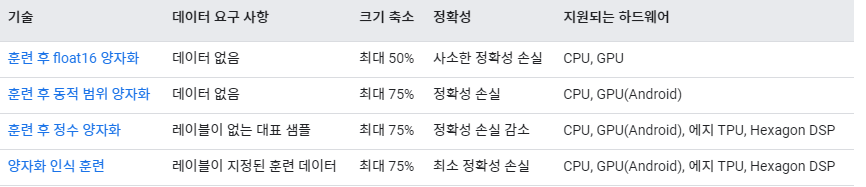
양자화는 float타입인 Tensor 가중치와 활성화 함수를 int형으로 변환하여 모델의 크기를 줄이고 추론(test) 속도를 높이는 방법이다.
보통 float32 대신 int8을 쓰면 model size는 1/4가 되고, 추론 속도는 2~4배 빨라지며 memory bandwidth도 2~4배 가벼워진다.(bit수를 N배 줄이면 곱셈 복잡도는 NxN 줄어듬)
요약
- float -> int
- 모델의 크기 ↓, 속도 ↑(빠르게), 성능(loss)은 그대로
- Inference(추론) 시간을 줄이기 위한 것이다.+
양자화 기법 분류
- Post Training Quantization 방식 : Training된 모델(Post Training)을 Quantization
- Dynamic Quantization, Static Quantization
- 장점 : parameter size가 큰 대형 모델에 대해서 정확도 하락의 폭이 작다
- 단점 : parameter size가 작은 소형 모델에 대해서 정확도 하락의 폭이 크다
- Edge device 등이 작은 소형 모델과 경량화를 주로 사용하여 PTQ를 이용하면 좋은 성능을 기대하기 어렵다.
- 학습 중 Quantization 수행 : 모델이 실제로는 float 계산을 하지만, 이후 양자화될 것이라고 자각한 채로 훈련이 이루어진다. Fake Quantization node를 통해 양자화시 어떻게 동작할 지 시뮬레이션.
- Quantization Aware Training
- 장점 : 일반적으로 가장 높은 정확도를 가진다. 모델의 정확도 감소 폭을 최소화할 수 있다.(소형 모델에서 QAT가 필수적이다.)
- 단점 : 모델 학습 이후 추가 연산(양자화)이 필요하다.
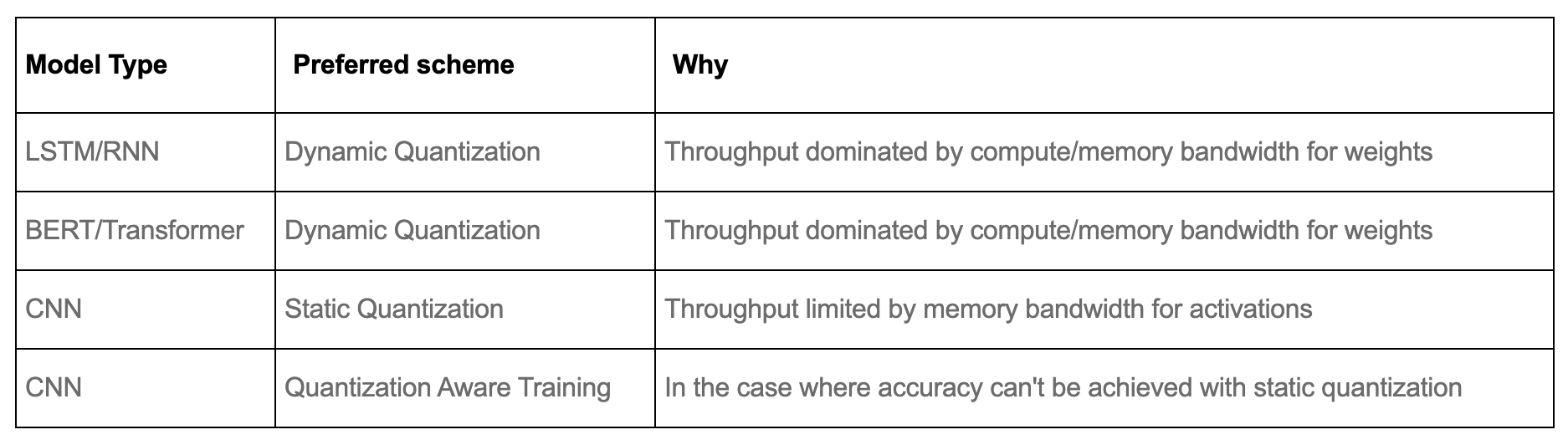
모델별 양자화 기법 선정
Quantization 순서
딥러닝의 Quantization (양자화)와 Quantization Aware Training, JINSOL KIM
- (option)Module Fusion : layer을 하나로 묶는 단계. 대표적 예시로 Conv-BatchNorm-ReLU를 묶어 각각 양자화(3번)하지 않고 ReLU 후(1번) 양자화하는 방식이다. 필요시에만 사용한다.
