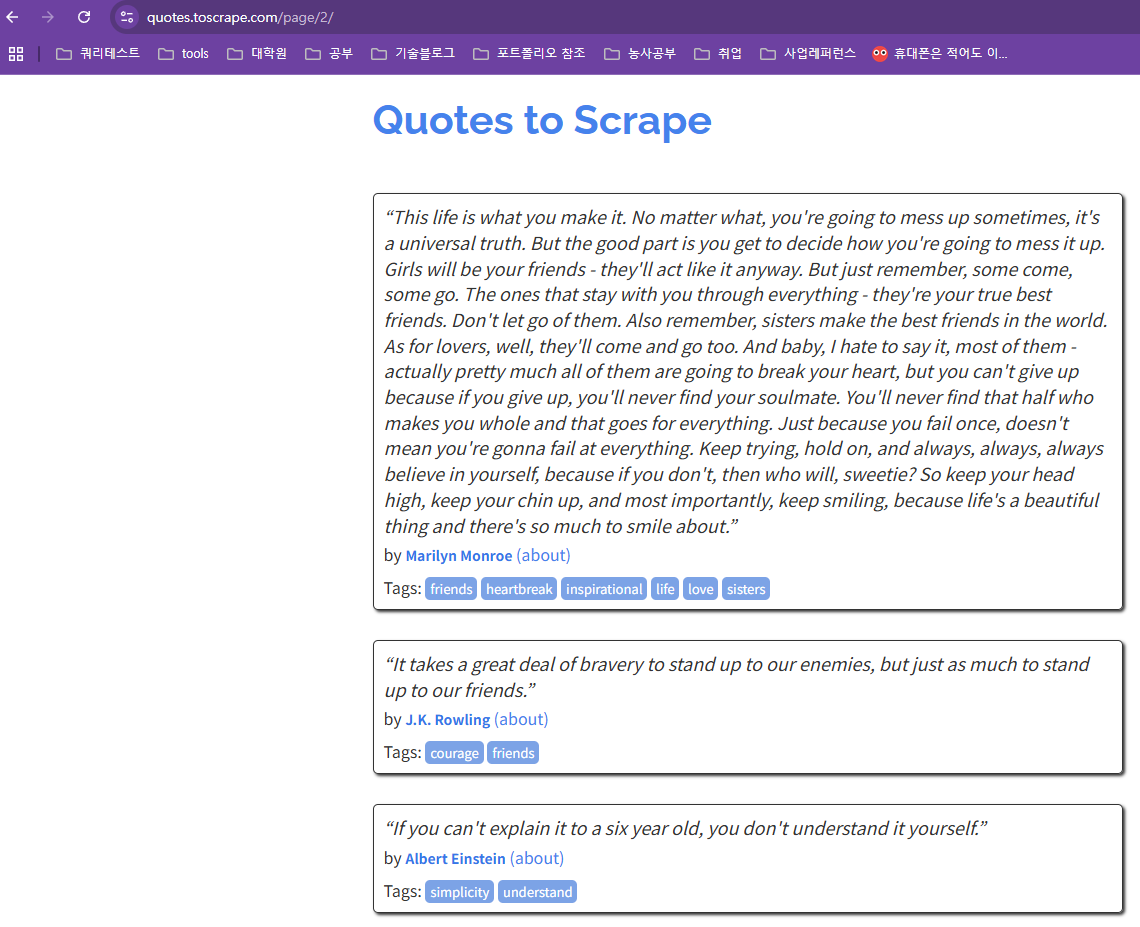
https://quotes.toscrape.com/page/1/
https://quotes.toscrape.com/page/2/
https://quotes.toscrape.com/page/3/이렇게 페이지 번호만 바뀌는 URL 패턴이라면 크롤링이 아주 쉬워진다.
-
오늘 우리가 볼 홈페이지의 URL을 보면 page의 하위 디렉토리에 넘버링을 하여 페이지 구분이 된 것을 볼 수 있다.
-
홈페이지에서는 next 버튼을 누르면 다음페이지, Previous를 누르면 이전 페이지로 이동하는 것을 확인했고, 그에 따라 넘버링이 된 것을 확인했다.
-
우리는 유추된 이 패턴을 갖고 pagination을 해보도록 하자.
🎯 실습 목표
- https://quotes.toscrape.com/ 사이트에서 1페이지부터 마지막 페이지까지 명언 + 작가 정보를 자동으로 수집
- 수집한 데이터는 CSV 파일로 저장
✔ 페이지 구조
🧪 실습 코드 – 페이지 자동 순회
import requests
from bs4 import BeautifulSoup
import pandas as pd
base_url = "https://quotes.toscrape.com/page/{}/"
page = 1
all_data = []
while True:
url = base_url.format(page)
print(f"📥 수집 중: {url}")
res = requests.get(url)
if res.status_code != 200:
print(f"❌ 페이지 {page}는 존재하지 않음. 수집 종료.")
break
soup = BeautifulSoup(res.text, "html.parser")
quotes = soup.select(".quote")
if not quotes:
print("✅ 더 이상 수집할 quote 없음. 종료합니다.")
break
for q in quotes:
text = q.select_one(".text").get_text(strip=True)
author = q.select_one(".author").get_text(strip=True)
all_data.append({"quote": text, "author": author})
page += 1 # 다음 페이지로 이동
위 코드를 실행시키면 아래와 같은 출력 결과가 나온다. 필자는 Google Colab을 활용했다.

📄 CSV 파일로 저장
df = pd.DataFrame(all_data)
df.to_csv("quotes_all_pages.csv", index=False, encoding="utf-8-sig")
print("✅ quotes_all_pages.csv 파일로 저장 완료!")
