- 사용 환경 : Google Colab
- 언어 : Python, Pytorch
- validation accuracy : 0.9902
- Dataset : KorQuAD 1.0 ( train - 60407 rows, validation - 5774 rows)


- 기존에 pre-training된 모델을 가져와서 결과값을 도출하는 과정
- fine-tuning하지 않았다.
- BertForQuestionAnswering(transformers 패키지에 구현된 클래스)로 해당 데이터셋을 추가하여 fine-tuning
-
평가지표 : F1, exact match(EM), accuracy(KorQuAD 1.0에서 요구하는 평가지표 : EM, F1)
-
Dataset
- context 길이 : 348 ~ 10012글자
- 실제 훈련에 들어가는 context는 길이를 512 이하로 자르되, question을 포함하도록 하였다.
- question 길이 : 5 ~ 146 ( 가장 긴 질문인 146글자를 tokenize했을 때 78 tokens가 됨 )
- context에 question을 이어붙여 예측하기 때문에 context tokens + question tokens가 512 이하여야 한다. 길이 주의
- answer 길이 : 1670 ~ 10005
- context 길이 : 348 ~ 10012글자
-
preprocessing 결과
- input : (question + context)인 tensor, token이 512 이하가 되도록 context를 전처리하여 사용
- output : input과 같은 길이의 tensor. input의 위치 중 answer이 위치하는 id 위치만 1로 나타냈다.
-
Model :
klue/bert-base를 fine-tuning 하여 사용
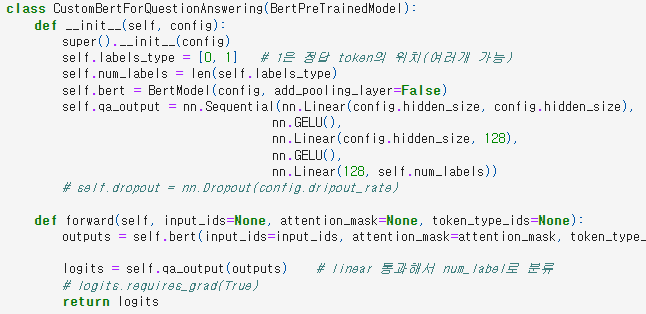
-
context에서 정답인 부분을 1로 하여 정답 위치 찾기
-
고려해야할 점
- 전처리 시 'UNK'부분을 삭제할 것인가?
- 삭제 x : answer text에도 'UNK'가 있었다. 만약 삭제한다면 answer text도 삭제해야한다.(answer start_idx도 조정 필요)
- context + question이 512 tokens 이상인 경우 어떻게 해결할 것인가?
- 원문의 길이의 max, min, mean값을 통해 분석. => tokenizing한 후 token의 길이는 대략 원문의 1/2다.
- answer이 위치하지 않는 context를 자른다.
- 원문을 마침표를 기준으로 나눈 뒤, answer이 가운데로 오도록 앞, 뒤 문장을 잘랐다.
- tokenize한 뒤 자르면 resource가 너무 많이 들고, answer의 위치를 정확하게 파악하기 힘들다.(answer 이전까지의 문장, answer의 문장, answer 이후의 문장으로 tokenizing을 3번 해야한다.)
- UNK 제거 -> answer의 idx가 달라지기 때문에 제거하면 안된다.
- layer을 추가로 쌓을 필요가 있는가? => classifier로 간단하게 출력값을 도출한 뒤, 성능을 보고 비교해보자.
- pre-trined 모델을 무엇으로 할 것인가? => QA task에 fine-tuning되지 않은 klue의 baseline인 klue-bert-base로 시도
- answer을 어떻게 나타낼 것인가?
- answer token의 시작과 끝 idx
- input tensor와 같은 크기의 tensor지만, answer token의 위치만 1로 표시 <- 이 방식으로 시도
- 전처리 시 'UNK'부분을 삭제할 것인가?
-
결과
- 1 epoch 때 Validation 성능 값 : Loss : 0.0103 / f1 : 0.9902 / em : 0.0000 / acc : 0.9902
-
이후 확인해야할 점
- 추가 layer와 classifier은 적절히 사용되었는가? => 성능으로 판단(아직 x)
- train의 f1-score은 0.5에 근사한 반면에 validation f1은 0.99이다.
- 데이터 누수? x ( train dataset과 validation dataset이 따로 존재)
- context + question의 길이의 문제? => input의 context에 answer의 모든 tokens이 들어가지 않았을 가능성 있다.(question이 너무 길거나 원문 split를 잘못 했다면 가능하다.)
