개요
데이터 엔지니어링은 크게 보면 "데이터를 모으고, 옮기고, 가공하는 일"이다. 이 중에서 ‘데이터를 모은다’는 건 어디에 있는 데이터를 내 손 안으로 가져오는 걸 말한다.
가장 기초적이고도 강력한 수단이 바로 웹 크롤링(Web Crawling)이다. API가 없는 웹사이트에서도, HTML 구조만 알면 원하는 데이터를 가져올 수 있기 때문이다.
오늘은 웹 크롤링의 기본 개념부터 간단한 실습까지 진행해보려고 한다.
🌐 웹 크롤링을 위한 서버-클라이언트 구조 이해
웹 크롤링을 하려면 단순히 코드를 짜는 것보다 먼저 웹이 어떻게 동작하는지 이해하는 게 중요하다. 다 알아가려고 하면 너무 많기 때문에 가장 핵심이 되는 개념인 클라이언트-서버 모델만 짚고 넘어가보자.
✅ 클라이언트(Client)란?
- 웹사이트에 접속하는 사람, 또는 프로그램 : 브라우저, 파이썬 코드 등
- 데이터를 "요청(Request)"하는 주체
✅ 서버(Server)란?
- 웹사이트를 실제로 운영하는 컴퓨터
- 요청을 받고, 처리해서 "응답(Response)"을 돌려주는 역할
✅ 크롤링은 어떤 과정인가?
- 내 컴퓨터(Python 코드)가 웹사이트 서버에 요청(Request)을 보내고,
- 그 결과로 돌아온 HTML 응답(Response)에서 내가 원하는 정보를 추출하는 과정이다.
- 즉, 웹 브라우저 대신에 Python 코드로 서버에 접근한다고 보면 된다.
1. 웹 크롤링의 전체 흐름
웹 크롤링은 다음과 같은 순서로 이루어진다.
1) 요청 (Request)
- 웹 페이지 주소(URL)에 접속 요청을 보냄
2) 응답 (Response)
- 서버가 HTML로 된 웹페이지를 반환
3) 파싱 (Parsing)
- HTML 문서에서 필요한 정보만 뽑아냄
4)저장 (Save)
- 수집한 데이터를 CSV/DB 등에 저장
2. 실습
웹 크롤링을 할 때는 Python의 기본 문법만으로는 부족하다. HTML을 받아오고, 구조를 파악하고, 데이터를 정리해서 저장하는 3단계 작업을 각각 도와주는 전용 도구들이 필요한데, 이걸 라이브러리라 부른다. 우리는 오늘 웹 크롤링 실습을 위해 beautifulsoup4, request, pandas 라이브러리를 설치하여 활용하고자 한다.
pip install requests beautifulsoup4 pandas
이 명령어는 아래 3개의 라이브러리를 설치해준다.
📦 requests: 웹사이트에 요청(Request) 보내기
-
역할
웹사이트 주소(URL)에 접속해서, HTML 코드를 가져오는 기능을 한다. 우리가 브라우저로 접속하듯이, Python 코드로 사이트에 접속하는 것이다. -
왜 필요한가?
웹 크롤링의 첫 단계는 웹 페이지로부터 데이터를 받아오는 것인데, 이걸 "request.get("URL")"한 줄로 딸깍할 수 있게 해준다는 것이다. -