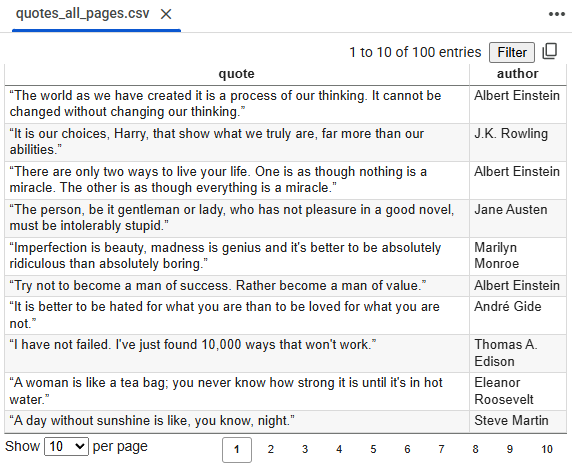
위 코드를 실행시키면 아래와 같은 출력 결과가 나온다. 홈페이지에서 보이는대로 명언, 작가의 정보가 수집되었다.
🧠 핵심 개념 요약
🤔 우리는 오늘 뭘했나?
우리는 오늘 quotes.toscrape.com이라는 웹사이트에서 여러 페이지에 걸친 명언 데이터를 자동으로 수집하고 저장하는 작업을 수행했다.
그 과정을 따라가면서 어떤 개념을 배웠는지 하나씩 짚어보자.
1. 웹은 한 번에 모든 데이터를 보여주지 않는다.
-
우리가 크롤링한 사이트는 1페이지에 10개의 명언만 보여줬다.
-
하지만 그 안에는 더 많은 데이터가 있었고, 다른 페이지를 통해 접근해야 했다.
📌 이 개념이 말하는 것 👉 대부분의 웹사이트는 데이터를 여러 페이지에 나눠서 제공한다. 👉 원하는 모든 데이터를 얻으려면 페이지 이동이 필수다.
2. 페이지를 자동으로 넘기는 흐름을 만들 수 있다.
-
URL 패턴이 /page/1/, /page/2/처럼 규칙적이라는 걸 알았고,
-
page += 1로 페이지를 하나씩 바꿔가며 데이터를 수집했다.
📌 이 개념이 말하는 것 👉 URL이 일정한 규칙을 가진다면, 코드를 통해 반복적으로 생성할 수 있다. 👉 이것이 Pagination 자동화의 핵심이다.
3. 더 이상 수집할 게 없을 때 ‘스스로 종료’하는 로직이 필요하다
-
페이지가 계속 존재하는 건 아니었다.
-
우리가 11 페이지까지 갔을 땐, 더 이상 quote가 존재하지 않았고,
그걸 보고 break로 반복문을 멈췄다.📌 이 개념이 말하는 것 👉 URL이 일정한 규칙을 가진다면, 코드를 통해 반복적으로 생성할 수 있다. 👉 이것이 Pagination 자동화의 핵심이다.
4. 수집한 데이터를 저장할 수 있어야 ‘쓸모’가 생긴다
-
우리는 추출한 명언과 작가 데이터를 pandas로 정리해서 quotes.csv로 저장했다.
-
이 CSV 파일은 나중에 분석, 시각화, 데이터베이스 적재 등 다양하게 활용할 수 있다.
📌 이 개념이 말하는 것 👉 크롤링의 목적은 단순 출력이 아니라, 가공 가능한 형태로 저장하는 것이다. 👉 그래서 pandas는 크롤링과 데이터 엔지니어링 사이를 이어주는 다리다.
5. 단순한 반복이 아니라, ‘의미 있는 반복 구조’를 만드는 것이 핵심이다.
-
while True로 무한 반복을 하되, 데이터가 없으면 종료, 있으면 수집 후 다음 페이지로 이동하는 흐름을 만들었다.
📌 이 개념이 말하는 것 👉 반복은 무조건 많이 하는 게 아니라, 조건에 따라 유연하게 움직이는 구조를 짜야 한다. 👉 이것이 바로 자동화 설계의 기초다.
✅ 마무리
오늘은 Pagination 개념과 함께, 여러 페이지에 걸쳐 있는 데이터를 자동으로 수집하는 방법을 실습해봤다. 단순히 한 페이지에서 원하는 정보를 긁어오는 걸 넘어서, 여러 페이지를 순회하며 수집하는 로직을 짠다는 건 ‘자동화의 시작’이기도 하다.
이제 우리는 단순한 크롤링을 넘어서,
✔️ 더 많은 데이터를
✔️ 안정적으로
✔️ 반복 없이 수집할 수 있는 기반을 갖추게 된 셈이다.
지금은 quotes.toscrape처럼 구조가 단순한 사이트였지만, 실제 서비스에서는 무한스크롤, 로그인, Ajax 등 다양한 요소들이 섞여 있을 수 있다.
그런 구조에 어떻게 대응할지는 앞으로 배워갈 중요한 포인트가 될 것이다.
🔜 다음 시간에는...
오늘은 페이지를 넘기며 정보를 수집하는 법을 배웠다면, 다음 시간에는 그 데이터를 어떻게 분석하고, 어떤 인사이트를 뽑아낼 수 있을지 함께 살펴보려 한다.
명언 데이터로 통계도 내보고, 그래프도 그리고, 워드클라우드도 한 번 만들어보자.
Pagination으로 수집한 데이터를 “단순한 문자열 모음”에서 “정보”로 바꾸는 과정을 함께 배워볼 예정이다.
