tensorflow Lite<가이드<모델 최적화<개요
머신러닝 모델 최적화, tensorflow
모델의 파라미터 수도 많고, 연산량이 많으면 특징 추출하기 용이하고 결과값도 좋을 것이다.
하지만 mobile 환경이나 IoT, Embedded환경과 같이 속도, 배터리, Memory 등이 중요한 환경이라면 파라미터 수가 적고 연산량이 적지만 성능은 비슷한 작은 모델을 원할 것이다.
그래서 최적화가 필요하다.
- 모델을 최적화해야하는 이유
- 모델의 크기를 줄일 수 있다 -> 모델의 크기, RAM 사용량 감소
- 추론 시간 감소 -> 계산을 단순화하여 잠재적 정확성을 떨어뜨리는 방식으로 줄임(특정 모델은 최적화 프로세스로 인해 오히려 정확성이 개선될 수도 있다.) -> 전력 소비 감소
- 최적화 유형
- 양자화 : 32bit 부동 소수점 숫자인 모델의 매개변수(float32)를 나타내는 데 사용되는 숫자의 정밀도를 줄여서(float -> int) 동작
- Pruning, 잘라내기(가지치기) : 예측에 미미한 영향만 미치는 모델 내 매개변수를 제거
- 클러스터링 : 각 레이어의 가중치를 그룹화 -> 각 클러스터 내 가중치의 중심 값을 공유 -> 고유한 가중치 값의 수 줄이기 == 잘라내기와 유사
- 모델의 크기를 더 줄이기 위해 잘라내기/클러스터링 후 양자화할 수 있다.
Quantization (양자화)
자세한 Quantization는 여기에 정리했습니다.
양자화는 float타입인 Tensor 가중치와 활성화 함수를 int형으로 변환하여 모델의 크기를 줄이고 추론(test) 속도를 높이는 방법이다.
- float -> int
- 모델의 크기 ↓, 속도 ↑(빠르게), 성능(loss)은 그대로

Pruning (가지치기)
모델 경량화 1 - Pruning(가지치기), 욕심많은 알파카
가지치기 기법(PRUNING) 튜토리얼(코드)
- 가중치를 두어서 value에 반영하는 것(중요하지 않은 것은 덜 반영하는 것을 의미한다.)
- NN뿐만 아니라 DT(Decision tree)에서도 많이 사용되는 방법이다.
- torch에서는 torch.nn.utils.prune 모듈을 활용하거나 직접 BasePruningMethod 서브 클래스를 구현한다.
prune.random_unstructured(module, name="weight", amount=0.3) - 가지치기 기법은 파이토치의 forward_pre_hooks 를 이용하여 각 순전파가 진행되기 전에 가지치기 기법이 적용되며, 각 파라미터값들이 forward_pre_hook를 얻게된다.
- 편향값에 대해서도 가지치기할 수 있다.(아래는 L1 Norm 값이 가장 작은 편향값 3개를 가지치기를 시도)
prune.l1_unstructured(module, name="bias", amount=3)
Knowledge distillation (지식 증류)
참고 : 딥러닝 용어 정리, Knowledge distillation 설명과 이해, 빛나는나무
Introduction to knowledge distillation
Knowledge distillation : 큰 네트워크(Teacher Model)의 지식을 실제로 사용하고자 하는 작은 네트워크(Student Model)에게 전달하는 방식을 통해 경량화를 이루는 것이 이 방법론의 목적이다.
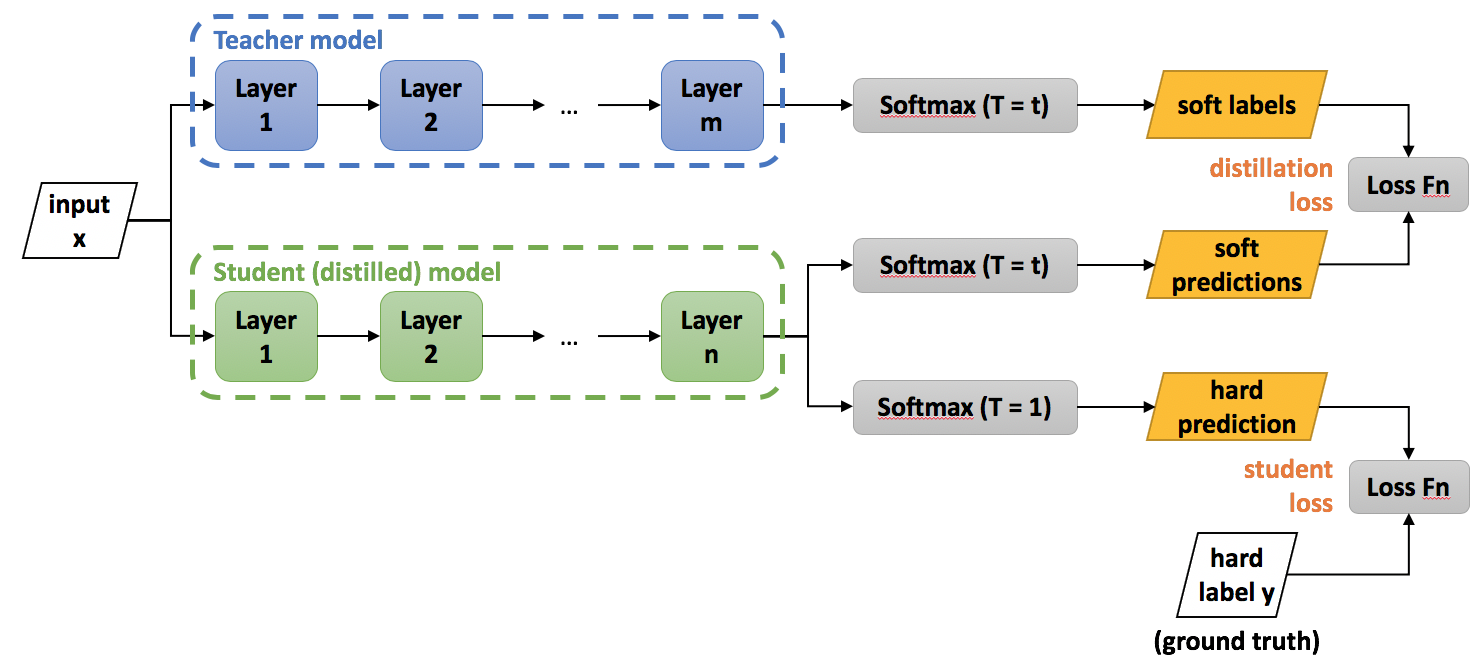
- hard target : 분류의 경우 정답/오답의 값을 가지는 값(label과 같은 값)
- soft target : 예측결과의 확률분포(0.8, 0.11, 0.09,...)
위의 설계도처럼, Teacher Model의 결과를 Student Model의 결과와 비교시켜서 Student가 Teacher을 모방하도록 유도한다(학습시킨다).
어떤 지식을 넘길 것인가에 대한 논의도 있었다.
- Response - Based knowledge
- Feature - Based knowledge
- Activation Boundary를 가져와야 한다는 주장 => 좋은 일반화 성능을 가져올 것이다.
- Relation - Based knowledge