예시코드 및 실행결과
import requests
res = requests.get("https://example.com")
print(res.text) # 웹페이지 HTML 코드 전체 출력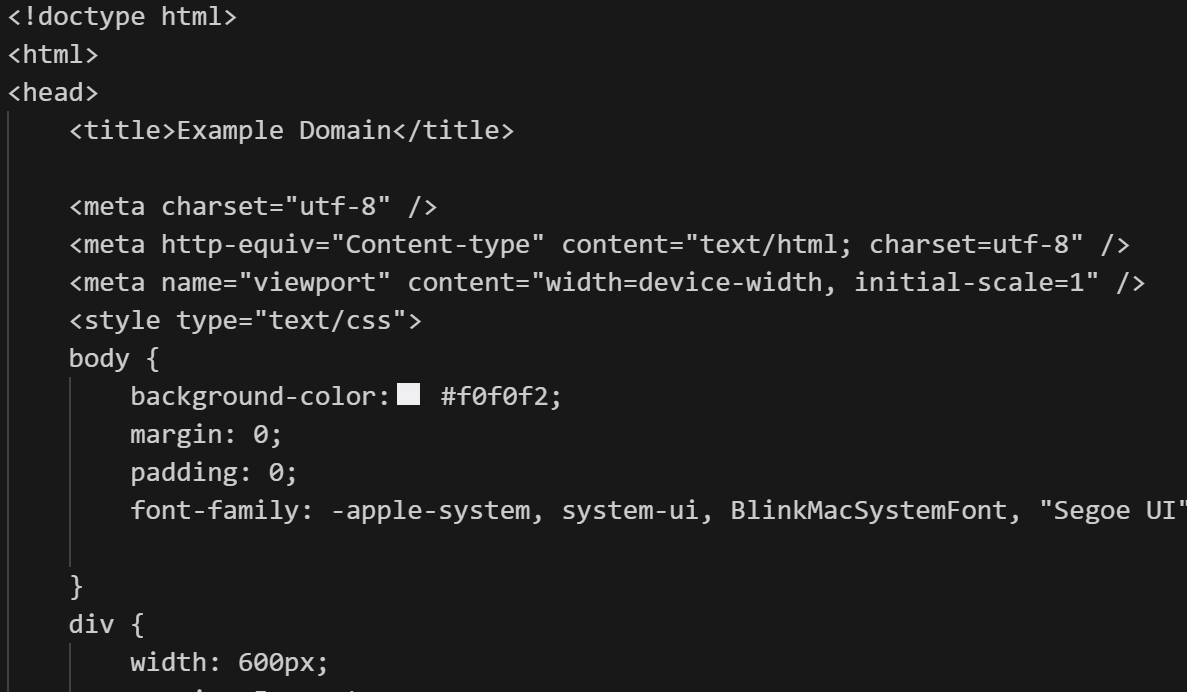
위 코드를 실행 시키키면 위 결과처럼 서버에서 HTML 코드를 반환해준다.
🥣 beautifulsoup4: HTML 문서를 분석해서 정보 추출
-
역할
가져온 HTML 문서에서 필요한 부분만 골라내는 파서(parser)를 사용할 수 있는 라이브러리다. 예를 들어, 뉴스 제목이나 상품 가격처럼 원하는 태그만 뽑아낼 수 있다. -
왜 필요한가?
HTML은 텍스트 덩어리라서 구조를 몰라선 아무것도 못한다. BeautifulSoup은 HTML을 트리 구조로 바꿔줘서 필요한 요소만 쉽게 선택할 수 있게 해준다. -
예시 코드 및 실행결과 : h1 태그 안의 텍스트들만 추출
#<h1>태그 안의 텍스트만 추출
soup = BeautifulSoup(res.text, "html.parser")
title = soup.select_one("h1").get_text()
print(title) 
📊 pandas: 수집한 데이터를 표 형태로 정리 & 저장
-
역할
크롤링한 데이터를 표처럼 정리하고, CSV, Excel 등으로 저장할 수 있게 해준다. 나중에 SQL이나 분석 툴로 넘길 때도 유용하다. -
왜 필요한가?
단순히 print()로 출력하는건 끝이 아니다. 우리가 뽑은 데이터를 정리해서 파일로 저장하고 가공하려면 pandas가 거의 필수이다. -
예시 코드 및 실행 결과
#python
import pandas as pd
data = [{"title": "기사1"}, {"title": "기사2"}]
df = pd.DataFrame(data)
df.to_csv("news.csv", index=False, encoding="utf-8-sig")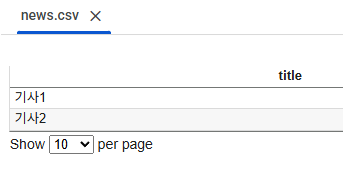
3. 정리
이번 실습에서는 웹 크롤링의 전체 흐름을 처음부터 끝까지 경험해봤다. 작업은 다음과 같은 순서로 진행되었다.
1️⃣ 웹사이트 요청
: request 라이브러리를 사용하여 웹페이지 HTML 문서를 가져옴.
2️⃣ HTML 파싱
: BeautifulSoup을 통해 HTML 구조를 분석하고, 필요한 정보(명언과 작가)를 선택적으로 추출했다.
3️⃣ 데이터 저장
: 추출한 정보를 pandas의 DataFrame으로 정리하고, CSV 파일로 저장했다.
4️⃣ 의의
오늘은 간단한 코드 몇 줄로 실제 웹사이트에서 정보를 수집해 저장하는 데이터 수집 파이프라인의 가장 기초적인 형태를 구현한 것이다.
다음 시간에는...
Pagination

2번 실습 쪽에서 오타났어용
“HTML을 받아오고, 구조를 파아하고”