Text Summarization ( 요약 )
- text가 주어졌을 때 주요 정보를 포함하는 요약문을 generate하는 task
- 종류
- Single-document summarization : 한 document를 요약
- Multi-document summarization : 여러 document의 정보를 통합해 하나로 요약
- 방식 ( How to generate summary )
- Extractive : 주어진 문장을 추출하여 요약 생성. 주로 pre-neural 시대에 사용. Restrictive ( no paraphrasing ). Easier
- 각각의 문장을 점수화하고 추출한 뒤 문장간의 관계를 모델링, 전체 document에서 몇개의 문장을 선택하여 추출하는 방식 - Abstractive : 새로운 요약 문장 생성. More Flexivle ( 사람과 비슷하게 ). More difficult
- Extractive : 주어진 문장을 추출하여 요약 생성. 주로 pre-neural 시대에 사용. Restrictive ( no paraphrasing ). Easier
- Application : 뉴스 요약
데이터 : CNN/DailyMail
-
CNN 뉴스 기사와 그 기사의 요약문으로 이루어져있다.
-
text 요약을 위한 dataset으로 Text 요약 ( Abstractive, Extractive ), QA, Text Generation 등의 task에 활용된다.
-
data field
- id : url을 SHA1 Hash한 것의 16진수 문자열
- article (document->feature) : news 기사의 본문
- highlights (summary->label) : 기사 작성자가 작성한 기사의 highlights
| column | 예시 |
|---|---|
| id | '0054d6d30dbcad772e20b22771153a2a9cbeaf62' |
| article | '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, the same ship on which 86 passengers previously fell ill, ...... The other passengers came down with diarrhea prior to her death during an earlier part of the trip, the ship's doctors said. The Veendam left New York 36 days ago for a South America tour.' |
| highlights | 'The elderly woman suffered from diabetes and hypertension, ship's doctors say. Previously, 86 passengers had fallen ill on the ship, Agencia Brasil says .' |
- 학습에 필요한 data인 article의 길이는 크게 길지 않은 문장으로 이루어져있다.
| 평균 | article | highlights |
|---|---|---|
| sentence | 29.74 문장 | 3.72문장 |
| word | 766 단어 | 53단어 |
| token | 781 | 56 |
- data size는 다음과 같다.
| train | validation | test | |
|---|---|---|---|
| data size | 286,817쌍 | 13,368쌍 | 11,487쌍 |
SOTA 모델
1. MatchSum : Extractive Summarization as Text Matching
1. Extractive Summarization
-
MatchSum이 나타난 배경
기존 모델은 의미적인 관계를 고려하지 않는 Setence-level에서 수행되었다. -
Setence-level이 아닌 Semantic Text matching을 통해 summary-level framework이다.
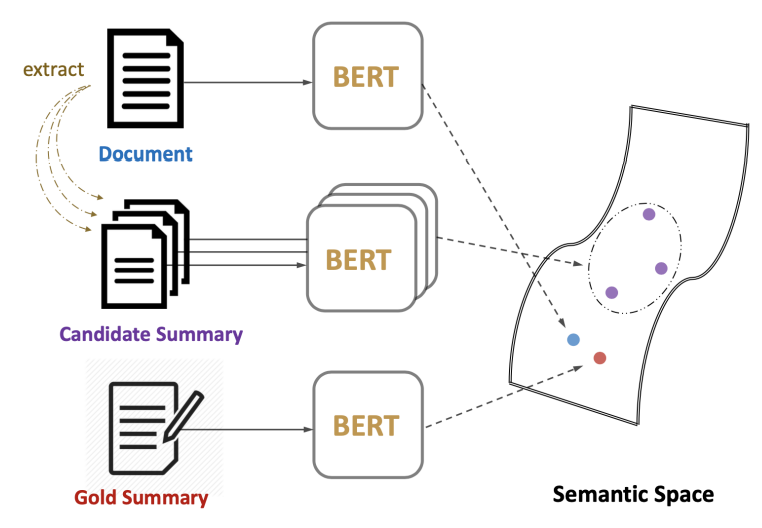
-
주요 개념과 키워드
- Semantic Text matching : source와 summary 사이의 의미적 유사도를 중점으로 학습한다.