- Quantization 변환식(Quantization mapping) 정의. dequantization(int -> float)도 가능
- HW Deployment : 하드웨어에 따라 교정하는 단계. intel or ARM
- Dataset 교정 : weight를 변환하는 식의 파라미터를 Dataset을 이용하여 계산
- Weight 변환 : float -> int
- (option)Dequantization : 필요시 추론을 통해 얻은 출력을 역양자화를 통해 다시 float 타입으로 변환(일부 loss될 수 있다)
Dynamic Quantization (동적 양자화)
Post Training Quantization 방식으로 가장 간단한 양자화 방법이다.
pytorch 튜토리얼의 LSTM 기반 단어 단위 언어 모델의 동적 양자화에선 동적 양자화를 적용하여 기존 모델과 비교하였다.
git에 copy한 pytorch 튜토리얼 동적 양자화
- 학습된 모델에 동적 양자화를 적용하는 코드
docs : torch.quantization.quantize_dynamic docs
import torch.quantization
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.LSTM, nn.Linear}, dtype=torch.qint8
) # LSTM과 Linear에 동적 양자화 적용됨달라지는 부분 : 명시한 layer의 타입이 달라진다(양자화 적용할 layer)
- rnn(lstm) : LSTM -> DynamicQuantizedLSTM
- decoder(linear) : LSTM -> DynamicQuantizedLSTM(..dtype=torch.qint8, qscheme=torch.per_tensor_affine)
Size(149->114), time(211->100)은 줄어들었고, loss는 같았다(근사하다).

- float 모델을 동적(가중치만) 양자화된 모델로 변환한다.
- 특정 모듈(명시한 모듈)을 양자화 버전과 결과값을 가지는 양자화 모델로 대체한다.
- 가장 간단한 사용법은 float16을 qint8이 되도록 변형하는 것이다. 이것은 보통 가중치 크기가 큰 레이어에 대해 수행된다.
- 파라미터인 qconfig및 mapping으로 세밀한 제어도 가능하다.
Static Quantization (정적 양자화)
PYTORCH에서 EAGER MODE를 이용한 정적 양자화, pytorch 튜토리얼
딥러닝 Quantization(양자화) 정리
# 아래 Quantization Aware Training에서도 이 클래스 사용
class CustomModel(nn.Module) :
def __init__(self) :
self.Quantizer = torch.quantization.QuantStub()
...
self.dequantizer = torch.quantization.DeQuantStub()
def forward(self, x) :
x = self.Quantizer(x)
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x) # conv, batchnorm, relu fuse할 예정
x = self.dequantizer(x)
return x
model_float32 = CustomModel()model_float32.eval() # 평가모드
model_float32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_float32 = torch.quantization.fuse_modules(model_float32, [['conv', 'batchnorm', 'relu']])
model_float32_prepared = torch.quantization.prepare(model_float32_fused)
model_float32_prepared(input_float32) # 실제 dataset으로 파라미터 교정
model_int8 = torch.quantization.convert(model_float32_prepared)
res = model_int8(input_float32) # 추론Quantization Aware Training
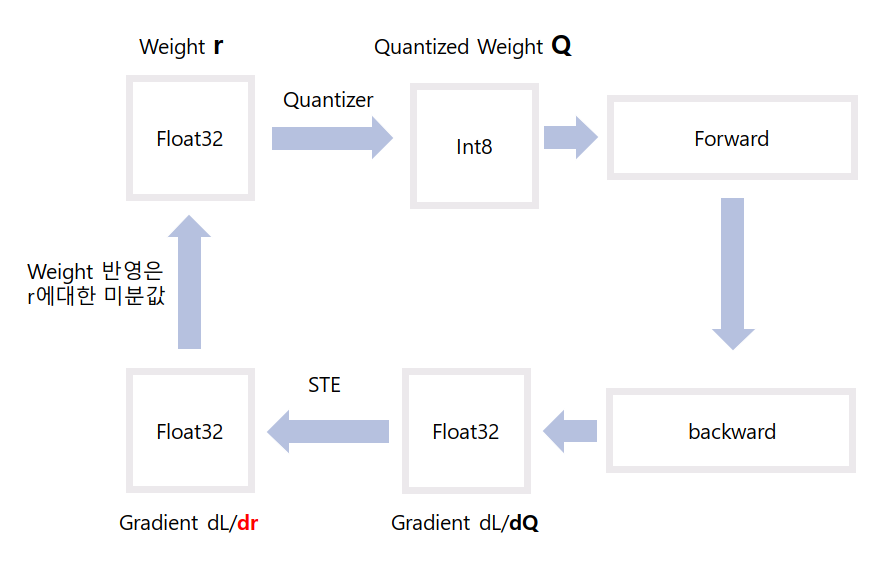
model 내부 동작 => fine-tuning과 비슷하다.
1. Weight r에 대해 Quantizer => Quantized Weight Q
2. Q로 Forward
3. Backward
4. gradient dL/dQ에서 STE하여 r 구하기(r의 일부 loss될 수 있다.)
5. gradient dL/dr의 값을 weight r에 적용(더하기)
# 훈련모드
model_float32.train() # 훈련 중 양자화 적용
model_float32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model_float32_fused = torch.quantization.fuse_modules(model_float32, [['conv', 'batchnorm', 'relu']])
# fake quantization 삽입한 QAT 모델
model_float32_prepared = torch.quantization.prepare_qat(model_float32_fused) # 정적양자화랑 다른 부분
training_loop(model_float32_prepared)
# 평가모드
model_float32_prepared.eval()
model_int8 = torch.quantization.convert(model_float32_prepared) # 양자화한 모델로 변환
# run the model, relevant calculations will happen in int8
res = model_int8(input_float32)pytorch 튜토리얼 바로가기 : 컴퓨터 비전 튜토리얼을 위한 양자화된 전이학습
아래 코드 확인 가능
- 양자화된 특징 추출기(Quantized Feature Extractor)를 기반으로Classifier 훈련하기
- 양자화 가능한 모델 미세조정(Finetuning)
참조
코드, 모델별 양자화 기법 선정 딥러닝 Quantization(양자화) 정리