- summary-level framework : document에서 후보 ( candidate ) summary를 추출한 뒤 BERT를 통해 document와 후보 summary weight를 transformer의 encoder layer에 공급, loss 함수를 통해 최적화한 뒤 유사도 측정하는 방법으로 최종 요약문(Best-summary) 완성
- Pearl-summary : Sentence-level score는 낮지만 summary-level score는 높은 summary를 의미
=> Pearl-summary일 경우 sentence-level summarizer가 최적의 요약문을 추출하기는 어려움 - Best-summary : 모든 candidate summary들 중에서 가장 summary level 점수가 높은 summary를 의미
- Pearl-summary : Sentence-level score는 낮지만 summary-level score는 높은 summary를 의미
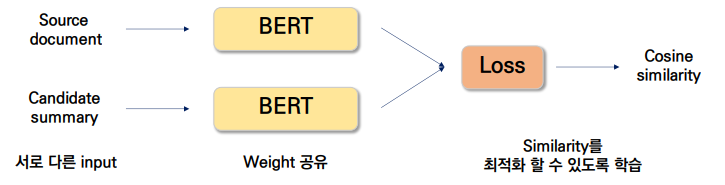
- Siamese-Bert를 제안하여 similarity를 학습할 수 있도록 모델을 구성함
- Loss function : 각각의 Loss function을 적용한 뒤 합함
- loss 1 : golden summary는 source document와 semantically closet 해야함
- loss 2 : Candidate ranking이 큰 candidate summary의 margin이 크도록 학습함
- Loss function : 각각의 Loss function을 적용한 뒤 합함
- Candidate Pruning : Content selection을 이용해 candidate pruning을 진행하며, 이때 BERTSUM 모델을 사용함
2. BERTSumExt : Text Summarization with Pretrained Encoders
- 각 문장을 요약문에 포함시킬지를 나타낸다.
- BERT의 결과인 문장 표현을 transformer의 encoder layer에 공급한다.
- output layer는 sigmoid classifier로 문장을 요약에 포함시킬지 여부의 확률을 얻는다.
- 평가 지표 : ROUGE
1. Extractive Summarization => BERTSumExt
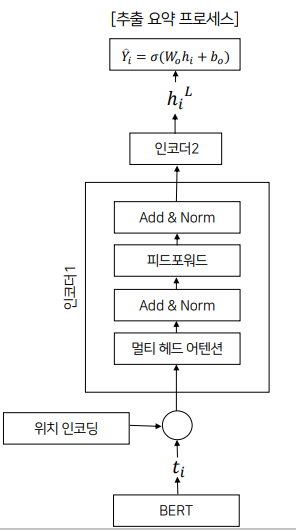
- input : BERT로부터 나온 문장의 표현
- 위치 인코딩을 해준 후, 트랜스포머의 인코더에 입력
- 주요 개념과 키워드
- Pretrained Language model
- contextual representation
- BERT
- positional embedding 최대 길이 : 무작위로 초기화 ( BERT는 512 )
2. Abstractive Summarization => BERTSumAbs
- stardard encoder-decoder framework
- encoder : pretrained BERTSUM으로 의미있는 표현을 생성한다. pretrained 되어있기 때문에 과적합될 수 있다.
- decoder : 무작위로 초기화된 6-layered transformer로 정의, 이 표현을 사용해 summary을 생성하는 방법을 학습한다. 무작위로 초기화되어있기 때문에 과소적합이 발생할 수 있다.
- 해결 : adam optimizer 2개를 사용 == 서로 다른 학습률 적용
3. Two-stage fine-tuning approach => BERTSumExtAbs
- Extractive Summarization task에서 encoder를 먼저 fine-tuning
- Abstractive Summarization task에서 fine-tuning
=> architecture의 변화없이 두 task간의 공유되는 정보를 활용할 수 있다는 장점
BERTSumAbs보다 BERTSumExtAbs의 성능이 일반적으로 더 뛰어나다.
참조

키워드에대한 설명 대단해요. 저는 맥락설명만 하고 각 중요한 용어들에대한 정리는 미뤘거든요.